Aptitud de clasificación de texto personalizado
La clasificación personalizada de texto permite asignar un pasaje de texto a diferentes clases definidas por el usuario. Por ejemplo, podría entrenar un modelo en la sinopsis de la portada posterior de los libros para identificar automáticamente un género de libros. A continuación, usar ese género identificado para enriquecer el motor de búsqueda de la tienda en línea con una faceta de género.
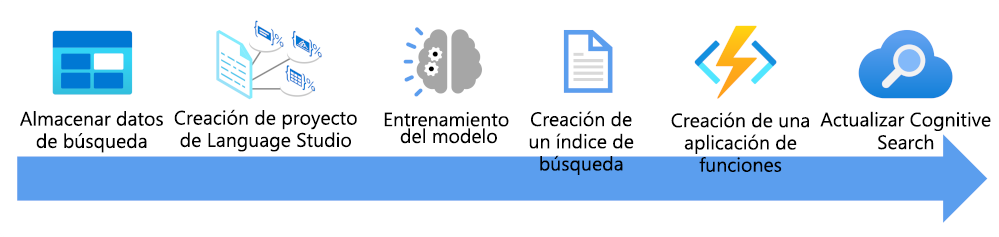
Aquí verá lo que debe tener en cuenta para enriquecer un índice de búsqueda mediante un modelo de clasificación de texto personalizado.
- Almacene sus documentos para que los indexadores de Language Studio y Búsqueda de Azure AI puedan acceder a ellos
- Crear un proyecto de clasificación de texto personalizado.
- Entrene y pruebe el modelo.
- Cree un índice de búsqueda basado en los documentos almacenados.
- Cree una aplicación de funciones que use el modelo entrenado implementado.
- Actualice la solución de búsqueda, el índice, el indexador y el conjunto de aptitudes personalizadas.
Almacenar los datos
Se puede acceder a Azure Blob Storage desde Language Studio y Azure AI Services. El contenedor debe ser accesible, por lo que la opción más sencilla es elegir Contenedor, pero también es posible usar contenedores privados con alguna configuración adicional.
Junto con los datos, también necesita una manera de asignar clasificaciones para cada documento. Language Studio proporciona una herramienta gráfica que se puede usar para clasificar cada documento manualmente de uno en uno.
Puede elegir entre dos tipos de proyecto diferentes. Si un documento se asigna a una sola clase, use un proyecto de clasificación de una sola etiqueta. Si quiere asignar un documento a más de una clase, use el proyecto de clasificación de varias etiquetas.
Si no quiere clasificar manualmente cada documento, puede etiquetar todos sus documentos antes de crear su proyecto de Lenguaje de Azure AI. Este proceso implica la creación de un documento JSON de etiquetas en este formato:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Agregue tantas clases como tenga en la matriz classes. Agregue una entrada para cada documento de la matriz documents, incluidas las clases que coinciden con el documento.
Cree su proyecto de Lenguaje de Azure AI
Hay dos formas de crear su proyecto de Lenguaje de Azure AI. Si empieza a usar Language Studio sin crear primero un servicio de lenguaje en Azure Portal, Language Studio le ofrecerá crear uno automáticamente.
La forma más flexible de crear un proyecto de Lenguaje de Azure AI es crear primero su servicio lingüístico mediante Azure Portal. Si elige esta opción, obtendrá la opción de agregar características personalizadas.
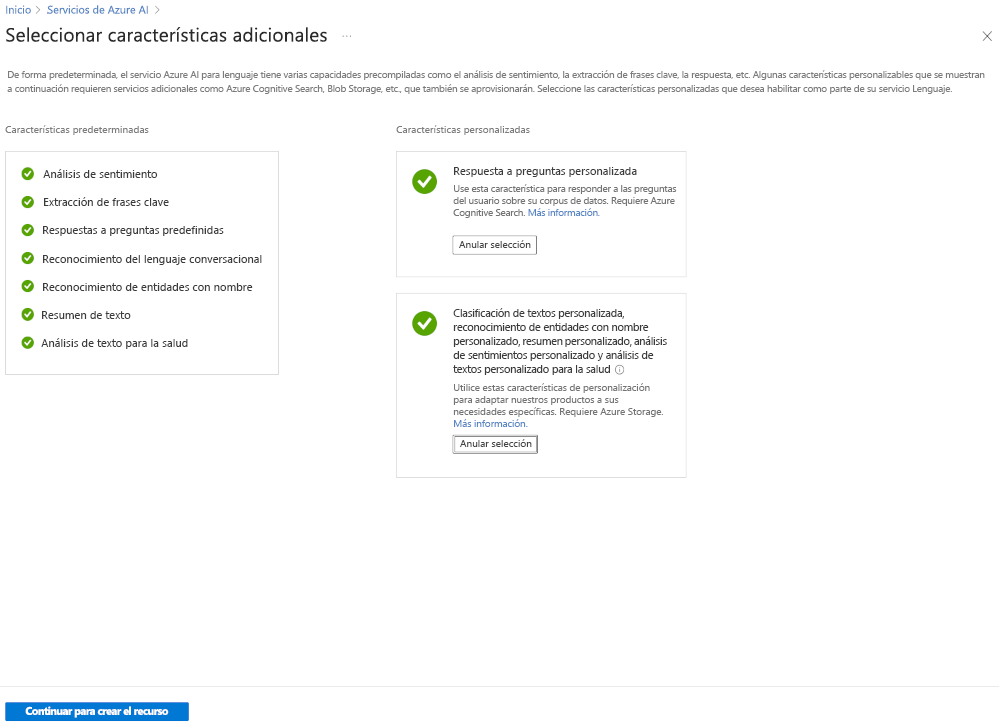
Si quiere crear una clasificación de texto personalizado, seleccione esa característica personalizada al crear el servicio de lenguaje. También debe vincular el servicio de lenguaje a una cuenta de almacenamiento mediante este método.
Una vez implementado el recurso, puede ir directamente a Language Studio desde el panel de información general del servicio de lenguaje. A continuación, puede crear un nuevo proyecto de clasificación personalizada de texto.
Nota:
Si ha creado el servicio de lenguaje desde Language Studio, es posible que tenga que seguir estos pasos. Establezca roles para el recurso de lenguaje de Azure y la cuenta de almacenamiento para conectar el contenedor de almacenamiento al proyecto de clasificación de texto personalizado.
Entrenamiento de un modelo de clasificación de texto
Al igual que con todos los modelos de IA, debe tener datos identificados que pueda usar para entrenar el modelo. El modelo debe ver ejemplos de cómo asignar datos a una clase y tener algunos ejemplos que pueda usar para probar el modelo. Puede optar por permitir que el modelo divida automáticamente los datos de entrenamiento: de forma predeterminada, usará el 80 % de los documentos para entrenar el modelo y el 20 % para probarlos a ciegas. Si tiene documentos específicos con los que desea probar el modelo, puede etiquetar los documentos para realizar pruebas.

