Ejercicio: Uso de los datos de limpieza y transformación de Azure Data Factory
La característica Power Query en Azure Data Factory permite trabajar con datos y transformarlos. Es un objeto de flujo de datos que se puede agregar al diseñador del lienzo como una actividad en una canalización de Azure Data Factory para realizar la preparación de datos sin código. Permite que los usuarios que no están familiarizados con las tecnologías de preparación de datos tradicionales, como Spark o SQL Server, ni con lenguajes como Python y T-SQL, puedan preparar los datos a escala de nube de forma iterativa.
La característica Power Query usa una interfaz de tipo de cuadrícula para la preparación de datos básica que tiene el aspecto de Excel, conocida como editor de mashups en línea. El editor también permite a los usuarios más avanzados realizar una preparación de datos más compleja mediante fórmulas. Primero debe crear un servicio vinculado a un origen de datos para poder acceder a los datos.
Las fórmulas funcionan con Power Query Online y ponen las funciones de Power Query M a disposición de los usuarios de Data Factory. Power Query traduce el lenguaje M generado por el editor de mashups en línea en el código de Spark para la ejecución a escala de la nube.
Esta funcionalidad permite a los ingenieros y analistas de datos explorar y preparar los conjuntos de datos de forma interactiva. Además, pueden trabajar de forma interactiva con el lenguaje M y obtener una vista previa del resultado antes de verlo en el contexto de una canalización más amplia.
Para agregar una actividad de Power Query en Azure Data Factory, haga clic en el icono del signo más y seleccione Power Query en el panel de recursos de fábrica.

Agregue un conjunto de datos de origen para el flujo de datos de limpieza y transformación y seleccione un conjunto de datos de receptor. Se admiten los siguientes orígenes de datos.
| Conector | Formato de datos | Tipo de autenticación |
|---|---|---|
| Azure Blob Storage | CSV, Parquet | Clave de cuenta |
| Azure Data Lake Storage Gen1 | CSV | Entidad de servicio |
| Azure Data Lake Storage Gen2 | CSV, Parquet | Clave de cuenta, Entidad de servicio |
| Azure SQL Database | Autenticación SQL | |
| Azure Synapse Analytics | Autenticación SQL |
Una vez que haya seleccionado un origen, haga clic en Crear.

