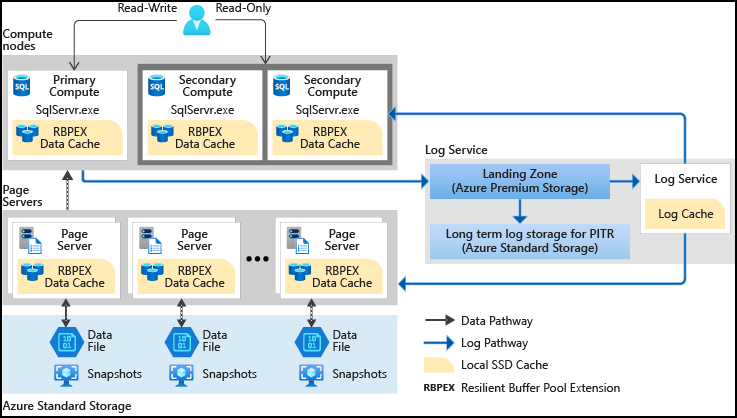
Descripción de Hiperescala de base de datos SQL
Azure SQL Database se ha limitado a 4 TB de almacenamiento por base de datos durante muchos años. Esta restricción se debe a una limitación física de la infraestructura de Azure. La Hiperescala de Azure SQL Database cambia el paradigma y permite que las bases de datos sean de 100 TB o más. La Hiperscala presenta nuevas técnicas de escalado horizontal para agregar nodos de proceso a medida que aumentan los tamaños de los datos. El costo de la Hiperescala es el mismo que el costo de Azure SQL Database; sin embargo, hay un costo por terabyte de almacenamiento. Debe tener en cuenta que una vez que Azure SQL Database se convierte en Hiperescala, no puede volver a convertirse en un base de datos "regular" de Azure SQL. La Hiperescala es la capacidad de una arquitectura para escalar correctamente de acuerdo con la demanda.
La Hiperescala de Azure SQL Database es una opción ideal para la mayoría de las cargas de trabajo empresariales, ya que proporciona una gran flexibilidad y un alto rendimiento con recursos de proceso y almacenamiento escalables de forma independiente.
Hiperescala separa el motor de procesamiento de consultas, donde la semántica de los distintos motores de datos diverge, de los componentes que proporcionan el almacenamiento a largo plazo y la durabilidad de los datos. De este modo, la capacidad de almacenamiento se puede escalar horizontalmente fácilmente en cuanto sea necesario.
El nivel de servicio Hiperescala de Azure SQL Database es el nivel de servicio más reciente en el modelo de compra basado en núcleo virtual. Este nivel de servicio es un nivel altamente escalable de almacenamiento y de rendimiento de proceso que usa Azure para escalar horizontalmente el almacenamiento y los recursos de proceso para una base de datos de Azure SQL considerablemente más allá de los límites disponibles para los niveles de servicio Uso general y Crítico para la empresa.
Ventajas
El nivel de servicio Hiperescala elimina muchos de los límites prácticos que tradicionalmente se ven en las bases de datos en la nube. Donde la mayoría de las otras bases de datos están limitados por los recursos disponibles en un único nodo, las bases de datos en el nivel de servicio Hiperescala no tienen límites de este tipo. Con su arquitectura de almacenamiento flexible, el almacenamiento crece a medida que sea necesario. De hecho, las bases de datos de Hiperescala no se crean con un tamaño máximo definido. Una base de datos de hiperescala aumenta según sea necesario, y se le cobrará solo la capacidad que use. Para cargas de trabajo de lectura intensiva, el nivel de servicio Hiperescala proporciona rápida escalabilidad horizontal mediante el aprovisionamiento de réplicas adicionales según sea necesario para descargar las cargas de trabajo de lectura.
Además, el tiempo necesario para crear copias de seguridad de bases de datos o para escalar o reducir verticalmente ya no está ligado al volumen de los datos en la base de datos. Pueden crearse copias de seguridad de las bases de datos de hiperescala de manera instantánea. También puede escalar o reducir verticalmente una base de datos de decenas de terabytes en cuestión de minutos. Esta funcionalidad le libra de la preocupación de estar atado por las opciones de la configuración inicial. Hiperescala también proporciona restauraciones rápidas de base de datos que se ejecutan en minutos en lugar de horas o días.
