Cómo tratar la latencia de cola
Ya se han analizado varias técnicas de optimización que se usan en la nube para reducir la latencia. Algunas de las medidas que se han estudiado incluyen el escalado horizontal o vertical de recursos y el uso de un equilibrador de carga para enrutar las solicitudes a los recursos disponibles más cercanos. En esta página se profundiza en las razones por las que, en una aplicación en la nube o un centro de datos grande, es importante minimizar la latencia de todas las solicitudes y no solo optimizarla para el caso general. Se verá cómo incluso unos pocos valores atípicos de alta latencia pueden degradar significativamente el rendimiento observado de un sistema grande. En esta página también se tratan diversas técnicas para crear servicios que proporcionan respuestas de baja latencia previsibles, incluso si los componentes individuales no lo garantizan. Se trata de un problema que es especialmente importante para las aplicaciones interactivas en las que la latencia deseada para una interacción es inferior a 100 ms.
¿Qué es la latencia de cola?
La mayoría de las aplicaciones en la nube son sistemas distribuidos grandes que a menudo dependen de la paralelización para reducir la latencia. Una técnica común es distribuir una solicitud recibida en un nodo raíz (por ejemplo, un servidor web front-end) en muchos nodos de hoja (servidores de proceso back-end). La mejora del rendimiento está controlada por el paralelismo del cálculo distribuido y, además, por el hecho de que se evitan costos de movimiento de datos extremadamente elevados. Simplemente se mueve el cálculo al lugar donde se almacenan los datos. Por supuesto, cada nodo de hoja funciona simultáneamente en cientos o incluso miles de solicitudes paralelas.
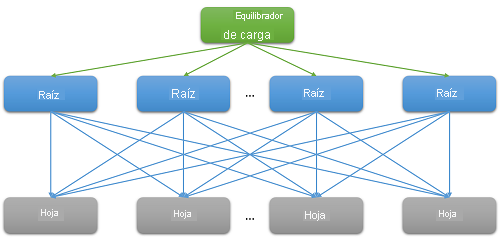
Figura 7: Latencia debida a la escalabilidad horizontal
Considere el ejemplo de búsqueda de una película en Netflix. Cuando un usuario comienza a escribir en el cuadro de búsqueda, se generarán varios eventos paralelos del servidor web raíz. Como mínimo, estos eventos incluyen las siguientes solicitudes:
- Al motor de autocompletar, para predecir realmente la búsqueda que se realiza en función de las tendencias anteriores y el perfil del usuario.
- Al motor de corrección, que encuentra errores en la consulta introducida en función de un modelo de lenguaje que se adapta constantemente.
- Resultados de búsqueda individual para cada una de las palabras que componen una consulta de varias palabras, que deben combinarse en función del rango y la relevancia de las películas.
- Posprocesamiento adicional y filtrado de los resultados para cumplir las preferencias de "búsqueda segura" del usuario.
Estos son algunos ejemplos muy comunes. Se sabe que una única solicitud de Facebook se pone en contacto con miles de servidores Memcached, mientras que una sola búsqueda de Bing suele ponerse en contacto con más de diez mil servidores de indexación.
Obviamente, la necesidad de escalado ha llevado a una gran ramificación en el back-end para cada solicitud individual atendida por el servicio front-end. En el caso de los servicios que deben tener una gran capacidad de respuesta si quieren conservar su base de usuarios, la heurística muestra que la expectativa de respuesta es de 100 ms. A medida que aumenta el número de servidores necesarios para resolver una consulta, el tiempo total suele depender de la respuesta con peor rendimiento de un nodo de hoja a un nodo raíz. Suponiendo que todos los nodos de hoja deben terminar de ejecutarse antes de que se pueda devolver un resultado, la latencia global siempre debe ser mayor que la latencia del componente más lento.
Al igual que la mayoría de los procesos estocásticos, el tiempo de respuesta de un solo nodo de hoja puede expresarse como una distribución. En el caso general, décadas de experiencia han demostrado que la mayoría (> 99 %) de las solicitudes de un sistema en la nube bien configurado se ejecutarán muy rápidamente. Pero es frecuente que haya algún valor atípico en el sistema que se ejecute de manera extremadamente lenta.
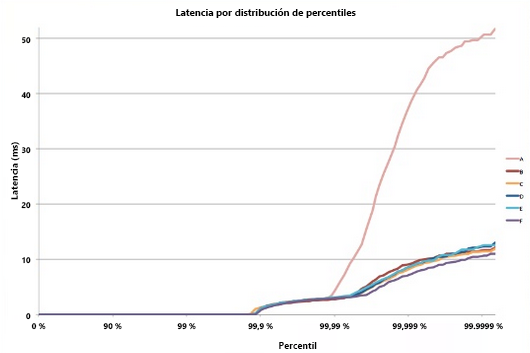
Figura 8: Ejemplo de latencia de cola5
Considere un sistema en el que todos los nodos de hoja tienen un tiempo de respuesta medio de 1 ms, pero hay una probabilidad del 1 % de que el tiempo de respuesta sea mayor que 1000 ms (un segundo). Si cada consulta solo está controlada por un único nodo de hoja, la probabilidad de que la consulta tarde más de un segundo también es de un 1 %. Pero, a medida que aumentamos el número de nodos a 100, la probabilidad de que finalice la consulta en un segundo cae hasta el 36,6 %, lo que significa que hay una probabilidad del 63,4 % de que la duración de la consulta esté determinada por la cola (el 1 % más bajo) de la distribución de la latencia.