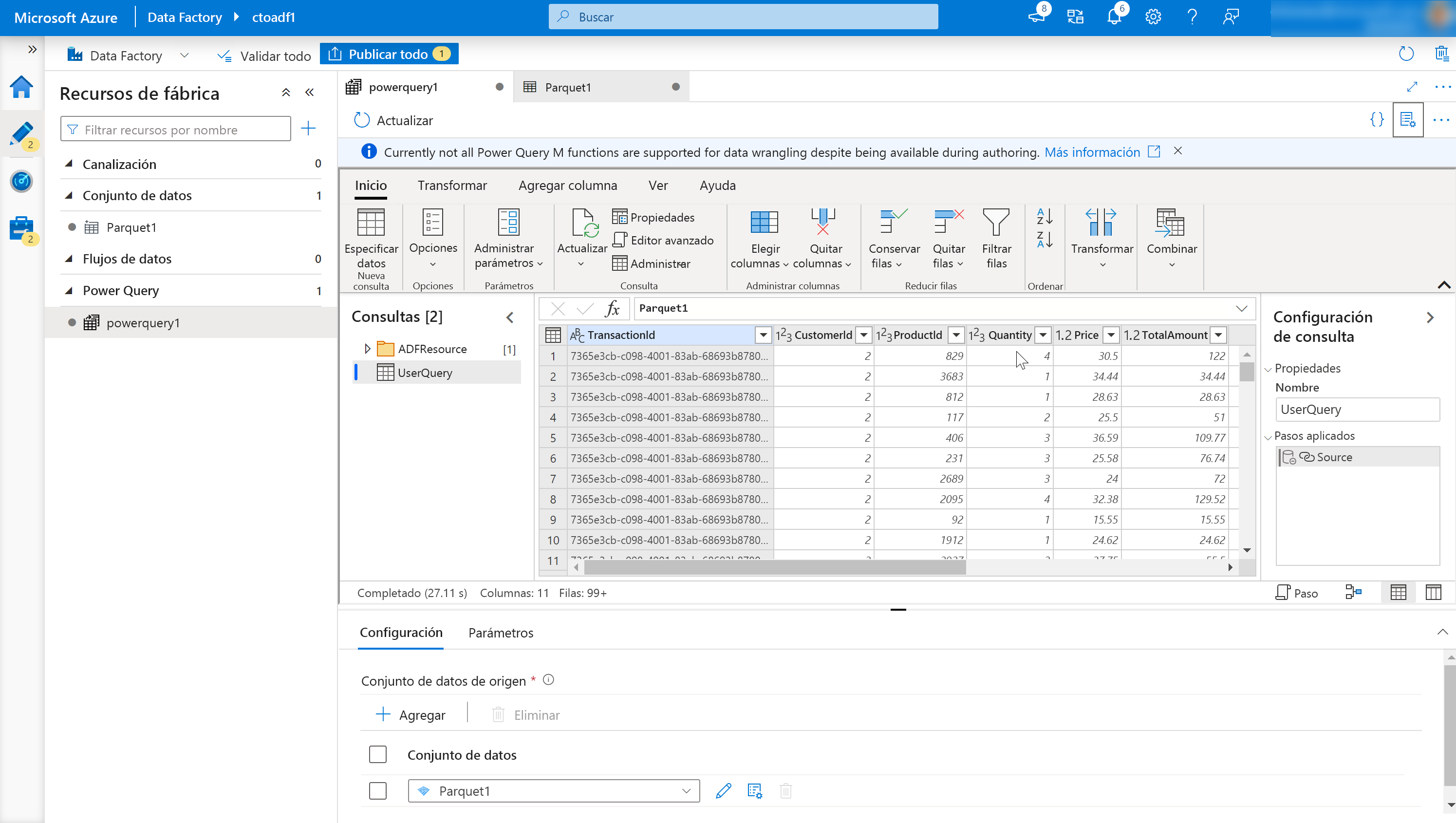
Se abrirá el editor de mashups en línea.

Este consta de los siguientes componentes:
Lista de conjuntos de datos.
Proporciona los conjuntos de datos que se han definido como origen de la limpieza y transformación de datos.
Barra de herramientas de la función de limpieza y transformación.
La barra de herramientas contiene varias funciones de limpieza y transformación de datos a las que el usuario puede acceder para manipular los datos, entre las que se incluyen:
- Administrar columnas.
- Transformar tablas.
- Reducir filas.
- Agregar columnas.
- Combinar tablas.
Cada elemento es contextual y contiene funciones secundarias específicas.
Encabezados de columna.
Además de tener la capacidad de cambiar el nombre de las columnas, al hacer clic con el botón derecho en la columna se mostrarán elementos contextuales para administrar las columnas.
Configuración.
Esto le permite agregar o modificar orígenes de datos y receptores de datos, y modificar la configuración de la tarea de datos de limpieza y transformación.
Ventana de pasos.
En esta ventana se muestran los pasos que se han aplicado a la salida de limpieza y transformación. En el ejemplo del gráfico, se ha aplicado el paso denominado "Origen" a la salida de limpieza y transformación denominada "UserQuery".
Lista de resultados de Power Query.
Muestra la salida de la limpieza y transformación de datos que se ha definido.
Botón Publicar.
Permite publicar el trabajo que se ha creado.
Una tarea de Power Query se puede agregar en el diseñador del lienzo de la misma forma que una tarea de actividad de copia o una tarea de flujo de datos de asignación y se puede administrar y supervisar de la misma manera.
