Comprensión de los conceptos del aprendizaje profundo
El cerebro tiene células nerviosas, las neuronas, que están conectadas entre sí por extensiones nerviosas que transmiten señales electroquímicas a través de la red.

Cuando se estimula la primera neurona de la red, se procesa la señal de entrada y, si supera un umbral determinado, la neurona se activa y transmite la señal a las neuronas con las que está conectada. A su vez, estas neuronas se pueden activar y transmitir la señal a través del resto de la red. Con el tiempo, las conexiones entre los neuronas se refuerzan por el uso frecuente a medida que aprende a responder de forma eficaz. Por ejemplo, si alguien le muestra una imagen de un pingüino, sus conexiones neuronales le permiten procesar la información de la imagen y sus conocimientos de las características de un pingüino para identificarlo como tal. Con el tiempo, si le muestran varias imágenes de varios animales, la red de neuronas que le permite identificar animales según sus características será más fuerte. En otras palabras, mejorará a la hora de identificar con precisión diferentes animales.
El aprendizaje profundo emula este proceso biológico mediante redes neuronal artificiales que procesan entradas numéricas en lugar de estímulos electroquímicos.
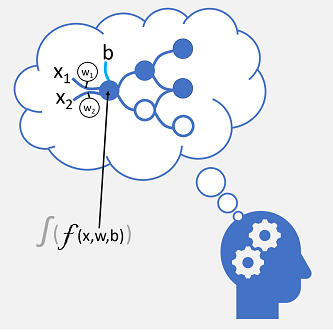
Las conexiones nerviosas entrantes se reemplazan por entradas numéricas que se suelen identificar como x. Cuando hay más de un valor de entrada, x se considera vector con elementos denominados x1, x2, y así sucesivamente.
Asociado con cada valor x hay un valor ponderación (w), que se usa para fortalecer o debilitar el efecto del valor x para simular el aprendizaje. Además, se agrega una entrada sesgo (b) para permitir el control específico sobre la red. Durante el proceso de entrenamiento, se ajustarán los valores w y b para optimizar la red de modo que "aprenda" a generar los resultados correctos.
La neurona misma encapsula una función que calcula una suma ponderada de x, w y b. A su vez, esta función se encuentra en una función de activación que restringe el resultado (por lo general, a un valor entre 0 y 1) a fin de determinar si la neurona transmite o no un resultado a la capa siguiente de neuronas de la red.
Entrenamiento de un modelo de aprendizaje profundo
Los modelos de aprendizaje profundo son redes neuronales formadas por varias capas de neuronas artificiales. Cada capa representa un conjunto de funciones que se ejecutan en los valores x con ponderaciones w y sesgos b asociados, y la capa final da una salida de la etiqueta y que predice el modelo. En el caso de un modelo de clasificación (que predice la categoría o clase más probable de los datos de entrada), la salida es un vector que contiene la probabilidad de cada clase posible.
El diagrama siguiente representa un modelo de aprendizaje profundo que predice la clase de una entidad de datos en función de cuatro características (los valores x). La salida del modelo (los valores y) es la probabilidad de cada una de las tres etiquetas de clase posibles.
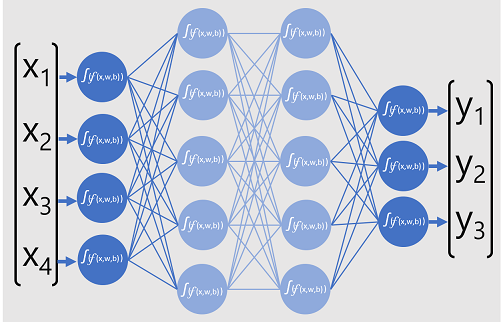
Para entrenar el modelo, un marco de aprendizaje profundo alimenta varios lotes de datos de entrada (cuyos valores de etiqueta reales se conocen), aplica las funciones en todas las capas de la red y mide la diferencia entre las probabilidades de salida y las etiquetas de clase reales conocidas de los datos de entrenamiento. La diferencia agregada entre las salidas de predicción y las etiquetas reales se denomina pérdida.
Después de calcular la pérdida agregada de todos los lotes de datos, el marco de aprendizaje profundo usa un optimizador para determinar cómo se deben ajustar las ponderaciones y los sesgos del modelo para reducir la pérdida general. Estos ajustes se vuelven a propagar a las capas del modelo de red neuronal y, después, se vuelven a pasar los datos a través de la red y se vuelve a calcular la pérdida. Este proceso se repite varias veces (cada iteración se conoce como época) hasta que se minimiza la pérdida y el modelo ha "aprendido" las ponderaciones y sesgos correctos para poder predecir con precisión.
Durante cada época, las ponderaciones y los sesgos se ajustan para minimizar la pérdida. El valor del ajuste depende de la velocidad de aprendizaje que especifique para el optimizador. Si la velocidad de aprendizaje es demasiado baja, el proceso de entrenamiento puede tardar mucho tiempo en determinar los valores óptimos; pero si es demasiado alta, es posible que el optimizador nunca encuentre los valores óptimos.