Escalado de recursos de proceso
Una de las principales ventajas de la nube es la capacidad de escalar recursos a un sistema a petición. El escalado vertical (aprovisionamiento de recursos más grandes) o el escalado horizontal (aprovisionamiento de recursos adicionales) pueden ayudar a reducir la carga en un sistema mediante la disminución del uso como resultado de una mayor capacidad o de una distribución más amplia de la carga de trabajo.
El escalado puede ayudar a mejorar la capacidad de respuesta (y los resultados percibidos desde el punto de vista del usuario) al aumentar el rendimiento, ya que permite atender un mayor número de solicitudes. Esto también puede ayudar a reducir la latencia durante las cargas máximas, dado que solo se pone en la cola un número reducido de solicitudes durante las cargas máximas en un único recurso. Además, el escalado puede mejorar la fiabilidad del sistema al reducir el uso de recursos y evitar que se acerque al punto de interrupción.
Es importante tener en cuenta que, aunque la nube permite aprovisionar fácilmente recursos más nuevos o mejores, el coste es siempre un factor que se debe valorar. Por lo tanto, aunque es beneficioso escalar vertical u horizontalmente, también es importante reconocer cuándo conviene reducir vertical u horizontalmente para ahorrar costes.
Escalado horizontal (reducción y escalado horizontales)
El escalado horizontal es una estrategia mediante la cual se agregan recursos adicionales al sistema o se quitan recursos superfluos a lo largo del tiempo. Este tipo de escalado es beneficioso para el nivel de servidor cuando la carga en el sistema fluctúa de forma incoherente o impredecible. La naturaleza de la carga fluctuante hace que sea esencial aprovisionar la cantidad correcta de recursos para administrar la carga en todo momento.
Algunas consideraciones que hacen que esta tarea sea compleja:
- El tiempo de activación de una instancia (por ejemplo, una máquina virtual)
- El modelo de precios del proveedor de servicios en la nube
- La pérdida potencial de ingresos debida a la degradación de la calidad del servicio (QoS) al no escalar horizontalmente a tiempo.
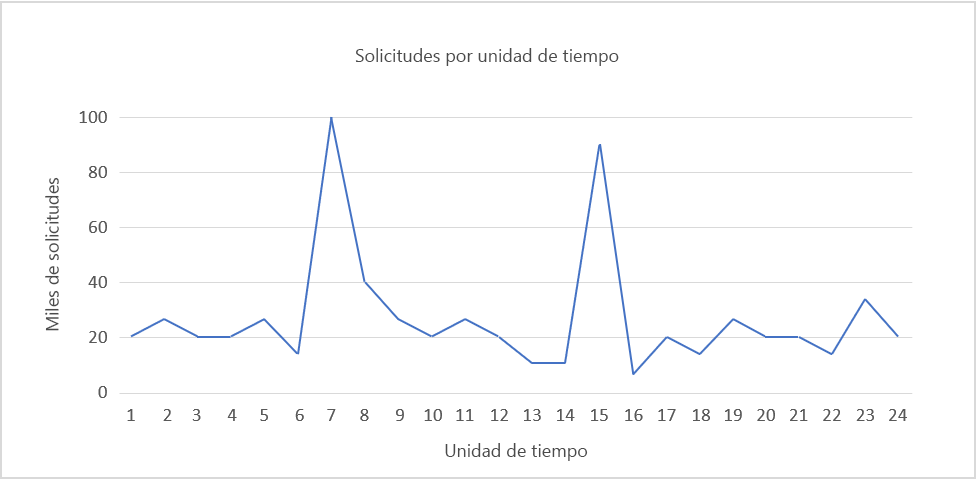
Figura 5: Ejemplo de modelo de carga.
Como ejemplo, fíjese en el modelo de carga indicado más arriba en la figura 5.
Imaginemos que usamos Amazon Web Services, que cada unidad de tiempo equivale a una hora del tiempo real y que necesitamos un servidor que atienda 5000 solicitudes. La demanda alcanza un pico entre las unidades de tiempo 6 y 8 y entre las unidades de tiempo 14 y 16. Fijémonos por ejemplo en este último caso. Podemos detectar un descenso en la demanda en torno a la unidad de tiempo 16 y empezar a reducir el número de recursos asignados. Dado que pasamos de cerca de 90 000 solicitudes a 10 000 en el transcurso de tres horas, matemáticamente podemos ahorrar el coste de una docena de instancias adicionales o más que estarían conectadas en la unidad de tiempo 15.
