Informática sin servidor
En los primeros días de la informática en la nube, los proveedores de servicios en la nube como Amazon y Microsoft se centraban en ofrecer a los clientes una amplia variedad de servicios IaaS. Esto impulsó el crecimiento de las nubes públicas, ya que permitía a los clientes trasladar con relativa facilidad a máquinas virtuales en la nube las cargas de trabajo que se ejecutaban de forma local en servidores físicos o en máquinas virtuales. Pero IaaS conlleva responsabilidades. Una organización que pone en marcha una máquina virtual en la nube asume también la responsabilidad de mantener lo que se encuentra dentro de la máquina virtual: el sistema operativo, los tiempos de ejecución necesarios, las aplicaciones que usan esos tiempos de ejecución, etc.
PaaS no solo traslada parte de esa responsabilidad al proveedor de servicios en la nube, sino que ha impulsado todavía más inversiones en la nube. Con servicios como AWS Elastic Beanstalk y Azure App Service, los clientes pueden aprovisionar servidores web virtuales equipados con tiempos de ejecución populares (como Java, Node.js y Microsoft .NET) y hacer que el software se ejecute en ellos en cuestión de minutos. Aunque las máquinas virtuales son las que se encargan del trabajo pesado en segundo plano, su presencia se abstrae en gran medida. PaaS permite a los clientes centrarse en las aplicaciones que escriben para resolver los problemas empresariales, en lugar de dedicar ciclos a administrar las máquinas virtuales y mantener actualizadas las plataformas.
La informática sin servidor es una innovación relativamente reciente en la informática en la nube que lleva esas abstracciones aún más lejos. Supongamos que su organización escribe y mantiene código que realiza copias de seguridad nocturnas de datos críticos, ejecuciones de facturación semanales o transmisiones de pagos electrónicos cada vez que se carga una factura en el almacenamiento en la nube. En este caso, el objetivo general es ejecutar este código en el momento adecuado. Todo lo demás es secundario, incluido el lugar en el que se almacena el código y cómo y dónde se ejecuta.
Podría adoptar un enfoque de IaaS si crea una o varias máquinas virtuales para ejecutar el código e instalar las plataformas y bibliotecas necesarias. Puede aprovisionar una instancia de Elastic Beanstalk o App Service y hospedar ahí el código, o bien usar un tiempo de ejecución de función (como AWS Lambda o Azure Functions) para ejecutar el código siempre que quiera, independientemente de dónde o cómo se hospede. AWS Lambda y Azure Functions son dos ejemplos de informática sin servidor (más concretamente, de funciones sin servidor), al igual que Google Cloud Functions. Los tres representan el siguiente paso en la evolución natural de la informática en la nube, de la fase de IaaS, donde toda la responsabilidad recae en usted, a la fase sin servidor, donde puede centrarse en las acciones que quiere realizar (el código que quiere ejecutar) en la nube y dejar que el proveedor de servicios en la nube administre todo lo demás.
Las funciones sin servidor que se ejecutan mediante tiempos de ejecución de la función en la nube son la forma más habitual de informática sin servidor, pero no la única. Amazon, Microsoft y Google ofrecen versiones sin servidor de algunos de sus otros servicios de PaaS, incluidas bases de datos sin servidor. Algunos proveedores ofrecen compatibilidad con flujos de trabajo sin servidor, que permiten definir flujos de trabajo empresariales en la nube y ejecutarlos en respuesta a eventos externos, como las facturas que se cargan en el almacenamiento en la nube, los temporizadores que se activan a intervalos especificados o los correos electrónicos que llegan a una bandeja de entrada, a menudo sin necesidad de escribir una sola línea de código. Por último, muchos de los servicios de contenedor que ofrecen los proveedores de servicios en la nube, incluidos Azure Container Instances y AWS Elastic Container Service, se consideran ejemplos de informática sin servidor, ya que permiten ejecutar contenedores en la nube al mismo tiempo que abstraen la infraestructura subyacente.
