Descripción de las métricas de rendimiento críticas
Ha aprendido a recopilar datos en Azure Monitor y en el Monitor de rendimiento de Windows. Ahora obtendrá información sobre cómo crear métricas en Azure Monitor que le permitan desencadenar alertas o ejecutar respuestas automatizadas a errores.
Revisión de las métricas de Azure
El servicio Azure Monitor incluye la capacidad de realizar un seguimiento de diversas métricas sobre el estado general de un recurso determinado. Las métricas se recopilan a intervalos regulares y son la puerta de enlace para los procesos de alerta que ayudarán a resolver los problemas de forma rápida y eficaz. Las métricas de Azure Monitor constituyen un subsistema eficaz que le permite no solo analizar y visualizar los datos de rendimiento, sino también desencadenar alertas que notifiquen a los administradores o acciones automatizadas que puedan desencadenar un runbook de Azure Automation o un webhook. También tiene la opción de archivar los datos de Azure Metrics en Azure Storage, ya que los datos activos solo se almacenan durante 93 días.
Creación de alertas de métrica
Mediante Azure Portal, puede crear reglas de alertas basadas en métricas definidas, en la sección de información general de la hoja de Azure Monitor. El ámbito de las alertas de Azure Monitor se puede definir de tres maneras. Tomando como ejemplo las máquinas virtuales de Azure, puede especificar el ámbito de la forma siguiente:
Una lista de máquinas virtuales de una región de Azure en una suscripción
Todas las máquinas virtuales (de una región de Azure) en uno o varios grupos de recursos de una suscripción
Todas las máquinas virtuales (de una región de Azure) en una suscripción
De esta manera, puede crear una regla de alertas basada en los recursos incluidos en los grupos de recursos, como se muestra.
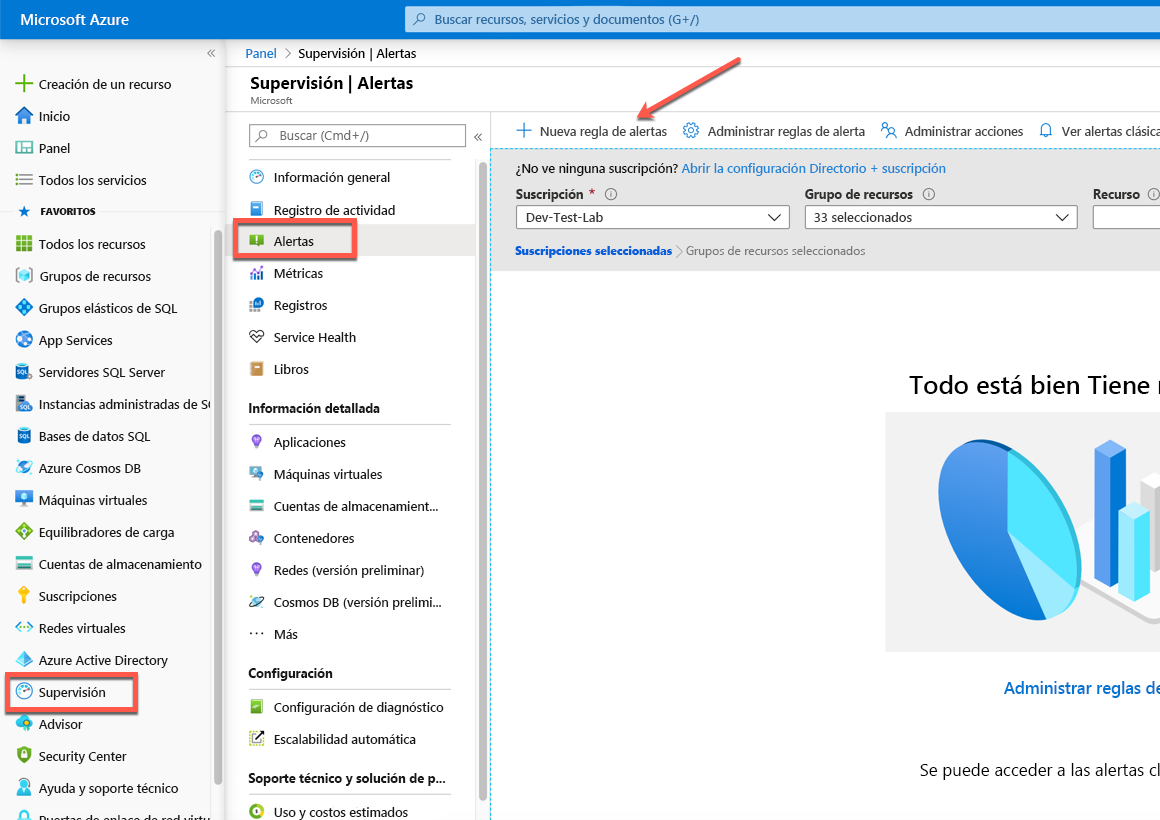
El ejemplo que se muestra a continuación refleja una máquina virtual denominada SQL2019 en la que se crea una alerta que se encuentra en el ámbito de la máquina virtual individual.
