Identificación del origen de datos y el formato
Los datos son la entrada más importante para los modelos de Machine Learning. Necesitará acceso a los datos al entrenar modelos de Machine Learning y el modelo entrenado necesita datos como entrada para generar predicciones.
Imagine que es científico de datos y que se le ha pedido que entrene un modelo de Machine Learning.
Tiene como objetivo seguir los seis pasos siguientes para planear, entrenar, implementar y supervisar el modelo:

- Definir el problema: decida qué debe predecir el modelo y cuándo lo hace correctamente.
- Obtener los datos: busque orígenes de datos y obtenga acceso.
- Preparar los datos: explore los datos. Limpie y transforme los datos en función de los requisitos del modelo.
- Entrenar el modelo: elija un algoritmo y valores de hiperparámetros en función de prueba y error.
- Integrar el modelo: implemente el modelo en un punto de conexión para generar predicciones.
- Supervisar el modelo: realice un seguimiento del rendimiento del modelo.
Nota
El diagrama es una representación simplificada del proceso de aprendizaje automático. Normalmente, el proceso es iterativo y continuo. Por ejemplo, al supervisar el modelo, puede decidir volver atrás y volver a entrenar el modelo.
Para obtener y preparar los datos que usará para entrenar el modelo de Machine Learning, deberá extraer datos de un origen y ponerlos a disposición del servicio de Azure que quiere usar para entrenar modelos o realizar predicciones.
En general, se recomienda extraer datos de su origen antes de analizarlos. Tanto si usa los datos para la ingeniería de datos, el análisis de datos o la ciencia de datos, querrá extraer los datos de su origen, transformarlos y cargarlos en una capa de servicio. Este proceso también se conoce como Extracción, transformación y carga (ETL) o Extracción, carga y transformación (ELT). La capa de servicio hace que los datos estén disponibles para el servicio que usará para el procesamiento de datos adicionales, como el entrenamiento de modelos de Machine Learning.
Antes de poder diseñar el proceso ETL o ELT, deberá identificar el origen y el formato de datos.
Identificación del origen de datos
Cuando empiece con un nuevo proyecto de aprendizaje automático, identifique primero dónde se almacenan los datos que desea usar.
Es posible que los datos necesarios para el modelo de Machine Learning ya estén almacenados en una base de datos o que una aplicación los genere. Por ejemplo, los datos se pueden almacenar en un sistema de administración de relaciones con el cliente (CRM), en una base de datos transaccional como una base de datos SQL o se pueden generar mediante un dispositivo de Internet de las cosas (IoT).
Es decir, es posible que su organización ya tenga procesos empresariales implementados que generan y almacenan los datos. Si no tiene acceso a los datos que necesita, hay métodos alternativos. Puede recopilar datos nuevos mediante la implementación de un proceso nuevo, adquirir datos nuevos mediante conjuntos de datos disponibles públicamente o comprar conjuntos de datos mantenidos.
Identificación del formato de datos
En función del origen de los datos, se pueden almacenar en un formato específico. Debe reconocer el formato actual de los datos y determinar el formato necesario para sus cargas de trabajo de aprendizaje automático.
Normalmente, nos referimos a tres formatos diferentes:
Datos tabulares o estructurados: todos los datos tienen los mismos campos o propiedades, que se definen en un esquema. Los datos tabulares se representan a menudo en una o varias tablas donde las columnas representan características y las filas representan puntos de datos. Por ejemplo, un archivo de Excel o CSV se puede interpretar como datos tabulares:
Id. de paciente Pregnancies Presión arterial diastólica BMI Pedigrí con relación a diabetes Age Diabético 1354778 0 80 43,50973 1.213191 21 0 1147438 8 93 21,24058 0,158365 23 1 Datos semiestructurados: no todos los datos tienen los mismos campos o propiedades. Cada punto de datos se representa mediante una colección de pares clave-valor. Las claves representan las características y los valores representan las propiedades del punto de datos individual. Por ejemplo, las aplicaciones en tiempo real, como los dispositivos de Internet de las cosas (IoT) generan un objeto JSON:
{ "deviceId": 29482, "location": "Office1", "time":"2021-07-14T12:47:39Z", "temperature": 23 }Datos no estructurados: archivos que no cumplen ninguna regla en lo que respecta a la estructura. Por ejemplo, los documentos, imágenes, archivos de audio y vídeo se consideran datos no estructurados. Almacenarlos como archivos no estructurados garantiza que no tenga que definir ningún esquema o estructura, pero también significa que no puede consultar los datos de la base de datos. Deberá especificar cómo leer este tipo de archivo al consumir los datos.
Sugerencia
Más información sobre los conceptos de los datos principales en Learn
Identificación del formato de datos deseado
Al extraer los datos de un origen, es posible que desee transformarlos para cambiar el formato de datos y hacer que sea más adecuado para el entrenamiento del modelo.
