Escalado automático en la nube
Los administradores de la nube pueden llevar a cabo de forma manual el escalado vertical u horizontal para controlar el aumento de la demanda, así como la reducción horizontal o vertical para minimizar los costes cuando la demanda disminuye. Por ejemplo, un administrador observador puede detectar que la demanda está aumentando y usar las herramientas que proporcionan los proveedores de servicios en la nube para poner en línea máquinas virtuales adicionales (escalado horizontal) o reemplazar las máquinas virtuales existentes por otras más grandes que tengan más CPU y más memoria (escalado vertical). En este caso, la palabra clave es "observador". Si se produce un pico en la demanda y nadie se da cuenta, todo el sistema se ralentizará e incluso dejará de responder a los usuarios finales. Por otro lado, si se lleva a cabo un escalado vertical u horizontal para controlar cargas más intensas y dicho escalado no se revierte cuando la carga disminuye, al final se pagará por recursos que no se necesitan.
Esta es la razón por la que las plataformas en la nube más populares ofrecen mecanismos de escalado automático para escalar los recursos en respuesta a la fluctuación de la demanda sin intervención humana. Básicamente, hay dos formas de enfocar el escalado automático:
Basado en el tiempo: los recursos se escalan según una programación predeterminada. Por ejemplo, si el sitio web de la organización experimenta las cargas más altas durante el horario laboral, debe configurar el escalado automático de modo que los recursos se escalen vertical u horizontalmente a las 8:00 todas las mañanas y se reduzcan vertical u horizontalmente a las 17:00 todas las tardes. El escalado basado en el tiempo se denomina a veces escalado programado.
Basado en métricas: si las cargas son menos predecibles, escale los recursos en función de métricas predefinidas, como el uso de la CPU, la presión de memoria o el tiempo de espera medio de la solicitud. Por ejemplo, si el uso medio de la CPU alcanza el 70 %, ponga en línea automáticamente máquinas virtuales adicionales y, cuando vuelva a reducirse a un 30 %, desaprovisione las máquinas virtuales adicionales.
Tanto si decide realizar el escalado en función del tiempo, de las métricas o de ambos, el escalado automático se basa en las reglas de escalado o las directivas de escalado que haya configurado el administrador de la nube. Las plataformas en la nube modernas admiten reglas de escalado simples (por ejemplo, expandir dos instancias a cuatro cada día a las 8:00 y revertirlas de nuevo a dos a las 17:00) y complejas (por ejemplo, aumentar en uno el número de máquinas virtuales si el uso máximo de CPU supera el 70 % o si el tiempo de espera medio de la solicitud alcanza los cinco segundos). Por lo general, el administrador de la nube deberá experimentar para encontrar la combinación correcta de reglas.
Los grandes proveedores de servicios en la nube, incluidos Amazon, Microsoft y Google, admiten el escalado automático. Se puede aplicar AWS Auto Scaling a instancias de EC2, tablas de DynamoDB y otros servicios en la nube de AWS. Azure ofrece opciones de escalado automático para servicios clave, como App Service y Virtual Machines. Google también lo hace para Google Compute Engine y Google App Engine.
En general, los servicios de escalado automático se reducen y escalan horizontalmente, en lugar de verticalmente, en parte porque el escalado y la reducción verticales obligan a reemplazar una instancia por otra, lo que conlleva inevitablemente un tiempo de inactividad mientras se crean las instancias y se ponen en línea.
Escalado automático basado en el tiempo
El escalado automático basado en el tiempo es adecuado cuando las cargas fluctúan de una manera predecible. Por ejemplo, los sistemas de TI de muchas organizaciones experimentan la mayor carga durante el horario laboral y pueden registrar una carga reducida o inexistente a altas horas de la madrugada. El sitio web de Domino's Pizza puede experimentar cargas a todas horas del día, ya que opera más de 16 000 establecimientos en casi 100 países o regiones. Aun así, experimenta de forma previsible cargas más altas de lo normal en determinadas épocas del año.
En ambos casos, el escalado automático basado en el tiempo es una opción ideal. En la figura 7 se muestra cómo se aplica en Azure el escalado automático programado. En este ejemplo, un administrador de la nube configura una instancia de Azure App Service que hospeda el sitio web de la organización para que ejecute dos instancias de forma predeterminada, pero escala hasta cuatro instancias entre las 6:00 y las 18:00 seis días a la semana, sin incluir el domingo. Al seleccionar la opción "Especifique las fechas de inicio y finalización", el administrador podría configurar fácilmente App Service para que escale horizontalmente a 10 instancias el domingo en el que se celebra la Super Bowl. También podría definir varias condiciones de escalado para escalar horizontalmente en otras fechas.
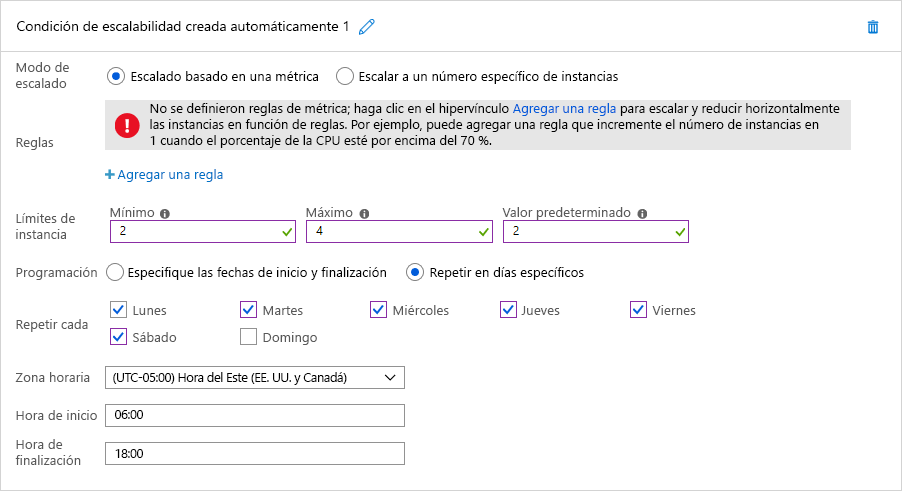
Figura 7: Escalado automático programado en Azure.