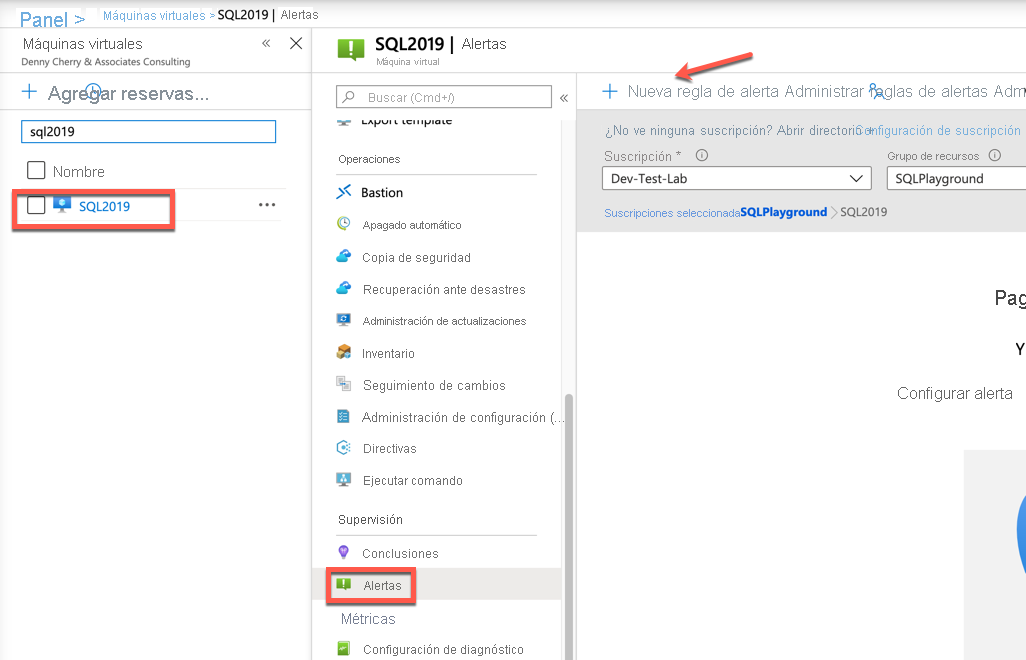
Independientemente del ámbito de la alerta, el proceso de creación es el mismo.
En la pantalla de alertas, haga clic en Nueva regla de alerta. Si se crea una alerta desde dentro del ámbito de un recurso, los valores del recurso se deben rellenar automáticamente. Puede ver que el recurso es la máquina virtual SQL2019, que la suscripción es Dev-Test-Lab y el grupo de recursos en el que reside es SQLPlayground.
