Ejecución de la carga de trabajo de inferencia en el servidor de inferencia de NVIDIA Triton
Ahora estamos listos para ejecutar el script de Python de ejemplo en el servidor Triton. Si observa en el directorio demo, verá una colección de carpetas y archivos.
En la carpeta demo/app, hay dos scripts de Python. El primero, frame_grabber.py, usa el servidor de inferencia de Triton. El segundo, frame_grabber_onnxruntime.py, se puede usar de forma independiente. La carpeta utils dentro del directorio app contiene scripts de Python para habilitar la interpretación del tensor de salida del modelo.
Ambos scripts de Python se establecen para ver el directorio image_sink para cualquier archivo de imagen que se coloque ahí. En images-sample encontrará una colección de imágenes que copiamos a través de la línea de comandos en image_sink para su procesamiento. Los scripts de Python eliminan automáticamente los archivos de image_sink una vez completada la inferencia.
En la carpeta model-repo, encontrará una carpeta para el nombre del modelo (gtc_onnx), que contiene el archivo de configuración del modelo para el servidor de inferencia de Triton y el archivo de etiqueta. También se incluye una carpeta que indica la versión del modelo, que contiene el modelo Open Neural Network Exchange (ONNX) que el servidor usa para la inferencia.
Si el modelo detecta los objetos en los que se entrenó, el script de Python crea una anotación de esa inferencia con un cuadro de límite, un nombre de etiqueta y una puntuación de confianza. El script guarda la imagen en la carpeta images-annotated con un nombre único mediante una marca de tiempo, que podemos descargar para ver de forma local. De este modo, puede copiar las mismas imágenes una y otra vez en image_sink, pero se han creado nuevas imágenes anotadas en cada ejecución con fines ilustrativos.
Ejecución de una carga de trabajo de inferencia en el servidor de inferencia de NVIDIA Triton
Para empezar a usar la inferencia, queremos abrir dos ventanas en la Terminal Windows y
sshen la máquina virtual desde cada ventana.En la primera ventana, ejecute el siguiente comando, pero cambie primero el marcador de posición de <nombre de usuario> por el nombre de usuario de la máquina virtual:
sudo docker run --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --rm -p8000:8000 -p8002:8002 -v/home/<your username>/demo/model-repo:/models nvcr.io/nvidia/tritonserver:20.11-py3 tritonserver --model-repository=/modelsEn la segunda ventana, copie el siguiente comando, cambie el <nombre de usuario> a su valor y establezca el <umbral de probabilidad> en el nivel de confianza deseado entre 0 y 1. De manera predeterminada, este valor está establecido en 0.6.
python3 demo/app/frame_grabber.py -u <your username> -p .07En la tercera ventana, copie y pegue este comando para copiar los archivos de imagen de la carpeta
images_sampleen la carpetaimage_sink:cp demo/images_sample/* demo/image_sink/Si vuelve a la segunda ventana, puede ver la ejecución del modelo, las estadísticas del modelo y la inferencia devuelta en forma de diccionario de Python.
Esta es una vista de ejemplo de lo que debería ver en la segunda ventana a medida que se ejecuta el script:
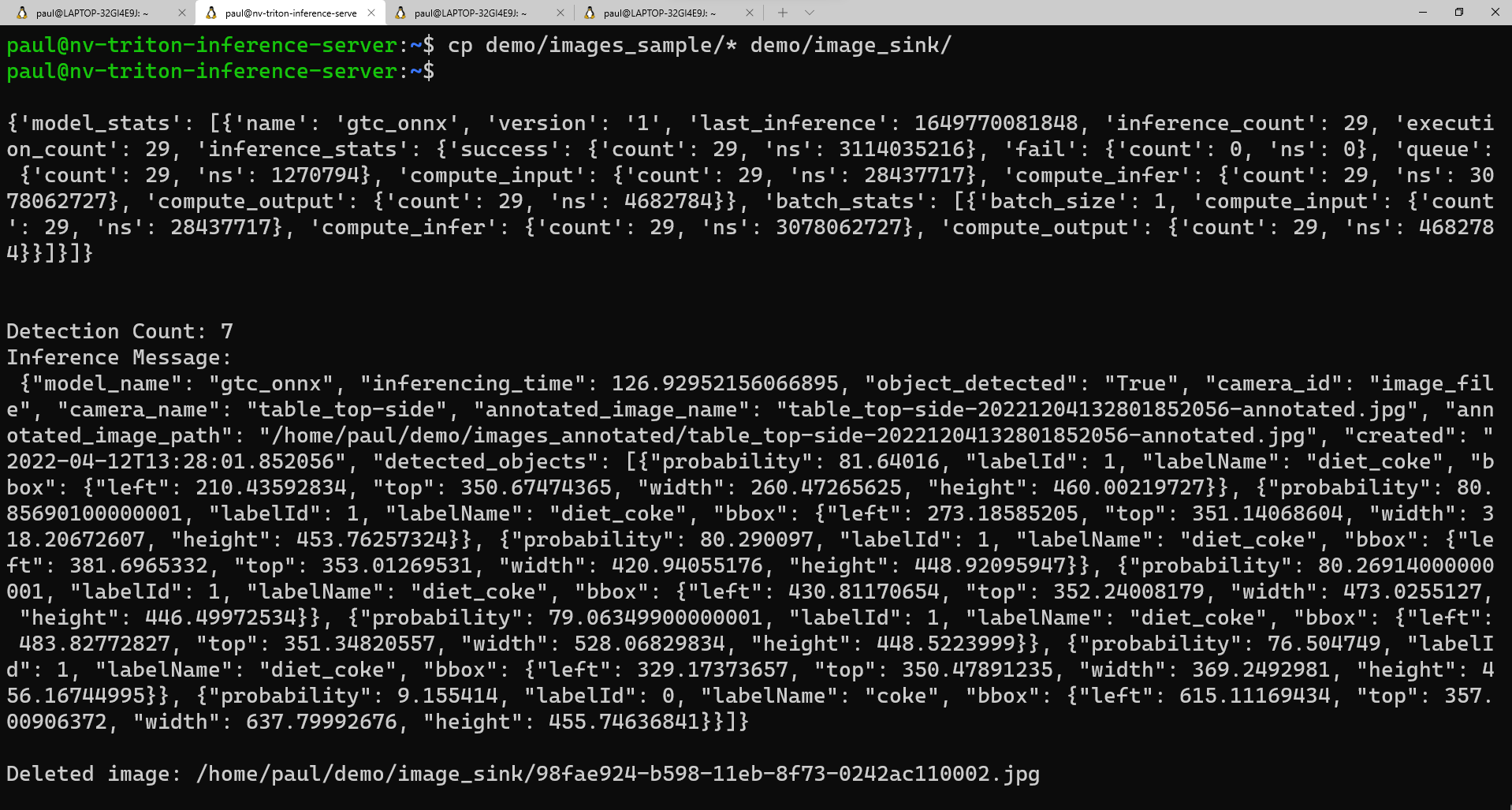
Si desea ver una lista de las imágenes anotadas, puede ejecutar este comando:
ls demo/annotated_imagesPara descargar las imágenes en el equipo local, primero tenemos que crear una carpeta para recibir las imágenes. En una ventana de línea de comandos,
cden el directorio en el que va a colocar la nueva carpeta y ejecute:mkdir annotated_img_download scp <your usename>@x.x.x.x:/home/<your username>/demo/images_annotated/* annotated_img_download/Este comando copia todos los archivos de la máquina virtual Ubuntu en el dispositivo local para su visualización.