Hiperescala proporciona una rápida escalabilidad según la demanda de la carga de trabajo.
Escalar y reducir verticalmente: puede escalar verticalmente el tamaño de proceso principal en términos de recursos como CPU y memoria y, posteriormente, reducir verticalmente, en tiempo constante. Dado que el almacenamiento se comparte, el escalado y la reducción vertical no están vinculados al volumen de datos de la base de datos.
Escalar y reducir horizontalmente: también tiene la posibilidad de aprovisionar una o varias réplicas de proceso que puede usar para atender las solicitudes de lectura. Esto significa que puede usar estas réplicas de proceso adicionales como réplicas de solo lectura para descargar la carga de trabajo de lectura del proceso principal. Además de solo lectura, estas réplicas también pueden funcionar como servidores en espera activa en caso de una conmutación por error de la réplica principal.
El aprovisionamiento de cada una de estas réplicas de proceso adicionales se puede realizar en tiempo constante y se trata de una operación en línea. Puede conectarse a las réplicas de proceso de solo lectura estableciendo el argumento ApplicationIntent de la cadena de conexión en ReadOnly. Todas las conexiones con la intención de aplicaciones ReadOnly se enrutan automáticamente a una de las réplicas de proceso de solo lectura.
Hiperescala separa el motor de procesamiento de consultas de los componentes que proporcionan almacenamiento a largo plazo y durabilidad de los datos. Esta arquitectura ofrece la posibilidad de escalar fácilmente la capacidad de almacenamiento en la medida en que sea necesario (el objetivo inicial es de 100 TB), así como de escalar rápidamente los recursos de proceso.
Consideraciones sobre la seguridad
La seguridad para el nivel de servicio Hiperescala comparte las mismas funcionalidades excelentes que el resto de niveles de Azure SQL Database. Están protegidos mediante el enfoque por capas de defensa en profundidad, como se muestra en la siguiente imagen, y se mueve desde el exterior hacia el centro:
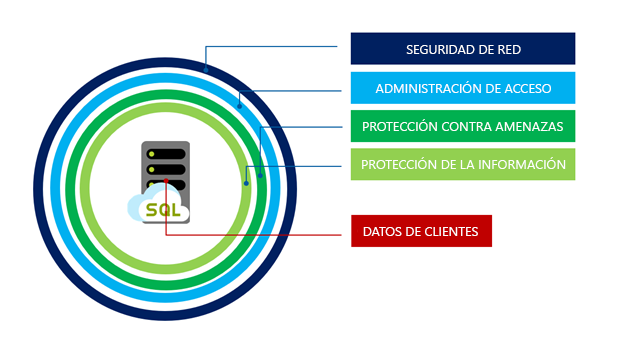
La seguridad de red es el primer nivel de defensa y usa reglas de firewall de IP para permitir el acceso en función de la dirección IP de origen y las reglas de firewall de red virtual para permitir la posibilidad de aceptar las comunicaciones enviadas desde subredes seleccionadas dentro de una red virtual.
La administración de acceso se proporciona a través de los siguientes métodos de autenticación para asegurarse de que un usuario es quien dice ser:
- Autenticación de SQL
- Autenticación de Microsoft Entra
- Autenticación de Windows para entidades de seguridad de Microsoft Entra (versión preliminar)
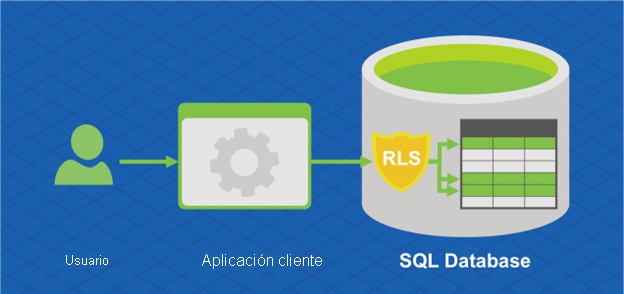
La Hiperescala de Azure SQL Database también admite la seguridad de nivel de fila. La seguridad de nivel de fila permite a los clientes controlar el acceso a las filas de una tabla de base de datos según las características del usuario que ejecuta una consulta (por ejemplo, la pertenencia a grupos o el contexto de ejecución).