$(.99^{100})$
Si se simula esto en una serie de casos, se ve que a medida que aumenta el número de servidores, el impacto de una sola consulta lenta es más pronunciado (observe que el gráfico siguiente se incrementa de forma continua). Además, como la probabilidad de estos valores atípicos disminuye del 1 % al 0,01 %, el sistema es considerablemente inferior.
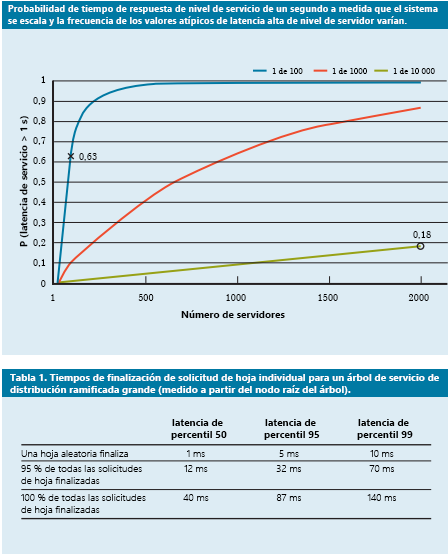
Figura 9: Estudio reciente de probabilidad de tiempo de respuesta que muestra los percentiles 50, 95 y 99 para la latencia de las solicitudes4
Al igual que hemos diseñado nuestras aplicaciones para que sean tolerantes a errores para abordar problemas de confiabilidad de los recursos, ahora debería estar claro por qué es importante que las aplicaciones sean "tolerantes en la cola". Para ello, debemos conocer los orígenes de estas variables de rendimiento largas e identificar mitigaciones siempre que sea posible y soluciones alternativas cuando no lo sea.
Variabilidad en la nube: Orígenes y mitigaciones
Para resolver la variabilidad del tiempo de respuesta que conduce a este problema de latencia de cola, es necesario conocer los orígenes de la variabilidad del rendimiento.1
- Uso de recursos compartidos: Muchas máquinas virtuales (y aplicaciones dentro de esas máquinas virtuales) compiten por un grupo compartido de recursos de proceso. En raras ocasiones, es posible que esta contención provoque una latencia baja en algunas solicitudes. En el caso de tareas críticas, puede tener sentido usar instancias dedicadas y ejecutar periódicamente pruebas comparativas cuando estén inactivas, para asegurarse de que el comportamiento es el adecuado.
- Mantenimiento y daemons en segundo plano: Ya se ha hablado de la necesidad de disponer de procesos en segundo plano para crear puntos de control, crear copias de seguridad, actualizar registros, recopilar elementos no utilizados y controlar la limpieza de recursos. No obstante, esos procesos pueden degradar el rendimiento del sistema mientras se ejecutan. Para mitigar esto, es importante sincronizar las interrupciones debidas a los subprocesos de mantenimiento para minimizar el impacto en el flujo de tráfico. Esto hará que todas las variaciones se realicen en una ventana de tiempo corta y conocida en lugar de aleatoriamente a lo largo de la duración de la aplicación.
- Cola: Otra fuente común de variabilidad es la disparidad de los patrones de llegada del tráfico.1 Esta variabilidad se agrava si el sistema operativo usa un algoritmo de programación distinto de FIFO. Los sistemas Linux suelen programar subprocesos desordenados para optimizar el rendimiento general y maximizar el uso del servidor. Los estudios han puesto de manifiesto que el uso de la programación FIFO en el sistema operativo reduce la latencia de cola a costa de reducir el rendimiento global del sistema.
- Saturación del punto de entrada todos a todos: El patrón que se muestra en la figura 8 anterior se conoce como comunicación todos a todos. Dado que la mayoría de las comunicaciones de red se producen a través de TCP, esto conduce a miles de solicitudes y respuestas simultáneas entre el servidor web front-end y todos los nodos de procesamiento back-end. Se trata de un patrón de comunicación con muchísimos altibajos y, a menudo, conduce a un tipo especial de error de congestión conocido como colapso por saturación del punto de entrada de TCP.1, 2 La repentina e intensa respuesta de miles de servidores provoca que se descarten y retransmitan muchos paquetes, con lo que se produce una avalancha de tráfico de red para paquetes de datos que son muy pequeños. Los centros de recursos de gran tamaño y las aplicaciones en la nube suelen necesitar usar controladores de red personalizados para ajustar dinámicamente la ventana de recepción TCP y el temporizador de retransmisión. También se pueden configurar enrutadores para quitar el tráfico que supere una tasa específica y reducir el tamaño del envío.