Ventajas de la informática sin servidor
La informática sin servidor ofrece tres grandes ventajas a las organizaciones que aprovechan la informática en la nube:
Costes informáticos inferiores: normalmente, los clientes pagan cargos mensuales por las máquinas virtuales de IaaS y los servicios PaaS, como Elastic Beanstalk y Azure App Service. La facturación continúa incluso si los servicios están inactivos. En cambio, la mayoría de los servicios de informática sin servidor admiten precios por consumo, en los que solo se cobra por el tiempo que se ejecute el código. Imagine que dedica una máquina virtual de 100 dólares al mes a ejecutar código que realiza una copia de seguridad nocturna de datos críticos y que el código se ejecuta durante 30 minutos cada noche. Está pagando 100 dólares al mes por ejecutar el código durante 1/48 de un mes, o menos de un día. La implementación del mismo código como una función sin servidor podría costar tan solo unos dólares al mes. Con los precios por consumo, no paga por el tiempo de inactividad.
Escalabilidad automática: los proveedores de servicios en la nube ofrecen mecanismos para escalar servicios IaaS en productos como AWS Auto Scaling y conjuntos de escalado de máquinas virtuales de Azure. También proporcionan opciones de escalado manual y automático para servicios PaaS. Pero incluso si el escalado se realiza de forma automática, el administrador de la nube tiene que habilitar el escalado automático y configurarlo para que el proveedor de servicios en la nube sepa cómo y cuándo se debe realizar el escalado. Una de las consideraciones subyacentes que deben tener en cuenta los administradores es que, dado que se paga por instancias individuales de servicios IaaS y PaaS, conviene configurar el servicio para que escale lo suficiente, no demasiado. La informática sin servidor ofrece la opción de realizar un escalado horizontal de forma transparente y automática para satisfacer un aumento de la demanda y efectuar una reducción horizontal cuando la demanda disminuye. Normalmente, la única configuración que lleva a cabo un administrador de la nube consiste en habilitar esta opción en el servicio. Si recibe 100 solicitudes al mismo tiempo para ejecutar una función sin servidor, el proveedor de servicios en la nube se asegurará de que las solicitudes se puedan ejecutar en paralelo (o en su mayor parte en paralelo). Esto no repercutirá en el coste porque, gracias a los precios por consumo, cuesta lo mismo ejecutar una función 100 veces, independientemente de si la ejecución es en serie o en paralelo.
Reducción de los costes administrativos: la informática sin servidor le permite centrarse en la ejecución del código y los flujos de trabajo y delegar en el proveedor de servicios en la nube la responsabilidad de todo lo demás, incluido el mantenimiento de la plataforma subyacente.
Aun así, la informática sin servidor también tiene desventajas. A continuación se indican algunas de las limitaciones que se deben tener en cuenta:
Algunos tiempos de ejecución de la función imponen un límite en la cantidad de tiempo que puede ejecutarse una función.
Algunos tiempos de ejecución de la función no garantizan que una función se ejecute de inmediato, a menos que esté dispuesto a pagar más para que suceda. Por ejemplo, si tiene Azure Functions configurado para usar precios basados en el consumo, una función podría no ejecutarse hasta 10 minutos después de desencadenarse. Esto podría no ser un problema para una copia de seguridad nocturna, ya que probablemente no le importe si la copia de seguridad se ejecuta a la 1:00 o a la 1:10, pero podría ser un factor conflictivo para las funciones críticas en el tiempo, esto es, aquellas que deben ejecutarse en tiempo real (o casi real).
Las funciones sin servidor no suelen tener estado, es decir, no pueden almacenar datos internamente y esperan que se conserven de una invocación de función a otra. Pueden usar servicios externos de almacenamiento en la nube, como Amazon S3 y Azure Storage, para conservar datos entre llamadas, pero esto hace que el código de la función sea más complejo.
Algunos proveedores de servicios en la nube ofrecen compatibilidad con funciones con estado (en Azure se llaman Durable Functions), pero las funciones que conservan el estado son una adición relativamente reciente a la informática sin servidor y no se admiten universalmente.
Funciones sin servidor
El ejemplo más común de informática sin servidor son las funciones sin servidor. El código se carga en la nube y se le indica cuándo debe ejecutarse. El código puede estar escrito en diversos lenguajes, incluidos Java y C#.
En la figura 11 se enumeran los lenguajes de programación que las funciones sin servidor admiten en Azure, AWS y GCP en el momento de redactar este documento:
| Lenguaje | Azure Functions | AWS Lambda | Google Cloud Functions |
|---|---|---|---|
| C# | x | x | |
| F# | x | ||
| Go | x | x | |
| Java | x | x | |
| JavaScript (Node.js) | x | x | x |
| PowerShell | x | x | |
| Python | x | x | x |
| Ruby | x | ||
| TypeScript | x |
Figura 11: Lenguajes de programación admitidos por populares entornos de ejecución de funciones sin servidor.
