Recopilación, consulta y visualización de estados de mantenimiento
Para representar con precisión un modelo de estado, debe recopilar varios conjuntos de datos del sistema. Los conjuntos de datos incluyen registros y métricas de rendimiento de los componentes de la aplicación y los recursos subyacentes de Azure. Es importante correlacionar los datos entre los conjuntos de datos para crear una representación en capas del estado del sistema.
Instrumentación de código e infraestructura
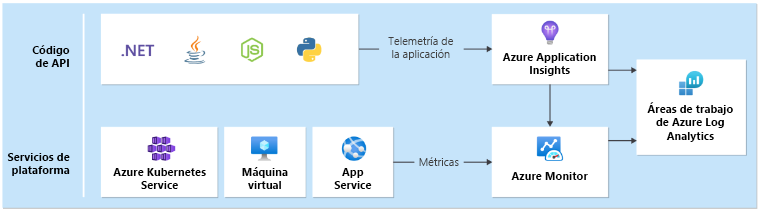
Se requiere un receptor de datos unificado para asegurarse de que todos los datos operativos se almacenan y están disponibles en una sola ubicación donde se recopilan todos los datos de telemetría. Por ejemplo, cuando un empleado crea un comentario en su explorador web, puede realizar un seguimiento de esta operación y ver que la solicitud pasó por la API de catálogo a Azure Event Hubs. Desde allí, el procesador en segundo plano ha recogido el comentario y lo almacena en Azure Cosmos DB.
Log Analytics de Azure Monitor actúa como el principal receptor nativo unificado de datos de Azure para almacenar y analizar datos operativos:
Application Insights es la herramienta de supervisión del rendimiento de aplicaciones (APM) recomendada en todos los componentes de la aplicación para recopilar registros de aplicaciones, métricas y seguimientos. Application Insights se implementa en una configuración basada en áreas de trabajo en cada región.
En la aplicación de ejemplo, Azure Functions se usa en Microsoft .NET 6 para sus servicios back-end para la integración nativa. Dado que las aplicaciones de back-end ya existen, Contoso Shoes crea solo un nuevo recurso de Application Insights en Azure y configura el valor
APPLICATIONINSIGHTS_CONNECTION_STRINGen ambas aplicaciones de funciones. El entorno de ejecución de Azure Functions registra automáticamente el proveedor de registro de Application Insights, por lo que la telemetría aparece en Azure sin tener que realizar ningún trabajo adicional. Para obtener un registro más personalizado, puede usar la interfazILogger.El conjunto de datos centralizado es un antipatrón para cargas de trabajo críticas. Cada región debe tener su área de trabajo dedicada de Log Analytics y una instancia de Application Insights. En el caso de los recursos globales, se recomiendan instancias independientes. Para ver el patrón de arquitectura básica, consulte Patrón de arquitectura para cargas de trabajo críticas en Azure.
Cada capa debe enviar datos al mismo área de trabajo de Log Analytics para facilitar los cálculos de análisis y estado.
Consultas de seguimiento de estado
Log Analytics, Application Insights y Azure Data Explorer usan el Lenguaje de consulta Kusto (KQL) para sus consultas. Puede usar KQL para crear consultas y usar funciones para capturar métricas y calcular puntuaciones de estado.
Para los servicios individuales que calculan el estado de mantenimiento, vea las siguientes consultas de ejemplo.