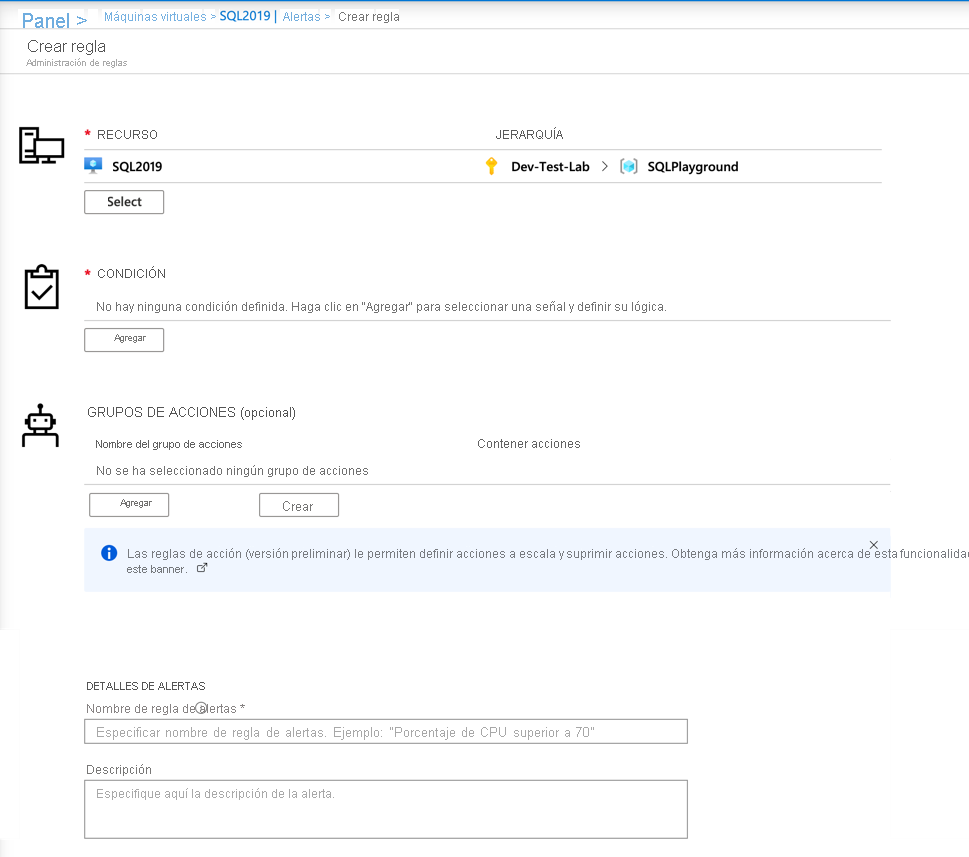
En la sección Condición, haga clic en Agregar:
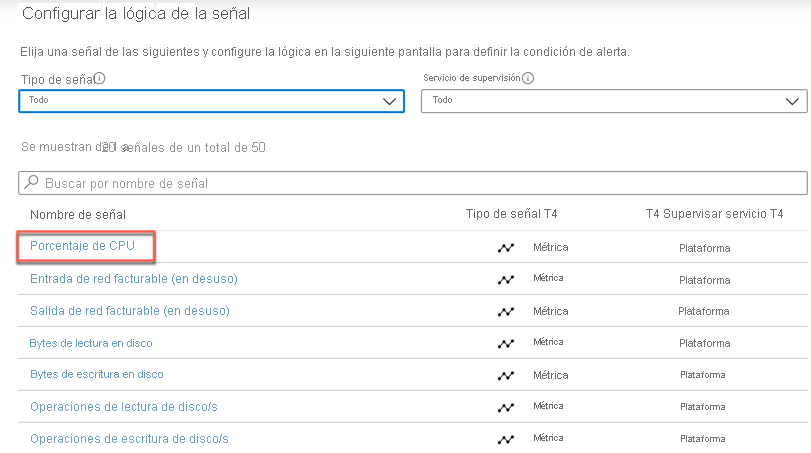
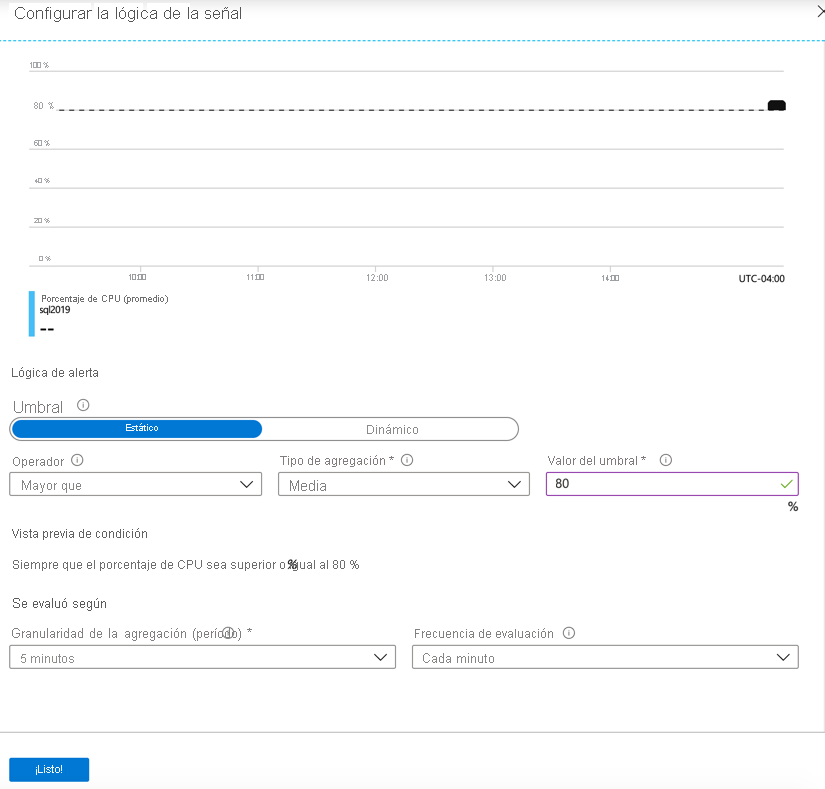
Seleccione la métrica sobre la que quiera generar alertas. En la imagen siguiente se muestra el porcentaje de CPU, que verá seleccionado.
Las alertas se pueden configurar de forma estática (por ejemplo, generar una alerta cuando la CPU supere el 95 %) o de manera dinámica mediante umbrales dinámicos. Los umbrales dinámicos aprenden el comportamiento histórico de la métrica y generan una alerta cuando los recursos funcionan de manera anómala. Estos umbrales dinámicos pueden detectar la estacionalidad en las cargas de trabajo y ajustar las alertas en consecuencia.
Si se usan alertas estáticas, debe proporcionar un umbral para la métrica seleccionada. En este ejemplo, se especificó el 80 por ciento. Este umbral significa que si el uso de la CPU supera el 80 por ciento durante un período determinado, se activará una alerta que reaccionará según lo especificado.
Ambos tipos de alertas cuentan con operadores booleanos como los operadores "mayor que" o "menor que". Junto con los operadores booleanos, hay medidas de agregado entre las que seleccionar, como el promedio, el mínimo, el máximo, el recuento y el total. Con estas opciones disponibles, es fácil crear una alerta flexible que se adapte a las alertas de nivel empresarial.
Después de crear la alerta, para notificar a los administradores o iniciar un proceso de automatización, debe configurarse un grupo de acciones.