Al crear una función y proporcionar el código que ejecutará, también debe identificar el evento externo que provoca la ejecución de la función. Las plataformas en la nube más populares admiten desencadenadores de varios tipos, incluidos los temporizadores, los eventos que ocurren en otros servicios en la nube (como un documento que se carga en el almacenamiento en la nube) y las llamadas HTTP. Simplemente se debe cargar el código de facturación en un tiempo de ejecución de función y configurarlo para que se ejecute una vez al día, a la semana o al mes. Es igualmente sencillo activar una función cada vez que se carga una factura en el almacenamiento en la nube (por ejemplo, Amazon S3 o Azure Storage) o siempre que se realiza una llamada a un punto de conexión REST asociado a la función.
Las funciones sin servidor suelen usarse para llevar a cabo tareas independientes, como la facturación y las copias de seguridad nocturnas. También se usan para conectar otros servicios en la nube y construir soluciones enriquecidas mediante el uso de servicios en la nube como bloques de creación. En la figura 12 puede verse una solución de este tipo que se usa para combinar varios servicios de Azure para supervisar la actividad de los osos polares en el Ártico. En la arquitectura, la función de Azure desempeña un papel fundamental, ya que toma la salida de Azure Stream Analytics (desencadenada por una llamada HTTP), recupera una foto de Azure Blob Storage y la envía a un modelo entrenado con Azure Custom Vision Service, que usa inteligencia artificial para determinar si en la foto aparece un oso polar. La función es el aglutinador que enlaza Stream Analytics, Blob Storage y Custom Vision Service.
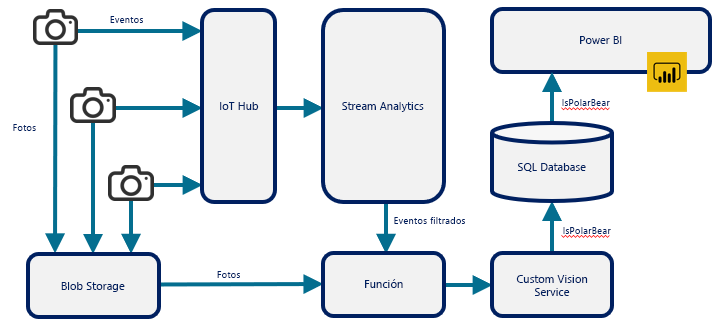
Figura 12: Uso de una función de Azure para conectar otros servicios de Azure.
Flujos de trabajo sin servidor
Algunos servicios de informática sin servidor permiten a los clientes automatizar los flujos de trabajo empresariales sin necesidad de escribir código para hacerlo. Por ejemplo, Azure Logic Apps ofrece más de 100 conectores integrados para interactuar con orígenes de datos, que van desde bases de datos de Oracle a servicios de redes sociales, como X. Proporcionan desencadenadores que permitena definir cuándo se deben ejecutar flujos de trabajo (por ejemplo, cuando se carga un archivo en Box.com o cuando se escribe un tweet con un hashtag especificado). También proporcionan cientos de acciones predefinidas, que establecen lo que ocurre cuando se activa un desencadenador y que se pueden encadenar entre sí para formar flujos de trabajo complejos, y condiciones que permiten realizar acciones de forma condicional. Además, son infinitamente extensibles porque una de las acciones que admite Azure Logic Apps es llamar a una función de Azure. Si un flujo de trabajo incluye una lógica personalizada que no está encapsulada en una acción, puede proporcionar el código que implementa esa lógica e incluirlo en el flujo de trabajo como si fuera una acción predefinida.
