Ejercicio: Importación de bibliotecas de Python y datos de lanzamiento de cohetes
Ahora tiene un objetivo: ¿Es probable que se produzca un lanzamiento dadas las condiciones meteorológicas específicas? Tiene un conjunto de datos que contiene datos meteorológicos de:
- Varios lanzamientos correctos
- Un día de lanzamiento aplazado
- Los días anteriores y posteriores a cada lanzamiento.
Ahora puede empezar a programar.
Aprendizaje automático en el código
Puede usar diversas herramientas y servicios para solucionar problemas de aprendizaje automático. En estas rutas de aprendizaje sobre el espacio se usa Visual Studio Code, Python, scikit-learn y Azure.
Vea este vídeo de Microsoft para obtener información sobre cómo descargar y configurar un entorno similar al que necesitará.
Al configurar el entorno de programación local, se recomienda crear un entorno de Anaconda para asegurarse de que tiene exactamente lo que necesita para ese proyecto. Puede usar el método o conjunto de herramientas que prefiera. La mayoría de estos módulos no requieren explícitamente Visual Studio Code ni Azure.
Configuración del entorno local
Antes de continuar, asegúrese de que tiene lo siguiente:
- Visual Studio Code, Anaconda y Python instalados. Crearemos nuestro entorno de Anaconda en los pasos siguientes.
- Una carpeta local que haya creado para almacenar todo el código y los datos.
- El archivo de Excel de nuestros datos descargado y guardado en su carpeta local.
- Un cuaderno de Jupyter Notebook en blanco guardado en la carpeta. En la carpeta local, cree un archivo ficticio llamado nombredearchivo.ipynb.
Para configurar el entorno local:
Abra el símbolo del sistema de Anaconda.
En el símbolo del sistema de Anaconda, cree un nuevo entorno de Anaconda con Pandas, NumPy, scikit-learn, PyDotPlus y Jupyter:
conda create -n myenv python=3.8 pandas numpy jupyter seaborn scikit-learn pydotplusEn el símbolo del sistema de Anaconda, active el nuevo entorno:
conda activate myenvEn el símbolo del sistema de Anaconda, instale AzureML-SDK:
pip install --upgrade azureml-sdkEn algunos casos, la instalación puede tardar varios minutos en completarse. Deje que se resuelva hasta que se complete.
En el símbolo del sistema de Anaconda, instale un lector de Excel (tenga en cuenta que xlrd podría no funcionar con el archivo de datos de Excel que descargó):
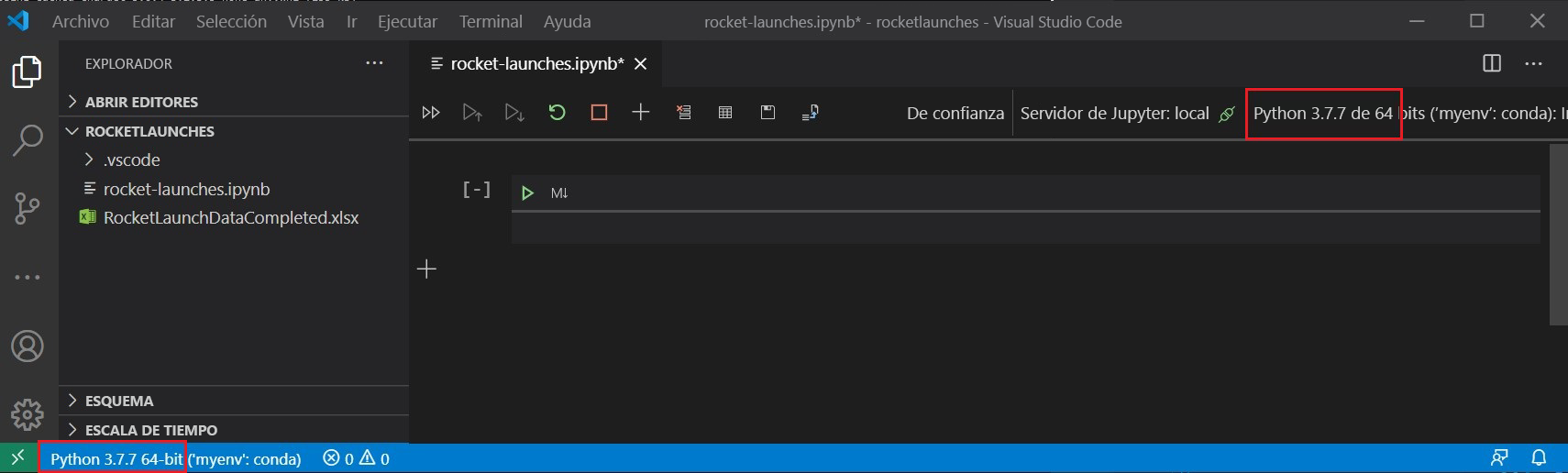
pip install openpyxlEn Visual Studio Code, abra la carpeta local que ha creado para almacenar todo el código y los datos. Seleccione la versión de Python del kernel de Jupyter de la parte superior derecha y el intérprete de Python de la parte inferior izquierda, y establézcalos para usar su entorno de Anaconda:
Importación de bibliotecas
Con el entorno local de Visual Studio Code creado, ahora puede importar las bibliotecas. Le ayudarán a importar y limpiar los datos meteorológicos, y a crear y probar el modelo de Machine Learning.
Copie el código siguiente en una celda y ejecútelo para importar las bibliotecas.
# Pandas library is used for handling tabular data
import pandas as pd
# NumPy is used for handling numerical series operations (addition, multiplication, and ...)
import numpy as np
# Sklearn library contains all the machine learning packages we need to digest and extract patterns from the data
from sklearn import linear_model, model_selection, metrics
from sklearn.model_selection import train_test_split
# Machine learning libraries used to build a decision tree
from sklearn.tree import DecisionTreeClassifier
from sklearn import tree
# Sklearn's preprocessing library is used for processing and cleaning the data
from sklearn import preprocessing
# for visualizing the tree
import pydotplus
from IPython.display import Image
Lectura de datos en una variable
Ahora que se han importado todas las bibliotecas, puede usar la biblioteca pandas para importar los datos. Use el comando pd.read_excel para leer los datos y guardarlos en una variable. Después, use la función .head() para imprimir las primeras cinco filas de datos para asegurarse de que lo hemos leído todo correctamente.
launch_data = pd.read_excel('RocketLaunchDataCompleted.xlsx')
launch_data.head()
Inicio de la exploración de los datos
Por último, podemos usar la llamada de función .columns para ver todas las columnas de nuestros datos. Así, se nos mostrarán los atributos que tienen los datos. Verá algunos atributos comunes, como los nombres de los cohetes anteriores programados para el lanzamiento, las fechas en que se han programado, si realmente se han lanzado y muchos más. Examine estas columnas e intente adivinar cuáles tendrán el mayor impacto a la hora de determinar si se va a lanzar un cohete.
launch_data.columns