Nota:
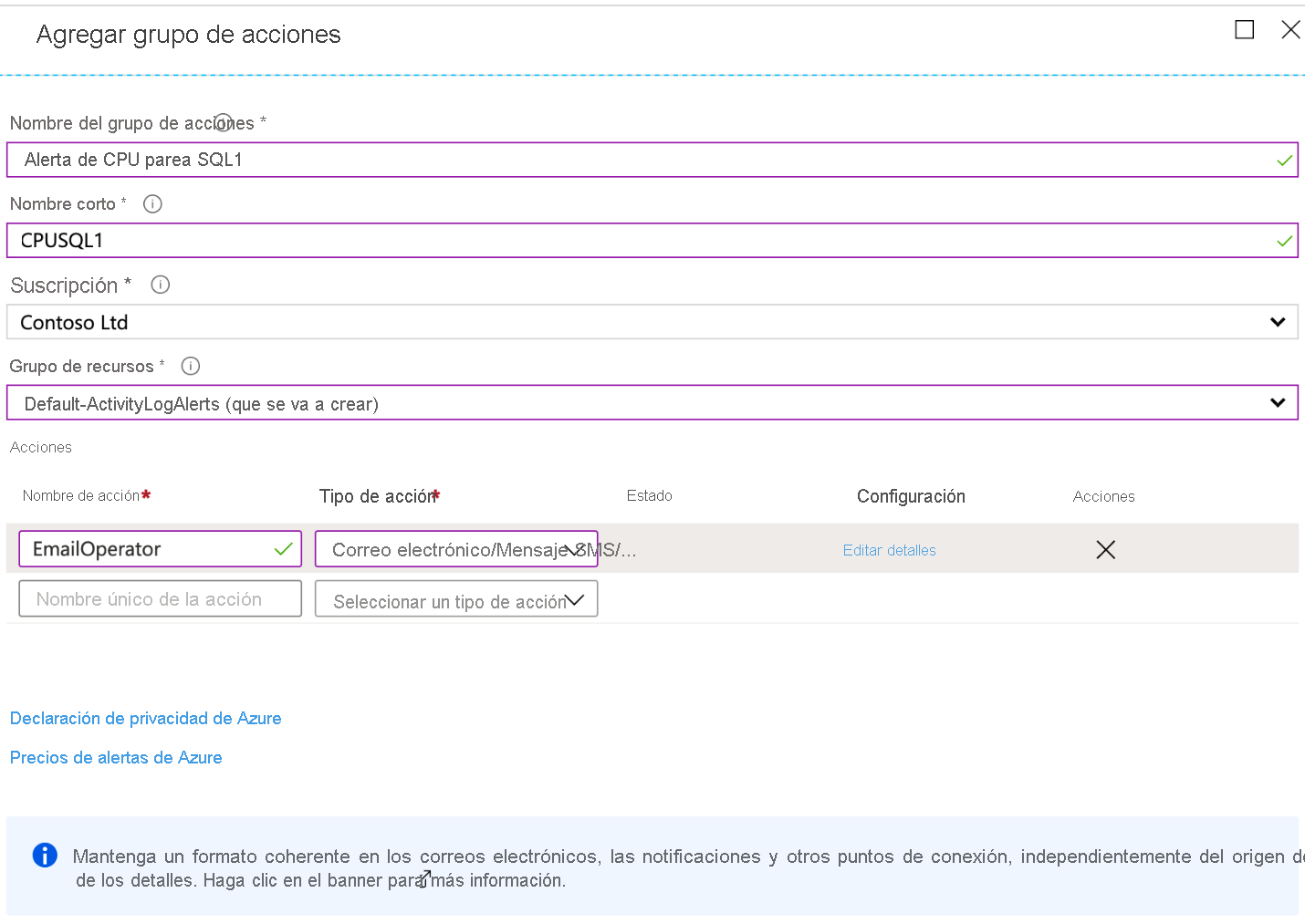
La definición de un grupo de acciones es opcional y, si no se configura uno, la alerta solo registrará la notificación en el almacenamiento sin que se realice ninguna otra acción. Puede crear un nuevo grupo de acciones desde la pantalla de métricas; para ello, haga clic en Agregar junto a Grupos de acciones. Verá este diálogo:

Una vez que haga clic en Crear grupo de acciones, verá la pantalla que se muestra a continuación. Deberá asignar un nombre al grupo de acciones y definir una alerta y la respuesta. En este ejemplo, el administrador recibirá un correo electrónico en caso de que se desencadene la condición de la alerta.