Escalado automático basado en métricas
El escalado basado en métricas como el uso de CPU y el tiempo de espera medio de la solicitud es adecuado cuando las cargas son menos predecibles. La supervisión es un elemento fundamental para llevar a cabo un escalado automático eficaz de los recursos en función de las métricas de rendimiento, ya que permite que el escalador automático sepa cuándo realizar el escalado. Gracias a la supervisión, se puede efectuar un análisis de los patrones de tráfico o del uso de recursos para valorar de manera fundamentada cuándo y cuánto se deben escalar los recursos a fin de maximizar la calidad del servicio y minimizar el coste.
Para desencadenar el escalado de los recursos, se supervisan diversos aspectos. La métrica más común es el uso de recursos. Por ejemplo, un servicio de supervisión puede realizar un seguimiento del uso de CPU de cada nodo de recursos y escalar los recursos si el uso es excesivo o demasiado bajo. Si, por ejemplo, el uso de cada recurso es superior al 90 %, probablemente sea recomendable agregar más recursos, ya que el sistema está sobrecargado. Normalmente, para decidir cuáles son estos factores desencadenantes, los proveedores de servicios analizan el punto de interrupción de los nodos de recursos, así como el momento en que empezarán a producirse errores, y asignan su comportamiento en varios niveles de carga. Aunque por motivos de coste es importante maximizar el uso de todos los recursos, es aconsejable dejar un margen para que el sistema operativo permita actividades de sobrecarga. Del mismo modo, si el uso está por debajo de, por ejemplo, un 30 %, es posible que no se requieran todos los nodos de recursos y que algunos puedan desaprovisionarse.
En la práctica, los proveedores de servicios normalmente suelen supervisar una combinación de varias métricas diferentes de un nodo de recursos para evaluar cuándo se deben escalar los recursos. Algunos de estas incluyen el uso de CPU, el consumo de memoria, el rendimiento y la latencia. AWS usa CloudWatch para supervisar los recursos de EC2 y proporcionar métricas de escalado (figura 8). CloudWatch realiza un seguimiento de las métricas de todas las instancias de EC2 en un grupo de escalado y emite una alarma cuando una métrica específica cruza un umbral (por ejemplo, cuando el uso de CPU supera el 70 %). Después, AWS aumenta o disminuye el recuento de instancias de EC2 en función de las directivas de escalado que haya configurado el administrador.
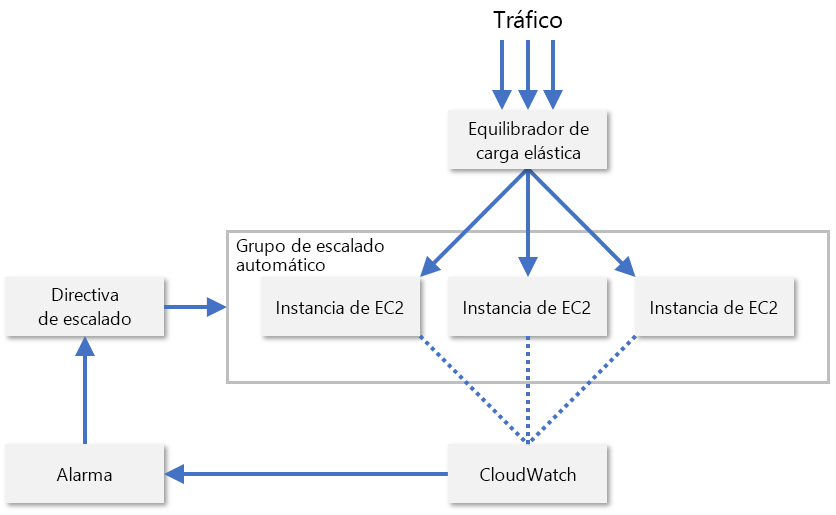
Figura 8: Escalado automático de instancias de EC2 en AWS.
AWS también admite el escalado predictivo, que usa el aprendizaje automático para prever patrones de tráfico y administrar los recuentos de instancias en consecuencia. El objetivo consiste en escalar los recursos de nube de forma inteligente, sin necesidad de que un administrador de la nube configure reglas de escalado automático. Los principales proveedores de servicios en la nube buscan continuamente nuevas formas de mejorar sus plataformas con el aprendizaje automático. Microsoft, por ejemplo, usa actualmente el aprendizaje automático para mejorar la resistencia de Azure Virtual Machines mediante la predicción y la mitigación proactivas de errores en las VM1.
Referencias
- Microsoft (2018). Mejora de la resistencia de Azure Virtual Machines con el aprendizaje automático predictivo y la migración en vivo. https://azure.microsoft.com/blog/improving-azure-virtual-machine-resiliency-with-predictive-ml-and-live-migration/.