En Language Studio, en el proyecto, seleccione Etiquetado de datos. Verá todos los documentos. Seleccione cada documento que quiera agregar al conjunto de pruebas y, a continuación, seleccione Probar el rendimiento del modelo. Guarde las etiquetas actualizadas y, a continuación, cree un nuevo trabajo de entrenamiento.
Creación de un índice de búsqueda
No hay que hacer nada específico para crear un índice de búsqueda que se enriquecerá mediante un modelo de clasificación personalizada de texto. Siga los pasos indicados en Creación de una solución de Búsqueda de Azure AI. Actualizará el índice, el indexador y la aptitud personalizada una vez que haya creado una aplicación de funciones.
Crear una aplicación de función de Azure
Puede elegir el lenguaje y las tecnologías que desee para la aplicación de funciones. La aplicación debe poder pasar JSON al punto de conexión de clasificación personalizada de texto, por ejemplo:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
A continuación, procese la respuesta JSON del modelo, por ejemplo:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
Después, la función devuelve un mensaje JSON estructurado a un conjunto de aptitudes personalizadas en Búsqueda de IA, por ejemplo:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Hay cinco elementos que la aplicación de funciones debe saber:
- El texto que se va a clasificar.
- El punto de conexión para el modelo de clasificación personalizada de texto que ha entrenado e implementado.
- La clave principal del proyecto de clasificación personalizada de texto.
- Nombre del proyecto.
- El nombre de la implementación.
El texto que se va a clasificar se pasa desde su conjunto de aptitudes personalizadas en Búsqueda de IA a la función como entrada. Los cuatro elementos restantes se pueden encontrar en Language Studio.

Los nombres del punto de conexión y de la implementación se encuentran en el panel de implementación de un modelo.

El nombre del proyecto y la clave principal se encuentran en el panel de configuración del proyecto.
Actualice su solución de Búsqueda de Azure AI
Debe realizar tres cambios en Azure Portal para enriquecer el índice de búsqueda.
- Debe agregar un campo al índice para almacenar el enriquecimiento de clasificación personalizada de texto.
- Debe agregar un conjunto de aptitudes personalizado para llamar a la aplicación de funciones con el texto que se va a clasificar.
- Debe asignar la respuesta del conjunto de aptitudes al índice.
Agregación de un campo a un índice existente
En Azure Portal, vaya a su recurso de Búsqueda de IA, seleccione el índice y agregue JSON en este formato:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Este JSON agrega un campo compuesto al índice para almacenar la clase en un campo category que se puede buscar. El segundo campo confidenceScore almacena el porcentaje de confianza en un campo doble.
Edición del conjunto de aptitudes personalizado
En el Portal de Azure, seleccione el conjunto de aptitudes y agregue JSON en este formato:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Esta definición de aptitud WebApiSill especifica que el idioma y el contenido de un documento se pasan como entradas a la aplicación de funciones. La aplicación devolverá un texto JSON denominado class.
Asignación de la salida de la aplicación de funciones al índice
El último cambio es asignar la salida al índice. En el Portal de Azure, seleccione el indexador y edite el JSON para que tenga una nueva asignación de salida:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
Ahora el indexador sabe que la salida document/class de la aplicación de funciones debe almacenarse en el campo classifiedtext. Como se ha definido como un campo compuesto, la aplicación de funciones tiene que devolver una matriz JSON que contiene los campos category y confidenceScore.
Ahora puede buscar un índice de búsqueda enriquecido para el texto clasificado de manera personalizada.