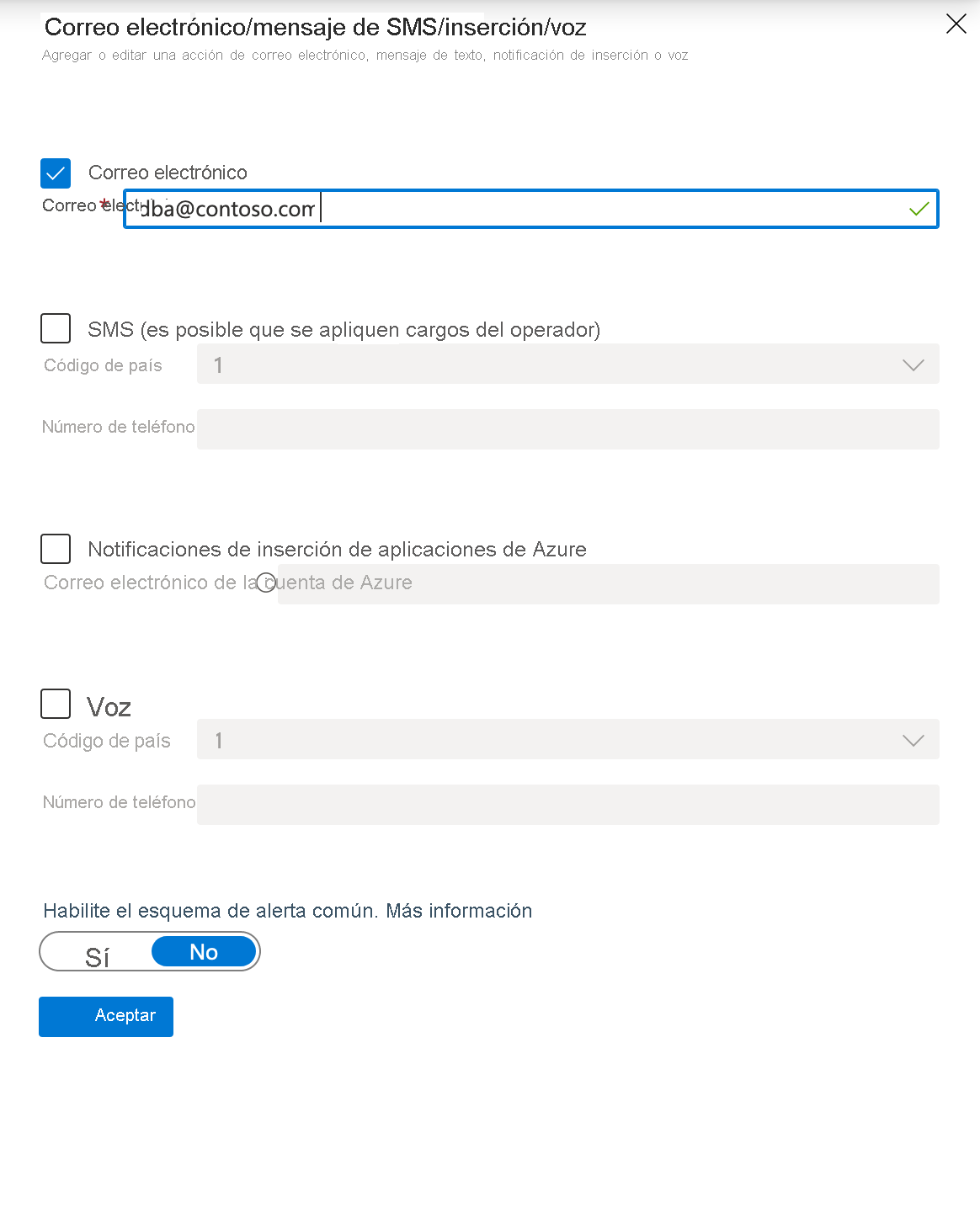
Puede configurar el correo electrónico o los detalles de SMS como se muestra a continuación. Para llegar a esta pantalla, haga clic en Editar detalles en Configurar o bien agregue una nueva acción, lo que también abrirá la pantalla de configuración.
Con un grupo de acciones, hay varias maneras en las que puede responder a la alerta. Para definir la acción que se debe realizar, hay las siguientes opciones:
- Runbook de automatización
- Función de Azure
- Rol de Azure Resource Manager de correo electrónico
- Correo electrónico, SMS, inserción o voz
- ITSM
- Aplicación lógica de Azure
- Webhook seguro
- webhook
Estas acciones se dividen en dos categorías: notificación, que significa que un evento se notifica a un administrador o grupo de administradores, y automatización, que implica la realización de una acción definida para responder a una condición de rendimiento.