Capacidades de protección contra amenazas en las funciones de auditoría y detección de amenazas. La auditoría de SQL Database e Instancia administrada de SQL hace un seguimiento de las actividades de la base de datos y ayuda a mantener el cumplimiento de los estándares de seguridad mediante la grabación de eventos de la base de datos en un registro de auditoría de una cuenta de almacenamiento de Azure propiedad del cliente. La Protección avanzada contra amenazas puede habilitarse por servidor mediante una tarifa adicional y analiza los registros para detectar comportamientos inusuales e intentos potencialmente dañinos de acceder a las bases de datos o aprovecharse de ellas. Las alertas se crean para detectar actividades sospechosas, como inyección de código SQL, infiltración potencial de datos y ataques de fuerza bruta, o anomalías en los patrones de acceso para detectar elevaciones de privilegios y uso de credenciales vulneradas.
Information Protection se proporciona de las siguientes maneras:
- Seguridad de la capa de transporte (cifrado en tránsito)
- Cifrado de datos transparente (cifrado en reposo)
- Administración de claves con Azure Key Vault
- Always Encrypted (cifrado en uso)
- Enmascaramiento de datos dinámicos
Consideraciones de rendimiento
El nivel de servicio Hiperescala está pensado para clientes que tienen grandes bases de datos locales de SQL Server y quieren modernizar las aplicaciones mediante su traslado a la nube o para clientes que ya utilizan Azure SQL Database y desean ampliar significativamente las posibilidades de crecimiento de la base de datos. También está pensado para clientes que buscan un alto rendimiento y escalabilidad.
La Hiperescala proporciona las siguientes funciones de rendimiento:
- Copias de seguridad de base de datos casi instantáneas (basadas en las instantáneas de archivos almacenadas en Azure Blob Storage) independientemente del tamaño sin efecto de la E/S en los recursos de proceso.
- Restauraciones rápidas de bases de datos (basadas en instantáneas de archivos) en minutos en lugar de horas o días (no del tamaño de la operación de datos).
- Mayor rendimiento general debido a una mayor capacidad de proceso de los registros de transacciones y tiempos más rápidos de confirmación de estas, independientemente de los volúmenes de datos.
- Rápido escalado horizontal: puede aprovisionar una o varias réplicas de solo lectura para la descarga de la carga de trabajo de lectura y para su uso como esperas activas.
- Rápido escalado vertical: en tiempo constante, puede escalar verticalmente los recursos de proceso para dar cabida a cargas de trabajo pesadas cuando sea necesario y, después, reducir verticalmente los recursos de proceso cuando no sean necesarios.
Nota
La Hiperescala de SQL Database no admite las siguientes características:
- Instancia administrada de SQL
- Grupos elásticos
- Replicación geográfica
- Información del rendimiento de las consultas
Implementación de la Hiperescala de Azure SQL Database
Para implementar Azure SQL Database con el nivel Hiperescala:
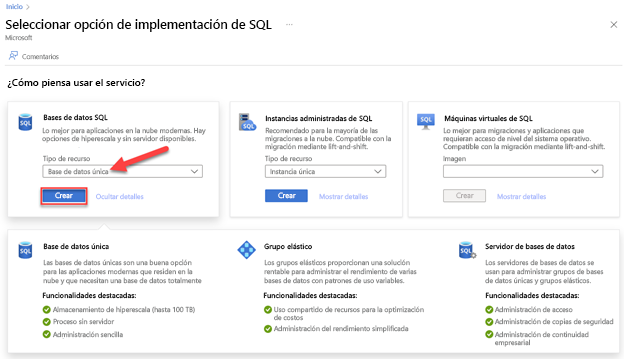
Vaya a la página Seleccione una opción de implementación de SQL.
En Bases de datos SQL, deje Tipo de recurso establecido en Base de datos única y seleccione Crear.
En la pestaña Aspectos básicos de la página Crear SQL Database, seleccione la suscripción que quiera, el grupo de recursos y el nombre de la base de datos.
Seleccione el vínculo Crear nuevo para el Servidor y rellene la nueva información del servidor, como el nombre del servidor, el inicio de sesión y la contraseña del administrador del servidor y la ubicación.
En Proceso y almacenamiento, seleccione el vínculo Configurar base de datos.
