Creación de un clúster de HDInsight
Existen varios medios para crear un clúster de HDInsight, desde la interfaz de usuario sencilla de Azure Portal hasta configuraciones con scripts que pueden resultar de ayuda en las implementaciones automatizadas. En la tabla siguiente se muestran los distintos métodos que se pueden usar para configurar un clúster de HDInsight.
| Clústeres creados con | Explorador web | Línea de comandos | API DE REST | SDK |
|---|---|---|---|---|
| Azure portal | ✔ | |||
| Azure Data Factory | ✔ | ✔ | ✔ | ✔ |
| Azure CLI | ✔ | |||
| Azure PowerShell | ✔ | |||
| cURL | ✔ | ✔ | ||
| .NET SDK | ✔ | |||
| Plantilla del Administrador de recursos de Azure | ✔ |
Todas las configuraciones de HDInsight requieren la siguiente información básica:
Pestaña Aspectos básicos
Detalles del proyecto
Suscripción
Define la suscripción de Azure en la que se facturará y se administrará HDInsight.
Definición de un nombre de grupo de recursos
Un grupo de recursos es una agrupación lógica de tecnologías y servicios de Azure que suelen estar relacionados con la misma aplicación o ciclo de vida de la aplicación. La inclusión de servicios en el mismo grupo de recursos facilita el mantenimiento administrativo.
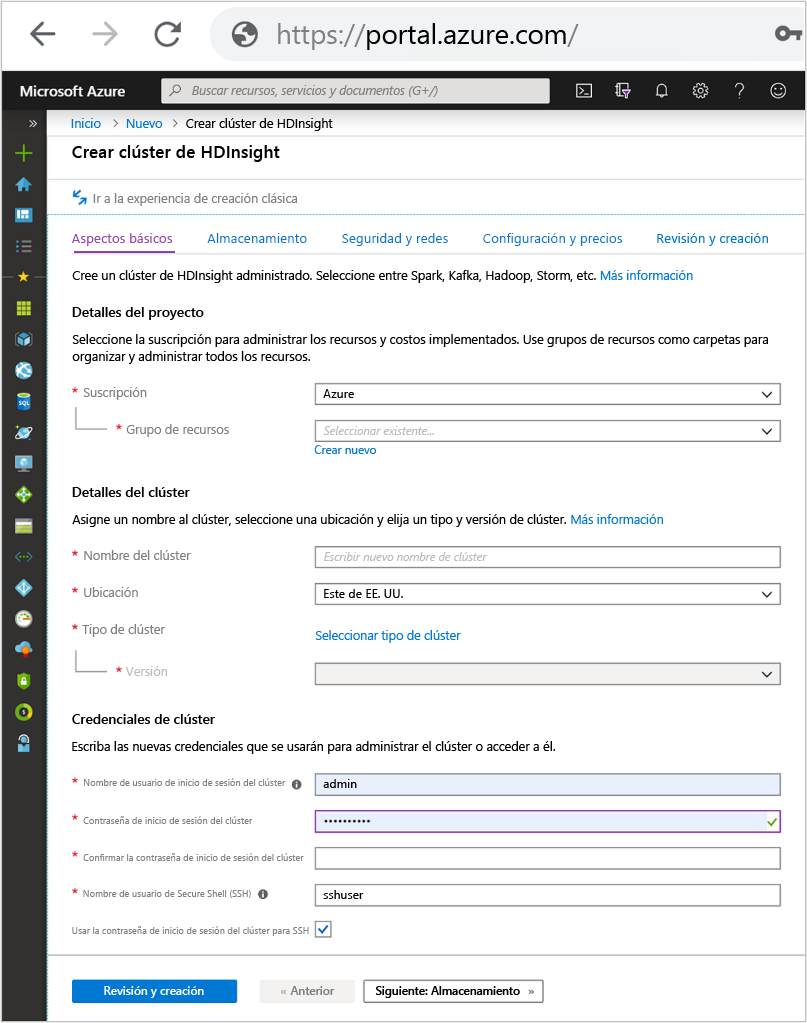
Detalles del clúster
Nombre del clúster
Los nombres de clúster de HDInsight tienen las siguientes restricciones:
- Caracteres permitidos: a-z, 0-9, A-Z
- Longitud máxima: 59
- Nombres reservados: aplicaciones
- El ámbito de nombres del clúster es común para todo Azure, para todas las suscripciones. Por lo tanto, el nombre del clúster debe ser único en todo el mundo.
- Los seis primeros caracteres deben ser únicos en una red virtual.
