Exploración de canalizaciones de ingesta de datos
Ahora que comprende un poco la arquitectura de una solución de almacenamiento de datos a gran escala y algunas de las tecnologías de procesamiento distribuido que se pueden usar para controlar grandes volúmenes de datos, es el momento de explorar cómo se ingieren los datos en un almacén de datos analíticos de uno o varios orígenes.
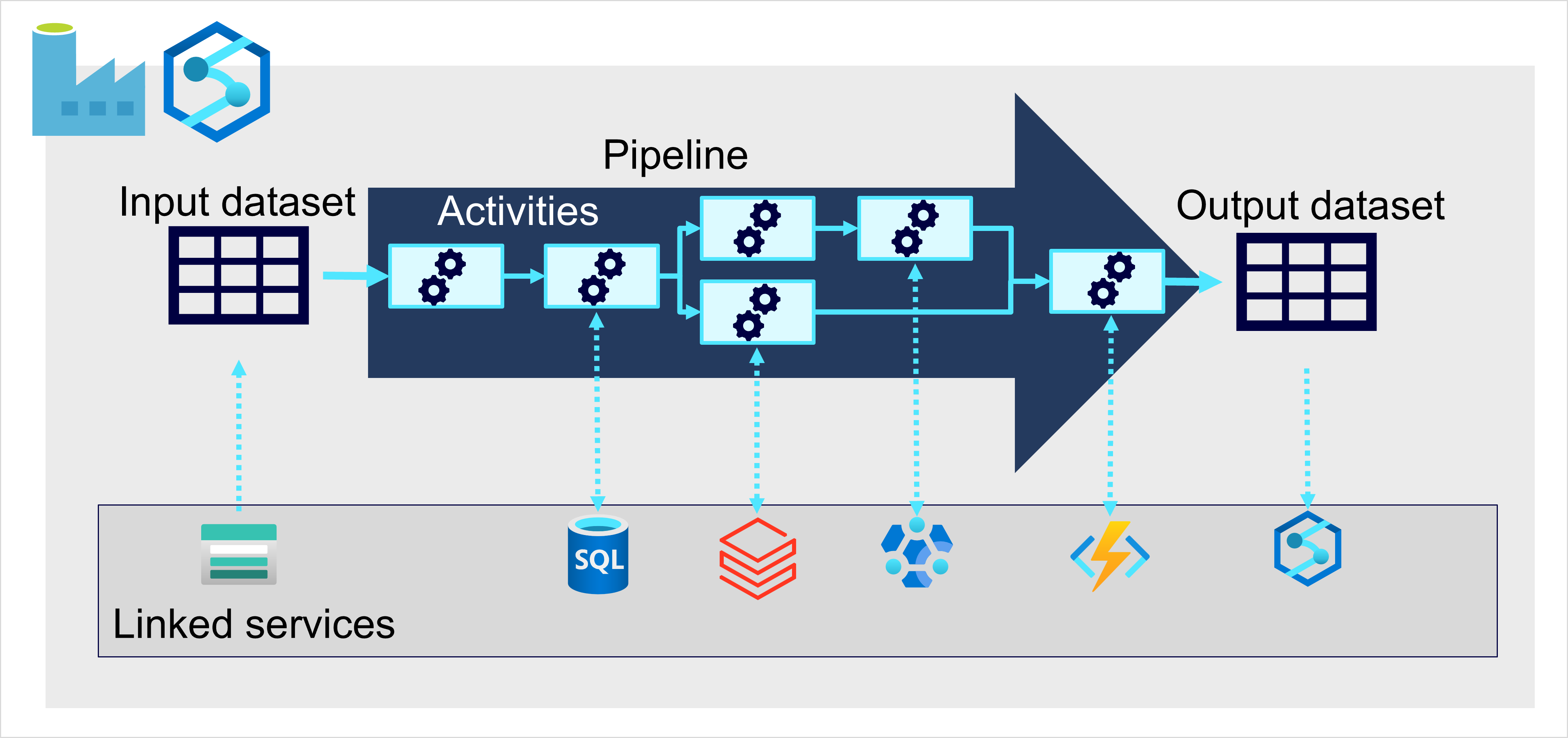
En Azure, la ingesta de datos a gran escala se implementa mejor mediante la creación de canalizaciones que organicen procesos de ETL. Puede crear y ejecutar canalizaciones mediante Azure Data Factory, o puede usar el mismo motor de canalización en Azure Data Factory si quiere administrar todos los componentes de la solución de almacenamiento de datos en un área de trabajo unificada.
En cualquier caso, las canalizaciones constan de una o varias actividades que operan en los datos. Un conjunto de datos de entrada proporciona los datos de origen y las actividades se pueden definir como un flujo de datos que manipula incrementalmente los datos hasta que se genera un conjunto de datos de salida. Las canalizaciones utilizan servicios vinculados para cargar y procesar datos, y esto le permite usar la tecnología adecuada para cada paso del flujo de trabajo. Por ejemplo, puede usar un servicio vinculado de Azure Blob Store para ingerir el conjunto de datos de entrada y después usar servicios como Azure SQL Database para ejecutar un procedimiento almacenado que busque valores de datos relacionados, antes de ejecutar una tarea de procesamiento de datos en Azure Databricks o aplicar lógica personalizada mediante una función de Azure. Por último, puede guardar el conjunto de datos de salida en un servicio vinculado, como Microsoft Fabric. Las canalizaciones también pueden incluir algunas actividades integradas, que no requieren un servicio vinculado.