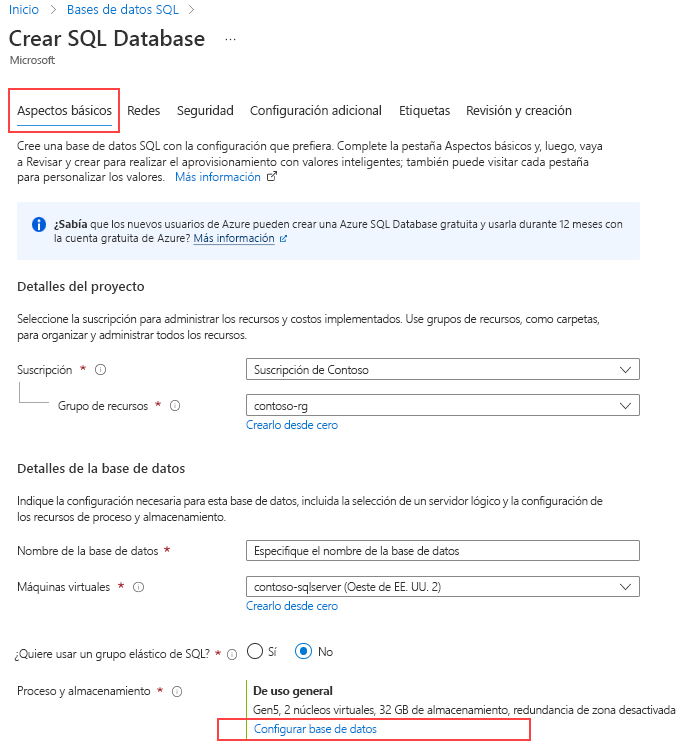
En Nivel de servicio, seleccione Hiperescala.
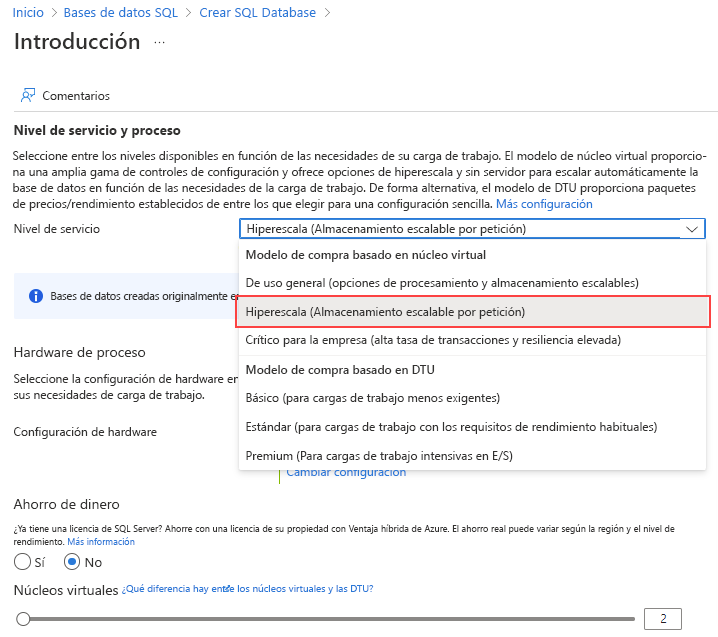
En Configuración de hardware, seleccione el vínculo Cambiar configuración. Revise las configuraciones de hardware disponibles y seleccione la configuración más adecuada para la base de datos. Para este ejemplo, vamos a seleccionar la configuración Gen5.
Seleccione Aceptar para confirmar la generación de hardware.
Opcionalmente, ajuste el control deslizante Núcleos virtuales si desea aumentar el número de núcleos virtuales de la base de datos. En este ejemplo, vamos a seleccionar 2 núcleos virtuales.
Ajuste el control deslizante Réplicas secundarias de alta disponibilidad para crear una réplica de alta disponibilidad (HA). Seleccione Aplicar.
Seleccione Siguiente: Redes en la parte inferior de la página.
En Reglas de firewall, en la pestaña Redes, establezca Agregar dirección IP del cliente actual en Sí. Deje la opción Permitir que los servicios y recursos de Azure accedan a este grupo de servidores establecida en No.
Seleccione Siguiente: Seguridad en la parte inferior de la página.
En la pestaña Revisar y crear, seleccione Crear.
