Explicación del proceso de Data Factory
Flujos de trabajo controlados por datos
Las canalizaciones (flujos de trabajo orientados a datos) en Azure Data Factory realizan normalmente los cuatro pasos siguientes:
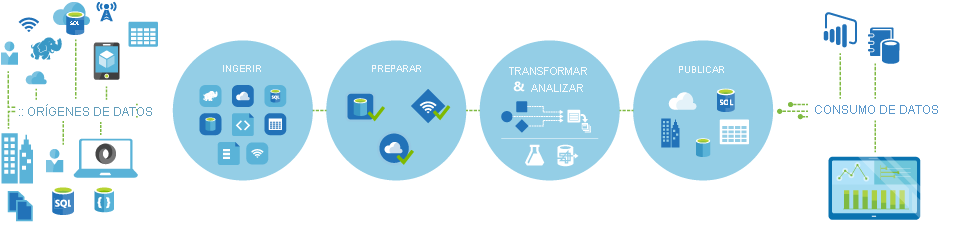
Conectar y recopilar
El primer paso para crear un sistema de orquestación es definir y conectar todas las fuentes de datos necesarias, como bases de datos, recursos compartidos y servicios web FTP. El siguiente paso consiste en ingerir los datos según sea necesario a una ubicación centralizada para su posterior procesamiento.
Transformar y enriquecer
Los servicios de proceso, como los Databricks y Machine Learning, se pueden usar para preparar o generar datos transformados según una programación controlada y supervisada a fin de alimentar los entornos de producción con datos limpios y transformados. En algunos casos, puede aumentar aún más los datos de origen con datos adicionales para el análisis de ayuda o consolidarlos a través de un proceso de normalización que se usará en un experimento de Machine Learning como ejemplo.
Publicar
Después de que se han perfeccionado los datos sin procesar en un formato compatible listo para los negocios desde la fase de transformación y enriquecimiento, puede cargar los datos en Almacenamiento de datos de Azure, Azure SQL Database, Azure Cosmos DB o los análisis del motor a los que los usuarios de su empresa pueden apuntar a partir de sus herramientas de inteligencia empresarial.
Supervisión
Azure Data Factory tiene compatibilidad integrada con la supervisión de canalizaciones a través de la API de Azure Monitor, PowerShell, registros de Azure Monitor y paneles de mantenimiento en Azure Portal, para supervisar las actividades programadas y las canalizaciones para las tasas de éxito y error.