Conocer los componentes de Azure Data Factory
Una suscripción de Azure puede tener una o varias instancias de Azure Data Factory. Azure Data Factory consta de cuatro componentes principales. Estos componentes funcionan juntos para proporcionar la plataforma en la que pueda crear flujos de trabajo basados en datos con pasos para moverlos y transformarlos.
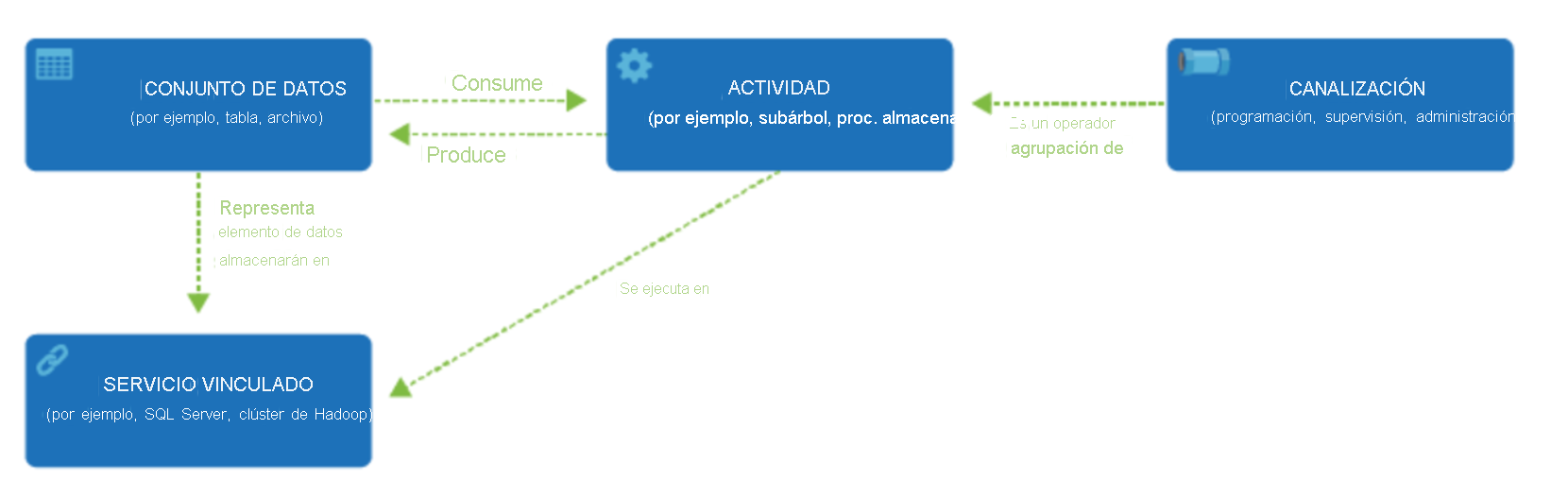
Data Factory admite una amplia variedad de orígenes de datos a los que se puede conectar mediante la creación de un objeto conocido como servicio vinculado, lo que le permite ingerir los datos de un origen de datos en preparación para preparar los datos para su transformación o análisis. Además, los servicios vinculados pueden activar los servicios de proceso a petición. Por ejemplo, puede tener un requisito para iniciar un clúster de HDInsight a petición con el fin de procesar solo los datos mediante una consulta de Hive. Por tanto, los servicios vinculados permiten definir orígenes de datos, o recursos de proceso necesarios para ingerir y preparar los datos.
Con el servicio vinculado definido, Azure Data Factory tiene en cuenta los conjuntos de valores que debe utilizar mediante la creación de un objeto de conjuntos de datos. Los conjuntos de datos representan las estructuras de datos del almacén de datos al que hace referencia el objeto de servicio vinculado. Los conjuntos de datos también pueden utilizarse por un objeto ADF conocido como una actividad.
Las actividades normalmente contienen la lógica de transformación o los comandos de análisis del trabajo de Azure Data Factory. Las actividades incluyen la actividad de copia que se puede usar para ingerir datos de diversos orígenes de datos. También pueden incluir el flujo de datos de asignación para realizar transformaciones de datos sin código. También puede incluir la ejecución de un procedimiento almacenado, una consulta de Hive o un script de Pig para transformar los datos. Puede introducir datos en un modelo de Machine Learning para realizar el análisis. No es raro que se produzcan varias actividades que pueden incluir la transformación de datos mediante un procedimiento almacenado de SQL y, después, realizar análisis con Databricks. En este caso, se pueden agrupar lógicamente varias actividades junto con un objeto denominado canalización, que se pueden programar para que se ejecuten, o bien se puede definir un desencadenador que determine cuándo es necesario iniciar una ejecución de canalización. Existen diferentes tipos de desencadenadores para diferentes tipos de eventos.
El flujo de control es una orquestación de actividades de canalización que incluye el encadenamiento de actividades en una secuencia, la bifurcación, la definición de parámetros en el nivel de canalización y el paso de argumentos mientras se invoca la canalización a petición o desde un desencadenador. También incluye el paso a un estado personalizado y contenedores de bucle, y los iteradores Para cada.
Los parámetros son pares clave-valor de configuración de solo lectura. Los parámetros se definen en la canalización. Los argumentos de los parámetros definidos se pasan durante la ejecución desde el contexto de ejecución creado por un desencadenador o una canalización que se ejecuta manualmente. Las actividades dentro de la canalización consumen los valores de parámetro.
Azure Data Factory tiene un entorno de ejecución de integración que le permite enlazar entre la actividad y los objetos de servicios vinculados. El servicio vinculado hace referencia a él, y este proporciona el entorno de proceso donde se ejecuta la actividad o desde donde se distribuye. De este modo, la actividad se puede realizar en la región más cercana posible. Hay tres tipos de entorno de Integration Runtime, entre los que se incluyen Azure, autohospedado y Azure-SSIS.
Una vez completado todo el trabajo, puede usar Data Factory para publicar el conjunto de cambios final en otro servicio vinculado que, a continuación, puede consumir tecnologías como Power BI o Machine Learning.