Revisión de los datos de rendimiento más antiguos
Una de las ventajas de utilizar Azure Monitor es la posibilidad de revisar de forma sencilla y rápida las métricas anteriores que se han recopilado. Si examina un recurso, verá un selector de fecha y hora en la esquina superior derecha. Las métricas de Azure Monitor se conservarán durante 93 días y, después, se purgarán; sin embargo, tiene la opción de archivarlas en Azure Storage.
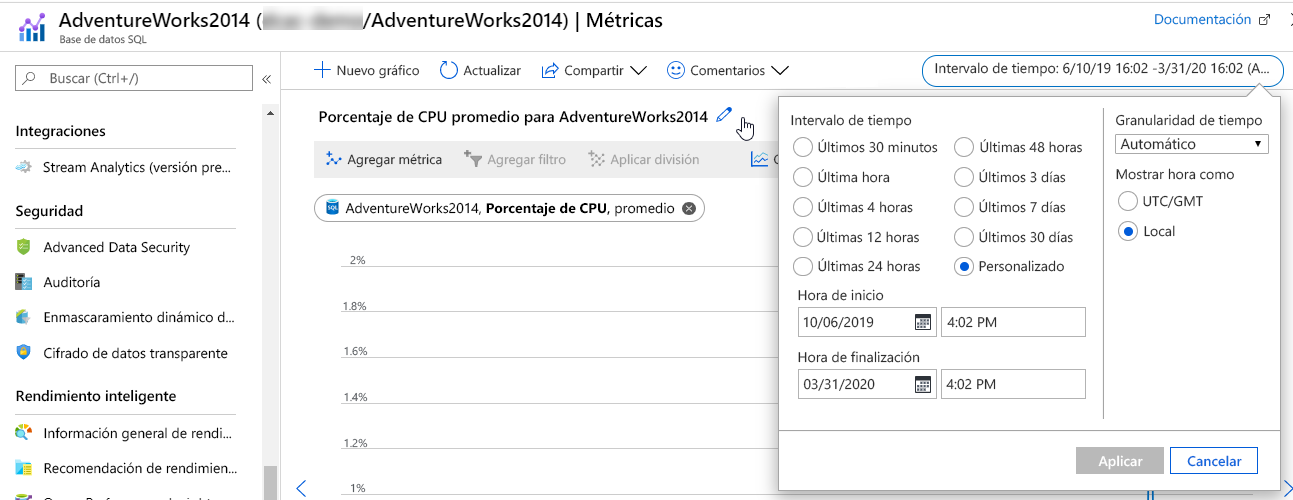
También puede seleccionar un período de tiempo más pequeño, como los últimos 30 minutos, la última hora, las últimas 4 horas o las últimas 12 horas, por ejemplo. La flexibilidad de Azure Monitor permite a los administradores identificar rápidamente los problemas, así como diagnosticar los posibles problemas anteriores.
Métricas importantes de SQL Server
Microsoft SQL Server es un componente de software bien instrumentado que recopila una gran cantidad de metadatos de rendimiento. El motor de base de datos tiene métricas que se pueden supervisar para ayudar a identificar y mejorar los problemas relacionados con el rendimiento. Algunas métricas del sistema operativo solo se pueden ver desde el Monitor de rendimiento, mientras que otras son accesibles mediante consultas de T-SQL, en concreto, seleccionándolas en las vistas de administración dinámica (DMV). Hay algunas métricas que se muestran en ambas ubicaciones, por lo que es importante saber dónde identificar métricas concretas. Un ejemplo de datos que solo se pueden capturar desde DMV es la latencia de lectura y escritura del archivo de registro de transacciones y de datos como se muestra en sys.dm_os_volume_stats. Por otro lado, un ejemplo de una métrica de sistema operativo que no está disponible directamente a través de SQL Server es el número de segundos por lectura y escritura de disco para el volumen de disco. La combinación de estas dos métricas puede ayudarle a comprender mejor si un problema de rendimiento está relacionado con la estructura de la base de datos o con un cuello de botella del almacenamiento físico.