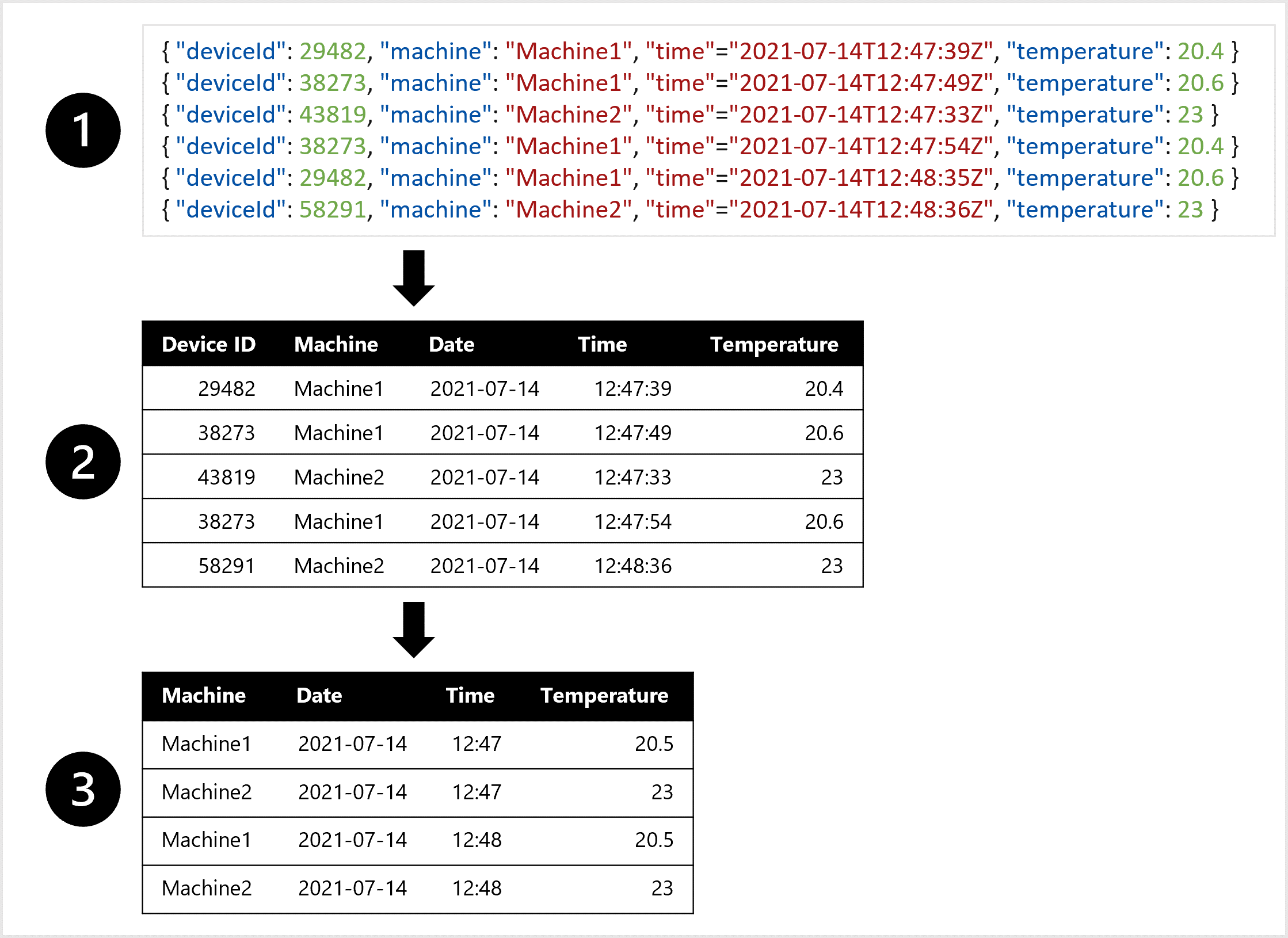
Por ejemplo, puede que desee entrenar un modelo de previsión para realizar el mantenimiento predictivo en una máquina. Quiere usar características como la temperatura de la máquina para predecir un problema con esta. Si recibe una alerta de que se produce un problema, antes de que la máquina se estropee, puede ahorrar costos corrigiendo el problema con antelación.
Imagine que la máquina tiene un sensor que mide la temperatura cada minuto. Cada minuto, cada medida o entrada se puede almacenar como un objeto o archivo JSON.
Para entrenar el modelo de previsión, puede preferir una tabla en la que se combinan todas las medidas de temperatura de cada minuto. Es posible que desee crear agregados de los datos y tener una tabla de la temperatura media por hora. Para crear la tabla, querrá transformar a datos tabulares los datos semiestructurados ingeridos desde el dispositivo IoT.
Para crear un conjunto de datos que puede usar para entrenar el modelo de previsión, puede hacer lo siguiente:
- Extraiga medidas de datos como objetos JSON de los dispositivos IoT.
- Convierta los objetos JSON en una tabla.
- Transforme los datos para obtener la temperatura por máquina por minuto.
Una vez que haya identificado el origen de datos, el formato de datos original y el formato de datos deseado, puede pensar en cómo desea servir los datos. Después, puede diseñar una canalización de ingesta de datos para extraer y transformar los datos que necesita de forma automática.