API de catálogo
En el ejemplo siguiente se muestra una consulta de API de catálogo:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 10, 50, // Failed requests, anything non-200, allow a few more than 0 for user-caused errors like 404s
"avgProcessingTime", 150, 500 // Average duration of the request, in ms
];
// Calculate average processing time for each request
let avgProcessingTime = AppRequests
| where AppRoleName startswith "CatalogService"
| where OperationName != "GET /health/liveness" // Liveness requests don't do any processing, including them would skew the results
| make-series Value = avg(DurationMs) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'avgProcessingTime';
// Calculate failed requests
let failureCount = AppRequests
| where AppRoleName startswith "CatalogService" // Liveness requests don't do any processing, including them would skew the results
| where OperationName != "GET /health/liveness"
| make-series Value=countif(Success != true) default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName= 'failureCount';
// Union all together and join with the thresholds
avgProcessingTime
| union failureCount
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
| project-reorder TimeGenerated, MetricName, Value, IsYellow, IsRed, YellowThreshold, RedThreshold
| extend ComponentName="CatalogService"
Azure Key Vault
En el ejemplo siguiente se muestra una consulta de Azure Key Vault:
let _maxAge = 2d; // Include data only from the last two days
let _timespanStart = ago(_maxAge); // Start time for the time span
let _timespanEnd = now(-2m); // Account for ingestion lag by stripping the last 2m
// For time frame, compare the averages to the following threshold values
let Thresholds = datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
"failureCount", 3, 10 // Failure count on key vault requests
];
let failureStats = AzureDiagnostics
| where TimeGenerated > _timespanStart
| where ResourceProvider == "MICROSOFT.KEYVAULT"
// Ignore authentication operations that have a 401. This is normal when using Key Vault SDK. First an unauthenticated request is made, then the response is used for authentication
| where Category=="AuditEvent" and not (OperationName == "Authentication" and httpStatusCode_d == 401)
| where OperationName in ('SecretGet','SecretList','VaultGet') or '*' in ('SecretGet','SecretList','VaultGet')
// Exclude Not Found responses because these happen regularly during 'Terraform plan' operations, when Terraform checks for the existence of secrets
| where ResultSignature != "Not Found"
// Create ResultStatus with all the 'success' results bucketed as 'Success'
// Certain operations like StorageAccountAutoSyncKey have no ResultSignature; for now, also set to 'Success'
| extend ResultStatus = case ( ResultSignature == "", "Success",
ResultSignature == "OK", "Success",
ResultSignature == "Accepted", "Success",
ResultSignature);
failureStats
| make-series Value=countif(ResultStatus != "Success") default=0 on TimeGenerated from _timespanStart to _timespanEnd step 1m
| mv-expand TimeGenerated, Value
| extend TimeGenerated = todatetime(TimeGenerated), Value=toreal(Value), MetricName="failureCount", ComponentName="Keyvault"
| lookup kind = inner Thresholds on MetricName
| extend IsYellow = iff(todouble(Value) > YellowThreshold and todouble(Value) < RedThreshold, 1, 0)
| extend IsRed = iff(todouble(Value) > RedThreshold, 1, 0)
Puntuación de estado del servicio de catálogo
Al final, puede unir varias consultas de estado de mantenimiento para calcular una puntuación de estado de un componente. En la consulta de ejemplo siguiente se muestra cómo calcular una puntuación de estado del servicio de catálogo:
CatalogServiceHealthStatus()
| union AksClusterHealthStatus()
| union KeyvaultHealthStatus()
| union EventHubHealthStatus()
| where TimeGenerated < ago(2m)
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed) by bin(TimeGenerated, 2m)
| extend HealthScore = 1 - (YellowScore * 0.25) - (RedScore * 0.5)
| extend ComponentName = "CatalogService", Dependencies="AKSCluster,Keyvault,EventHub" // These values are added to build the dependency visualization
| order by TimeGenerated desc
Sugerencia
Consulte más ejemplos de consultas en el repositorio de GitHub de Azure Mission-Critical Online.
Configuración de alertas basadas en consultas
Las alertas generan atención inmediata a los problemas que reflejan o afectan al estado de mantenimiento. Siempre que haya un cambio en el estado de mantenimiento, ya sea en un estado degradado (amarillo) o en un estado incorrecto (rojo), las notificaciones deben enviarse al equipo responsable. Establezca alertas en el nodo raíz del modelo de estado para que conozca inmediatamente cualquier cambio de nivel empresarial en el estado de mantenimiento de la solución. A continuación, puede ver las visualizaciones del modelo de estado para obtener más información y solucionar problemas.
En el ejemplo se usan alertas de Azure Monitor para impulsar acciones automatizadas en respuesta a los cambios en el estado de mantenimiento de la aplicación.