En la figura 6 se muestra un modelo de escalado que ajusta el recuento de instancias sobre la marcha para que coincida con el modelo de carga, con los recuentos de instancias en rojo. Durante los períodos de máxima demanda, el número de instancias se escala horizontalmente a 20 y 18 respectivamente a fin de proporcionar los recursos necesarios para controlar el tráfico. En otras ocasiones, el recuento de instancias se reduce (reducción horizontal) para mantener el uso de recursos relativamente constante. Si damos por hecho que cada instancia cuesta 20 céntimos por hora, el coste de mantener 20 instancias en ejecución durante 24 horas es 96 dólares. El escalado del recuento de instancias como se muestra en la imagen reduce el coste a unos 42 dólares, lo que supone un ahorro anual de más de 15 000 dólares al año. No cabe duda de que se trata de una cantidad de dinero considerable para prácticamente cualquier presupuesto de TI.
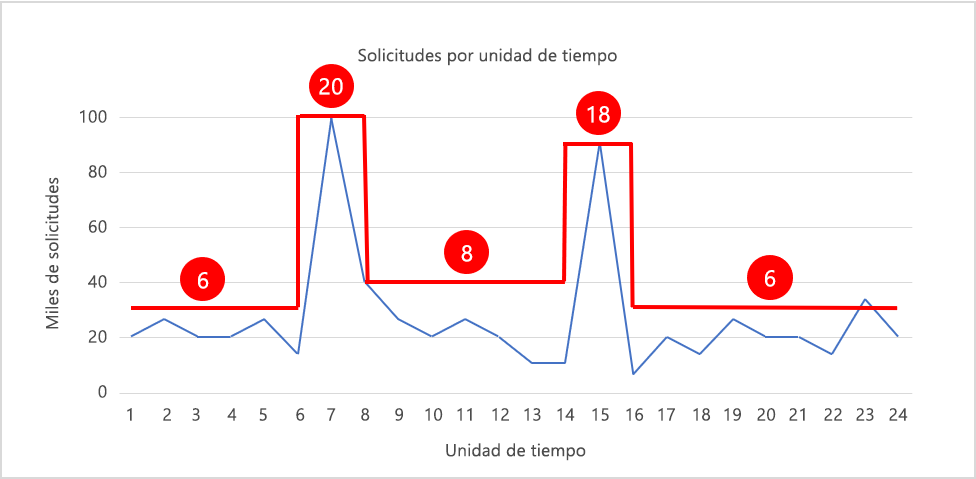
Figura 6: Reducción y escalado horizontales según la demanda.
El escalado depende de las características del tráfico y de la carga subsiguiente que se genera en un servicio web. Si el tráfico sigue un patrón predecible (por ejemplo, basado en el comportamiento humano, como el streaming de películas desde un servicio web por la noche), el escalado puede ser predictivo para mantener la calidad del servicio. Pero en muchos casos, el tráfico no se puede predecir y los sistemas de escalado deben ser reactivos en función de diferentes criterios.
Hay que tener en cuenta que la reducción y el escalado horizontales se pueden realizar con instancias de contenedor, así como con instancias de máquina virtual. Tradicionalmente, las cargas de trabajo se ejecutaban en la nube en máquinas virtuales, pero cada vez es más común que se ejecuten en contenedores. El escalado se consigue con cargas de trabajo basadas en máquinas virtuales mediante el aumento y la reducción del número de máquinas virtuales. Del mismo modo, las cargas de trabajo basadas en contenedores se pueden escalar si se varía el número de contenedores. Dado que los contenedores tienden a iniciarse más rápidamente que las máquinas virtuales, la elasticidad es ligeramente mayor, ya que las nuevas instancias de contenedor se pueden poner en línea en menos tiempo que las instancias de máquina virtual.
Escalado vertical (escalado y reducción verticales)
El escalado horizontal es una manera de lograr elasticidad, pero no la única. Imagine que el tráfico a su sitio web rara vez supera las 15 000 solicitudes por unidad de tiempo y que aprovisiona una única instancia grande que puede controlar 20 000, lo suficiente para servir el tráfico normal relativamente bien y tener en cuenta también los picos menores. Si la carga en el sitio web aumenta, puede acomodar de forma razonable el incremento del tráfico si reemplaza la instancia de servidor por otra que tenga el doble de núcleos de CPU y el doble de RAM. Esto se denomina escalado vertical.
El principal desafío del escalado vertical es que el cambio suele tardar un tiempo, que podría considerarse tiempo de inactividad. Esto se debe a que, para poder trasladar todas las operaciones de la instancia más pequeña a una más grande, aunque el cambio solo tarde unos minutos, la calidad del servicio se degrada durante el intervalo.
Otra limitación del escalado vertical es la granularidad reducida. Si tiene 10 instancias de servidor en línea y necesita aumentar temporalmente la capacidad en un 10 %, puede escalar horizontalmente de 10 instancias a 11 y obtener el resultado deseado. En cambio, con el escalado vertical, el siguiente tamaño más grande de instancia suele tener aproximadamente el doble de capacidad de la anterior, que sería el equivalente del escalado horizontal de 10 instancias a 20 solo para acomodar un aumento del tráfico del 10 %. Esto es menos rentable que el escalado horizontal.