Ubicación
Especifica la ubicación donde se almacena el tipo de clúster. Si no se define ninguna ubicación, el clúster se coloca en la misma ubicación que el almacenamiento predeterminado. La ubicación debe estar lo más cerca posible de los usuarios para reducir la latencia.
Tipos de clúster
Define la pila de tecnología aprovisionada en el clúster de recursos. Seleccione un tipo de clúster en función del tipo de datos que tiene y del tipo de procesamiento que requiere su escenario. En la tabla siguiente se muestran los tipos de clúster disponibles.
| Tipo de clúster | Descripción |
|---|---|
| Apache Hadoop | Un marco que usa HDFS y un modelo de programación de MapReduce simple para procesar y analizar datos por lotes. |
| Apache Spark | plataforma de procesamiento paralelo de código abierto que admite el procesamiento en memoria para mejorar el rendimiento de las aplicaciones de análisis de macrodatos. |
| HBase | base de datos NoSQL en Hadoop que proporciona acceso aleatorio y coherencia fuerte para grandes cantidades de datos no estructurados y semiestructurados; potencialmente miles de millones de filas multiplicadas por millones de columnas. |
| Consulta interactiva de Apache | almacenamiento en caché en memoria para realizar consultas de Hive interactivas y más rápidas. |
| Apache Kafka | una plataforma de código abierto que se usa para crear canalizaciones y aplicaciones de datos de streaming. Kafka también proporciona funcionalidad de cola de mensajes que le permite publicar flujos de datos y suscribirse a ellos. |
Versión
Define la versión de HDInsight para este clúster. HDInsight 4.0 es la versión más reciente y tiene los marcos más recientes aprovisionados en clústeres.
Credenciales del clúster
Con los clústeres de HDInsight, puede configurar dos cuentas de usuario durante la creación del clúster.
Inicio de sesión y contraseña del clúster
El nombre de usuario predeterminado es admin. Usa la configuración básica de Azure Portal. A veces, se denomina "Usuario de clúster".
Nombre de usuario y contraseña de SSH
se usa para conectarse al clúster mediante SSH.
Nota:
El paquete de seguridad de la empresa le permite integrar HDInsight con Active Directory y Apache Ranger. Se pueden crear varios usuarios con el paquete de seguridad de la empresa.
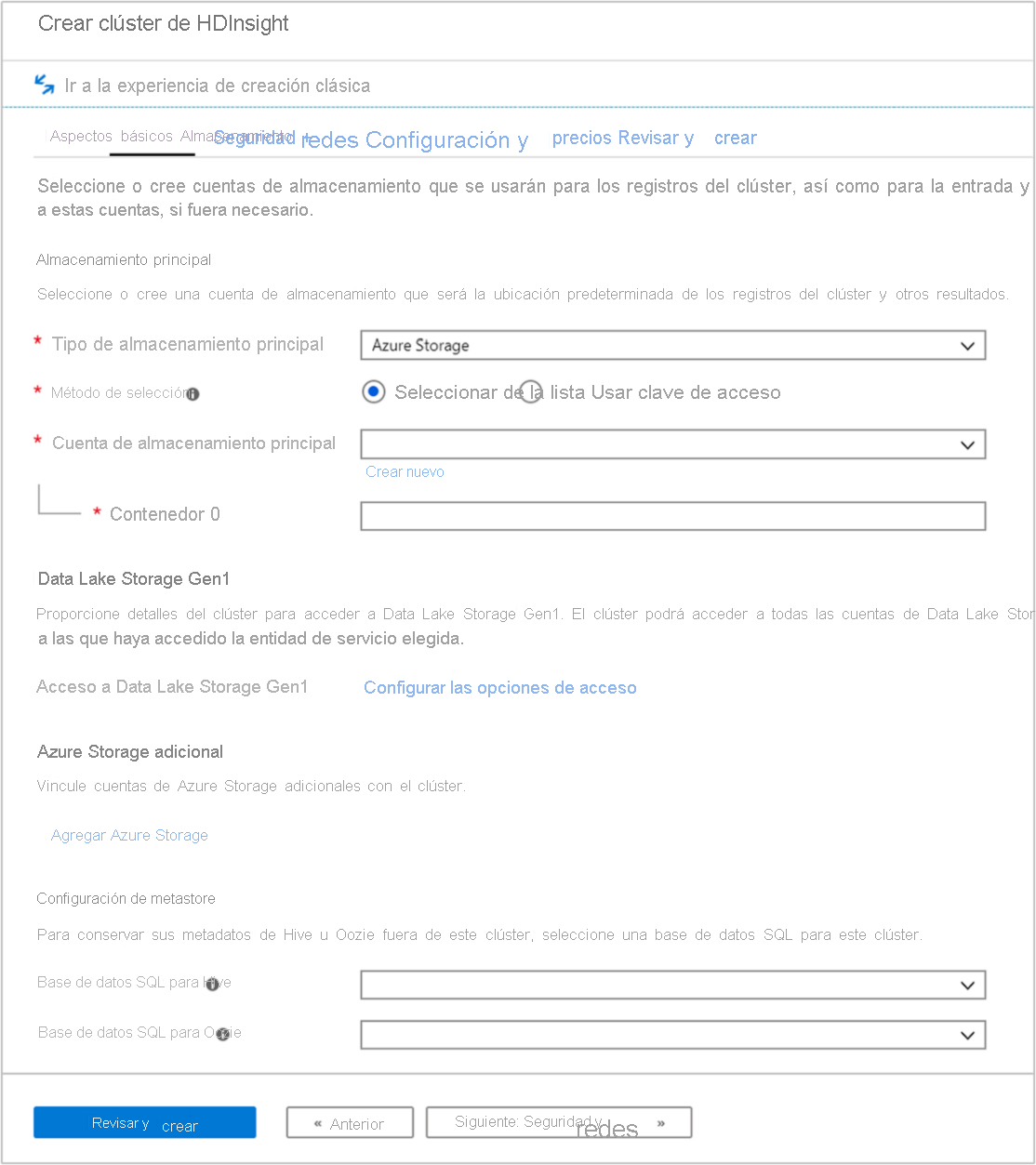
Pestaña Almacenamiento
Los clústeres de HDInsight pueden usar las siguientes opciones de almacenamiento, como se muestra en la pantalla de almacenamiento:
- Azure Data Lake Storage Gen2
- Azure Data Lake Storage Gen1
- Almacenamiento de Azure de uso general v2
- Almacenamiento de Azure de uso general v1
- Blob en bloques de Azure Storage (solo se admite como almacenamiento secundario)