La figura 13 muestra un flujo de trabajo de este tipo en el diseñador de Azure Logic Apps1. Cuando llega un correo electrónico, la aplicación de Logic Apps entra en acción y comprueba si contiene datos adjuntos y una frase clave en la línea de asunto del correo electrónico. Si se cumplen ambas condiciones, la aplicación de Logic Apps invoca una función de Azure para quitar todo el código HTML del cuerpo del correo electrónico. Después, deposita el correo electrónico saneado y los datos adjuntos que lo acompañan en Azure Blob Storage y envía un correo electrónico con vínculos a los documentos correspondientes en Blob Storage, para notificar a las partes interesadas que la información está disponible y en espera de revisión. En este ejemplo se combinan dos paradigmas sin servidor: una aplicación de Logic Apps que ejecuta acciones sin código (por lo menos, no un código que haya escrito usted u otra persona de la organización) y una función de Azure que contiene el código que ha proporcionado para personalizar el flujo de trabajo. Resulta muy ilustrativo del cambio que se está produciendo en la informática en la nube, de máquinas virtuales manuales a abstracciones de nivel superior que permiten a las organizaciones centrar su esfuerzos en resolver problemas empresariales, en lugar de administrar máquinas virtuales e instalar y mantener tiempos de ejecución.
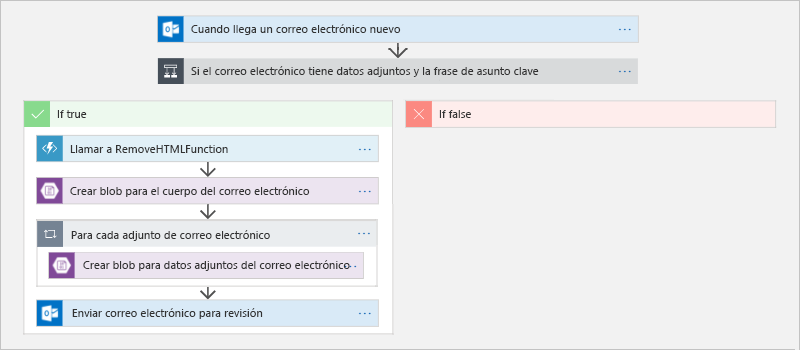
Figura 13: Definición de un flujo de trabajo en Azure Logic Apps.
Amazon ofrece un servicio similar con AWS Step Functions. Gracias a Step Functions, puede crear flujos de trabajo visuales que combinen otros servicios, como AWS Lambda y AWS ECS. Los flujos de trabajo constan de una serie de pasos, en los que la salida de un paso sirve de entrada para el siguiente. Al igual que Azure Logic Apps, AWS Step Functions proporciona primitivas para la bifurcación y la ejecución en paralelo, lo que evita tener que escribir código para hacerlo. De hecho, un flujo de trabajo empresarial se convierte en un diagrama de máquina de estados que es fácil de entender, de modificar y de explicar a otras personas.
Bases de datos sin servidor
En los primeros días de la informática en la nube, el hecho de hospedar una base de datos en la nube conllevaba aprovisionar una máquina virtual e instalar un producto de base de datos como MySQL, PostgreSQL o SQL Server. PaaS ha cambiado este proceso, ya que ofrece bases de datos como servicio. Con Azure SQL Database o Amazon Relational Database Service (RDS), por ejemplo, basta con aprovisionar una instancia para tener en cuestión de minutos una base de datos hospedada en la nube lista para atender a los clientes. Además, el proveedor de servicios en la nube mantiene actualizada la plataforma de base de datos, ya que aplica revisiones y actualizaciones de software.
Una innovación más reciente en la informática en la nube son las bases de datos sin servidor, que ofrecen un modelo optimizado con una buena relación de precio y rendimiento que resulta ideal para las bases de datos únicas con patrones de uso irregulares. Azure, por ejemplo, ofrece una versión sin servidor de Azure SQL Database. Con la versión estándar de Azure SQL Database, puede elegir un nivel de precio y rendimiento en función de la carga máxima que espera que administre la base de datos. Si las cargas tienen picos o son intermitentes, a menudo acaba pagando como si la base de datos experimentara grandes cargas en todo momento.
Para mitigarlo, la versión sin servidor de Azure SQL Database escala la base de datos según sea necesario para controlar las cargas que encuentra, con costos basados en la suma de los costos de proceso y de almacenamiento. Al igual que sucede con las funciones sin servidor que usan un modelo de consumo, solo se paga por lo que se usa. Amazon ofrece un servicio similar con AWS Aurora Serverless, que es una versión sin servidor del servicio de base de datos Aurora de Amazon, mientras que Google ofrece a sus clientes un servicio de base de datos NoSQL sin servidor, conocido como Google Cloud Firestore.
Referencias
- Microsoft (2019). Automatización del control de correos electrónicos y datos adjuntos con Azure Logic Apps. https://learn.microsoft.com/azure/logic-apps/tutorial-process-email-attachments-workflow.