Una consideración final que se debe tener en cuenta sobre el escalado vertical es la disponibilidad. Si tiene una instancia grande que atiende a todos los clientes de un sitio web y dicha instancia deja de funcionar, el sitio web también dejará de funcionar. En cambio, si aprovisiona 10 instancias pequeñas para controlar la misma carga y una de ellas deja de funcionar, es posible que los usuarios perciban una ligera disminución del rendimiento, pero todavía podrán acceder al sitio. Por lo tanto, aunque la carga sea predecible e incremente de forma constante a medida que aumenta la popularidad del servicio, muchos administradores de la nube optan por escalar horizontalmente, en lugar de verticalmente.
Escalado del nivel de servidor
A veces, la escalabilidad tiene más matices que simplemente aprovisionar más recursos (escalado horizontal) o recursos más grandes (escalado vertical). En el nivel de servidor, una mayor demanda puede aumentar la competencia por tipos de recursos específicos, como la CPU, la memoria y el ancho de banda de red. Los proveedores de servicios en la nube suelen ofrecer máquinas virtuales optimizadas para cargas de trabajo que hacen un uso intensivo de los procesos, la memoria y la red. Conocer la carga de trabajo y elegir el tipo de máquina virtual correcta es tan importante como usar más máquinas virtuales o más grandes para resolver el problema. Es mejor tener cinco máquinas virtuales que controlan las cargas de trabajo que hacen un uso intensivo de los procesos que 10, incluso si las máquinas virtuales optimizadas para las cargas de trabajo con un uso intensivo de la CPU cuestan un 20 % más que las máquinas virtuales genéricas.
El aumento de los recursos de hardware no siempre es la mejor solución para aumentar el rendimiento de un servicio. Si se aumenta la eficacia de los algoritmos que emplea el servicio, también se puede reducir la contención de recursos y mejorar el uso, lo que elimina la necesidad de escalar los recursos físicos.
Una consideración importante en lo que se refiere al escalado es la disponibilidad de estados (o su falta). Un diseño de servicio sin estado se presta a una arquitectura escalable. Un servicio sin estado significa básicamente que la solicitud de cliente contiene toda la información necesaria para atender una solicitud del servidor. El servidor no almacena ninguna información relacionada con el cliente en la instancia, pero guarda toda la información relacionada con la sesión en la instancia del servidor.
El hecho de tener un servicio sin estado ayuda a cambiar los recursos a voluntad, sin necesidad de ninguna configuración para mantener el contexto (estado) de la conexión de cliente para las solicitudes posteriores. Si se trata de un servicio con estado, el escalado de recursos requiere una estrategia para transferir el contexto de la configuración existente a la nueva. Tenga en cuenta que existen técnicas para implementar servicios con estado, por ejemplo, mantener una caché de red para que el contexto se pueda compartir entre los servidores.
Escalado de la capa de datos
En las aplicaciones orientadas a datos, donde hay un elevado número de lecturas y de escrituras (o de ambas) en una base de datos o sistema de almacenamiento, el tiempo de ida y vuelta de cada solicitud suele estar limitado por los tiempos de lectura y escritura del disco duro. Las instancias más grandes permiten un mejor rendimiento de E/S, lo que puede mejorar los tiempos de búsqueda en el disco duro y, a su vez, reducir la latencia del servicio. Aunque el hecho de contar con varias instancias de datos en la capa de datos puede mejorar la fiabilidad y la disponibilidad de la aplicación al proporcionar redundancia de conmutación por error, la replicación de los datos en varias instancias ofrece ventajas adicionales, ya que reduce la latencia de red si al cliente lo atiende un centro de datos físicamente más cercano. El particionamiento (o creación de particiones de los datos en varios recursos) es otra estrategia de escalado de datos horizontal, según la cual, en lugar de simplemente replicar los datos entre varias instancias, los datos se dividen en segmentos y se almacenan en varios servidores de datos.
Otro desafío a la hora de escalar la capa de datos consiste en mantener la coherencia (una operación de lectura es igual en todas las réplicas), la disponibilidad (las lecturas y las escrituras se producen siempre correctamente) y la tolerancia a particiones (las propiedades garantizadas del sistema se mantienen cuando los errores impiden la comunicación entre los nodos). Esto suele conocerse como teorema CAP, según el cual, en un sistema de base de datos distribuida, es muy difícil obtener las tres propiedades al completo y, por tanto, puede presentar como mucho una combinación de dos de ellas1.
Referencias
- Wikipedia. Teorema CAP. https://en.wikipedia.org/wiki/CAP_theorem.