Diseño de una arquitectura de datos distribuida geográficamente
La última parte del diseño de la arquitectura de la aplicación que debemos tener en cuenta es la capa de almacenamiento de datos. Queremos asegurarnos de que los datos se puedan leer y escribir con una funcionalidad completa después de un error en toda la región.
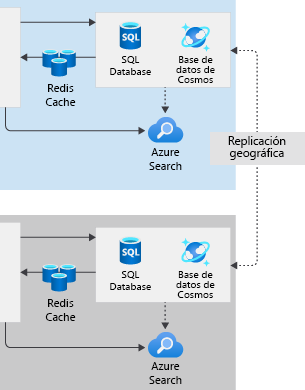
En el portal de seguimiento de envíos, decidimos usar Azure Front Door para enviar todas las solicitudes a App Services en la región Este de EE. UU. En caso de que se produzca un error en esta región, Front Door lo detectará y enviará solicitudes para duplicar los componentes de App Services en la región Oeste de EE. UU. En nuestra arquitectura original de una sola región, almacenamos datos relacionales en Azure SQL Database y datos semiestructurados en Cosmos DB. Ahora queremos saber cómo podemos asegurarnos de que ambas bases de datos sigan estando disponibles si se produce un error en la región Este de EE. UU.
Aquí veremos cómo replicar datos entre regiones y cómo asegurarnos de que la conmutación por error se produzca rápidamente en caso necesario.
Azure SQL Database
Para crear una implementación de varias regiones de Azure SQL Database para almacenar datos relacionales, podemos usar una de estas dos opciones:
- Replicación geográfica activa
- Grupos de conmutación por error automática
Replicación geográfica activa
Azure SQL Database puede replicar automáticamente una base de datos y todos sus cambios de una base de datos a otra con la característica de replicación geográfica activa. Únicamente el servidor lógico principal hospeda una copia de la base de datos que se puede escribir. Podemos crear hasta otros cuatro servidores lógicos que hospedan copias de solo lectura de la base de datos.
Para el portal de seguimiento de envíos, cree una base de datos secundaria en la región Oeste de EE. UU. y configure la replicación geográfica de la región Este de EE. UU. Cuando se produzca un error regional, Front Door redirigirá las solicitudes de los usuarios a App Services en la región Oeste de EE. UU. App Services y Azure Functions pueden obtener acceso a los datos relacionales porque ya se ha replicado una copia en la región Oeste de EE. UU.
Este cambio es automático, pero recuerde que la base de datos secundaria del Oeste de EE. UU. es de solo lectura. Si un usuario intenta modificar los datos (por ejemplo, mediante la creación de un nuevo envío), pueden producirse errores. Podemos iniciar manualmente una conmutación por error al Oeste de EE. UU. en cuanto detectemos el problema en Azure Portal. Si queremos automatizar este proceso, los desarrolladores pueden escribir código que llame al método failover en la API REST de Azure SQL Database.
Nota:
Las instancias administradas de Azure SQL Database no admiten la replicación geográfica activa. Las instancias administradas están diseñadas para simplificar la migración de datos desde una instancia de SQL Server local, a la vez que se mantiene la seguridad. Si se usa una instancia administrada, debe considerarse la posibilidad de usar grupos de conmutación por error en su lugar.
Grupos de conmutación por error automática
Un grupo de conmutación por error automática es un conjunto de bases de datos en las que los datos se replican automáticamente de un servidor primario a uno o varios servidores secundarios. Este diseño es como la replicación geográfica activa y usa el mismo método de replicación de datos. Aun así, se puede automatizar la respuesta ante un error si se define una directiva.
En el portal de envíos, crearemos una base de datos secundaria en la región Oeste de EE. UU. Después, agregaremos una directiva que conmute por error la réplica principal de la base de datos al Oeste de EE. UU. si se produce un error grave la región Este de EE. UU. En este caso, la réplica del Oeste de EE. UU. se convertirá automáticamente en la base de datos principal en la que se puede escribir y se conservará toda la funcionalidad.
Considere la posibilidad de usar un grupo de conmutación por error automática si quiere automatizar la conmutación por error de la base de datos en la que se puede escribir sin necesidad de crear código personalizado para desencadenarla. Use también los grupos de conmutación por error automática si la base de datos se ejecuta en una instancia administrada de Azure SQL Database.
Importante
La replicación que subyace a la replicación geográfica activa y a los grupos de conmutación por error automática es asincrónica. Cuando se aplica un cambio a la réplica principal, se envía una confirmación al cliente. En este momento, se considera que se ha completado la transacción y se lleva a cabo la replicación. Si se produce un error, es posible que los últimos cambios realizados en la base de datos principal no se hayan replicado en la base de datos secundaria. Tenga en cuenta que, después de un desastre, es posible que se hayan perdido los cambios más recientes en la base de datos.
Azure Cosmos DB
Nuestra configuración es menos compleja con Azure Cosmos DB porque está diseñada como un sistema de base de datos en la nube de varias regiones. Cosmos DB es una base de datos con varios modelos, capaz de almacenar datos relacionales, datos semiestructurados y otras formas de datos. Incluso si ejecutamos Cosmos DB en una sola región, los datos se replican en varias instancias en diferentes dominios de error para obtener la mejor disponibilidad.
Al crear una cuenta de Cosmos DB de varias regiones, podemos elegir entre los siguientes modos:
Cuentas de varias regiones con varias regiones de escritura.
En este modo, se puede escribir en todas las copias de la base de datos. Si se produce un error en una región, no es necesario realizar una conmutación por error.
Cuentas de varias regiones con una sola región de escritura.
En este modo, solo la región primaria contiene bases de datos en las que se puede escribir. Los datos replicados en las regiones secundarias son de solo lectura. Las actualizaciones se deshabilitan de forma predeterminada cuando se produce un error en la región primaria. Aun así, podemos seleccionar Habilitar conmutación por error automática para que Cosmos DB conmute por error automáticamente de la copia principal de la base de datos en la que se puede escribir a otra región.
Importante
En Cosmos DB, la replicación de datos es sincrónica. Cuando se aplica un cambio, la transacción no se considera completa hasta que se replica en un cuórum de réplicas. Después, se envía una confirmación al cliente. Cuando se produce un error, no se pierden los cambios recientes porque ya se ha producido la replicación.