La pantalla de almacenamiento permite definir la cuenta de almacenamiento principal y el contenedor predeterminado. También puede vincular instancias adicionales de Azure Storage al clúster. La configuración del metastore permite definir una base de datos SQL externa para almacenar tablas de Hive después de eliminar un clúster y mejorar el rendimiento de Oozie mediante el almacenamiento de los metadatos en un almacén externo.
Seguridad y redes
Para los tipos de clúster de Hadoop, Spark, HBase, Kafka e Interactive Query, puede elegir la opción para habilitar Enterprise Security Package. Este paquete ofrece la opción de tener una configuración de clúster más segura mediante Apache Ranger y la integración con Microsoft Entra ID.
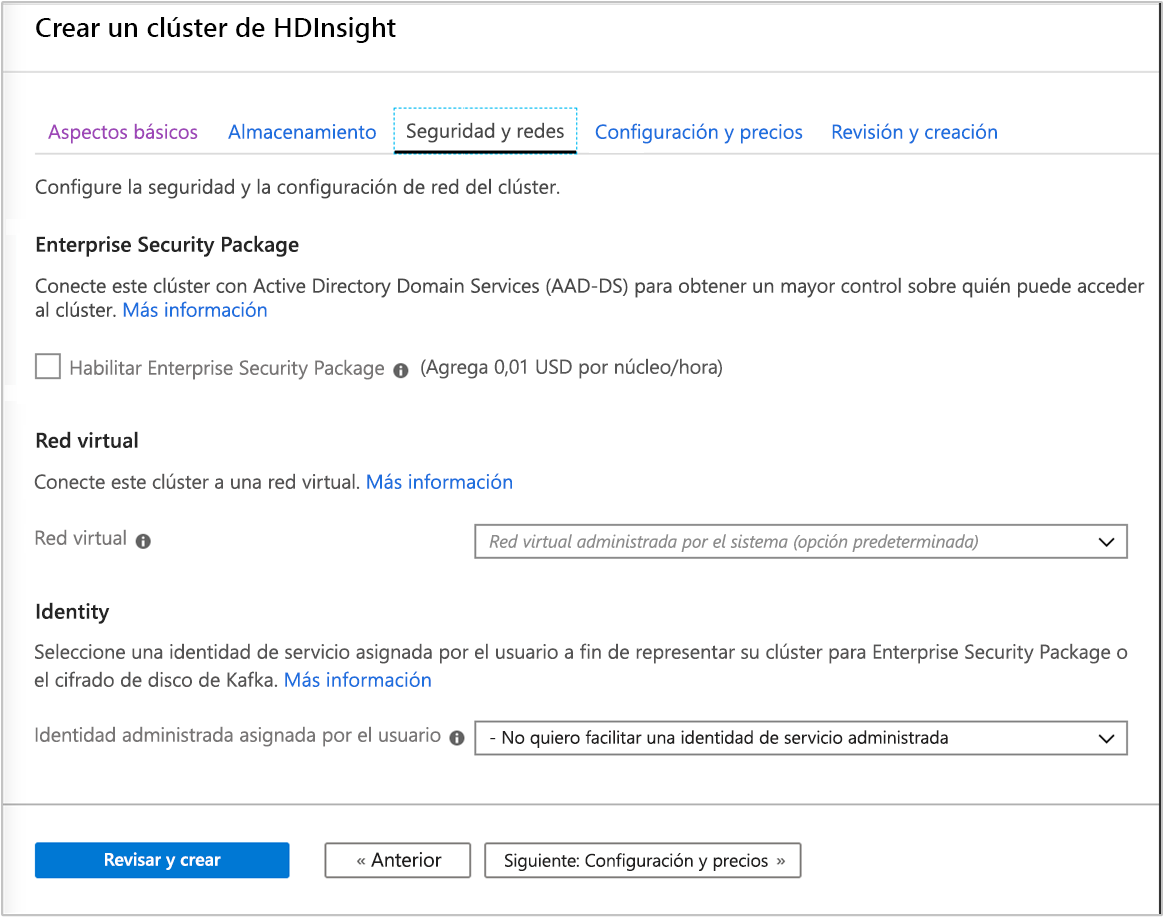
Además, siempre se recomienda implementar clústeres de HDInsight dentro de una red virtual. En esta pantalla puede definir y establecer la red virtual. Si la solución requiere tecnologías repartidas entre varios tipos de clústeres de HDInsight, una red virtual de Azure puede conectar los tipos de clústeres necesarios. Esta configuración permite que los clústeres, y cualquier otro código que se implemente en ellos, se comuniquen directamente entre sí.
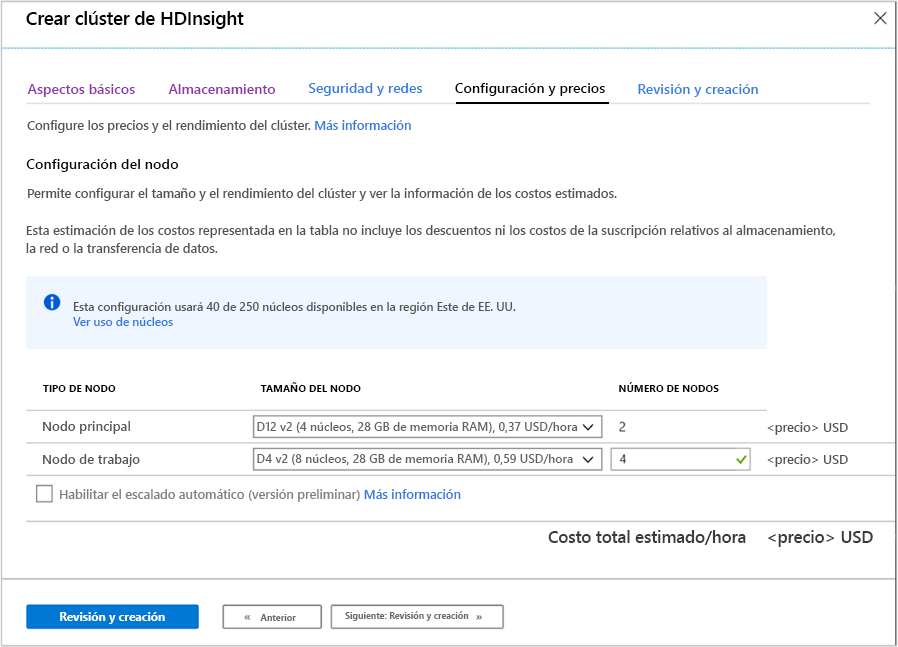
Configuración y precios
Esta página permite configurar el tamaño y el rendimiento del clúster y ver información de los costos estimados. En esta pantalla, puede definir las máquinas virtuales que se usarán para los nodos principales y de trabajo.