Uso de paneles para la visualización
Es importante visualizar el modelo de estado para que pueda comprender rápidamente el efecto de una interrupción de componentes en todo el sistema. El objetivo final de un modelo de estado es facilitar el diagnóstico rápido proporcionando una vista con información de las desviaciones de un estado estable.
Una manera común de visualizar la información de estado del sistema es combinar una vista de modelo de estado por capas con funcionalidades de exploración en profundidad de telemetría en un panel.
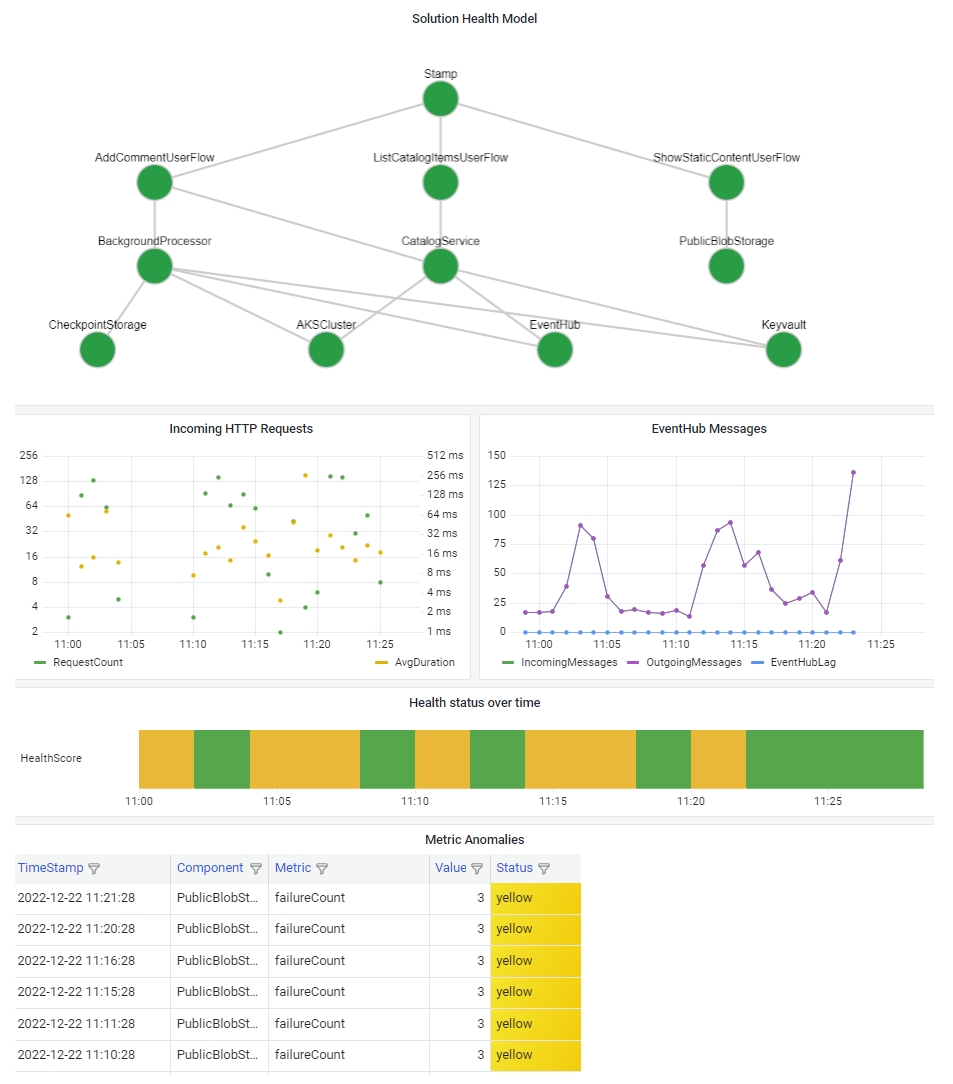
La tecnología del panel debe ser capaz de representar el modelo de estado. Entre las opciones más populares se incluyen los paneles de Azure, Power BI y Azure Managed Grafana.