Exploración del procesamiento de datos analíticos
Normalmente, el procesamiento de datos analíticos usa sistemas de solo lectura (o principalmente de lectura) que almacenan grandes volúmenes de datos históricos o métricas empresariales. Los análisis pueden basarse en una instantánea de los datos en un momento concreto o en una serie de instantáneas.
Los detalles específicos de un sistema de procesamiento analítico pueden variar según la solución, pero una arquitectura común para el análisis a escala empresarial tiene el siguiente aspecto:
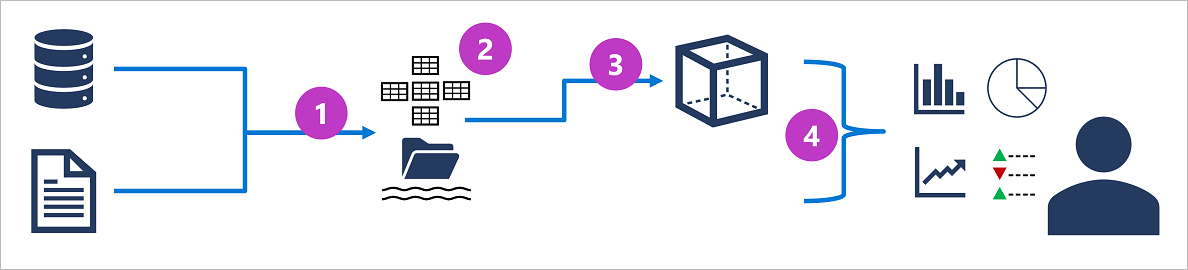
- Los datos operativos se extraen, transforman y cargan (ETL) en un lago de datos para su análisis.
- Los datos se cargan en un esquema de tablas: normalmente en un almacén de lago de datos basado en Spark con abstracciones tabulares en los archivos del lago de datos o en un almacenamiento de datos con un motor SQL totalmente relacional.
- Los datos del almacenamiento de datos se pueden agregar y cargar en un modelo de procesamiento analítico en línea (OLAP) o un cubo. Los valores numéricos agregados (medidas) de las tablas de hechos se calculan para intersecciones de dimensiones a partir de tablas de dimensiones. Por ejemplo, los ingresos de ventas podrían sumarse por fecha, cliente y producto.
- Los datos del lago de datos, el almacenamiento de datos y el modelo analítico se pueden consultar para generar informes, visualizaciones y paneles.
Los lagos de datos son comunes en escenarios de procesamiento analítico de datos modernos, en los que se debe recopilar y analizar un gran volumen de datos basados en archivos.
Los almacenamientos de datos son un recurso establecido para almacenar datos en un esquema relacional optimizado para operaciones de lectura, principalmente consultas para admitir informes y visualización de datos. Los almacenes de lago de datos son una innovación más reciente que combina el almacenamiento flexible y escalable de un lago de datos con la semántica de consulta relacional de un almacenamiento de datos. El esquema de tabla puede requerir cierta desnormalización de datos en un origen de datos OLTP (introduciendo algunas duplicaciones para que las consultas funcionen más rápido).
Un modelo OLAP es un tipo agregado de almacenamiento de datos optimizado para cargas de trabajo analíticas. Las agregaciones de datos se encuentran en diferentes dimensiones y distintos niveles, lo que permite rastrear agrupando datos y explorar en profundidad las agregaciones en varios niveles jerárquicos; por ejemplo, para buscar el total de ventas por región, por ciudad o por una dirección individual. Dado que los datos de OLAP se agregan previamente, las consultas para devolver los resúmenes que contiene se pueden ejecutar rápidamente.
Los diferentes tipos de usuario pueden llevar a cabo el trabajo analítico de datos en distintas fases de la arquitectura general. Por ejemplo:
- Los científicos de datos pueden trabajar directamente con archivos de datos en un lago de datos para explorar los datos y crear modelos a partir de estos.
- Los analistas de datos pueden consultar tablas directamente en el almacenamiento de datos para generar informes y visualizaciones complejos.
- Los usuarios profesionales pueden consumir datos agregados previamente en un modelo analítico como informes o paneles.