- Administración de energía y temperatura: Por último, la variabilidad es un subproducto de otras técnicas de reducción de costos, como el uso de estados inactivos o la reducción de la frecuencia de CPU. A menudo, un procesador puede pasar una cantidad de tiempo nada desdeñable realizando un escalado vertical desde un estado de inactividad. La desactivación de estas optimizaciones de costos conlleva mayores costos y uso energético, pero reduce la variabilidad. Este es un problema menor en la nube pública, ya que los modelos de precios rara vez tienen en cuenta métricas de uso internas de los recursos del cliente.
Algunos experimentos han descubierto que la variabilidad de dichos sistemas es mucho peor en la nube pública,3 normalmente debido a un aislamiento imperfecto del rendimiento de los recursos virtuales y el procesador compartido. Esto se agrava si se ejecutan muchos trabajos dependientes de la latencia en el mismo nodo físico que los trabajos de uso intensivo de la CPU.
Convivir con la variabilidad: Soluciones de ingeniería
Muchos de los orígenes de la variabilidad vista anteriormente no tienen ninguna solución infalible. Por lo tanto, en lugar de intentar resolver todos los orígenes que aumentan la cola de la latencia, es necesario diseñar las aplicaciones en la nube de forma que sean tolerantes a la cola. Esto, por supuesto, se realiza de forma similar a la usada para diseñar aplicaciones para que sean tolerantes a errores, ya que no es factible corregir todos los errores posibles. Algunas de las técnicas comunes para tratar esta variabilidad son:
- Resultados "suficientemente buenos": Con frecuencia, cuando el sistema está esperando recibir resultados de miles de nodos, se puede suponer que la importancia de cualquier resultado es bastante baja. Por lo tanto, muchas aplicaciones pueden decidir simplemente responder a los usuarios con los resultados que llegan en una ventana de latencia corta concreta y descartar el resto.
- Pruebas controladas: Otra alternativa que se suele usar para las rutas de acceso al código poco frecuentes es probar una solicitud en un pequeño subconjunto de nodos de hoja para comprobar si se produce un bloqueo o un error que pueda afectar a todo el sistema. La consulta de distribución ramificada completa solo se genera si la prueba controlada no produce un error. Es algo similar a enviar un canario (pájaro) a una mina de carbón para comprobar si es segura para las personas.
- Comprobaciones de estado y pruebas inducidas por latencia: Por supuesto, una gran parte de las solicitudes a un sistema son demasiado comunes para probarlas mediante pruebas controladas. Lo más probable es que estas solicitudes tengan una cola larga si el rendimiento de uno de los nodos de hoja es bajo. Para contrarrestarlo, el sistema debe supervisar periódicamente el estado y la latencia de cada nodo de hoja y no enrutar las solicitudes a los nodos que muestran un bajo rendimiento (debido a un mantenimiento o a errores).
- QoS diferencial: Se pueden crear clases de servicio independientes para las solicitudes interactivas, lo que les permite tener prioridad en cualquier cola. Las aplicaciones que no dependen de la latencia pueden tolerar tiempos de espera más largos para sus operaciones.
- Cobertura de solicitudes: Esta es una solución sencilla para reducir el impacto de la variabilidad reenviando la misma solicitud a varias réplicas y usando la respuesta que llega en primer lugar. Por supuesto, esto puede hacer que la cantidad de recursos necesarios se duplique o triplique. Para reducir el número de solicitudes cubiertas, la segunda solicitud se puede enviar solo si la primera respuesta está pendiente durante un período superior al percentil 95 de la latencia esperada para esa solicitud. Esto hace que la carga adicional sea solo de un 5 %, pero reduce significativamente la cola de latencia (en el caso típico que se muestra en la figura 9, donde la latencia del percentil 95 es mucho menor que la latencia del percentil 99).
- Ejecución especulativa y replicación selectiva: Las tareas de los nodos que están especialmente ocupados se pueden iniciar de forma especulativa en otros nodos de hoja infrautilizados. Esto es especialmente eficaz si un error en un nodo determinado provoca que este se sobrecargue.
- Soluciones basadas en la experiencia de usuario: Por último, el retraso se le puede ocultar al usuario de forma inteligente a través de una interfaz de usuario bien diseñada que reduzca la sensación de retraso repentino experimentado por un individuo. Las técnicas para conseguirlo pueden incluir el uso de animaciones, la visualización de los primeros resultados o la interacción con el usuario mediante el envío de mensajes relevantes.
Con estas técnicas, es posible mejorar significativamente la experiencia de los usuarios finales de una aplicación en la nube para resolver el problema particular de una cola larga.
Referencias
- Li, J., Sharma, N. K., Ports, D. R., & Gribble, S. D. (2014). Tales of the Tail: Hardware, OS, and Application-Level Sources of Tail Latency from the Proceedings of the ACM Symposium on Cloud Computing, ACM
- Wu, Haitao y Feng, Zhenqian y Guo, Chuanxiong y Zhang, Yongguang (2013). ICTCP: Incast Congestion Control for TCP in Data-Center Networks, transacciones IEEE/ACM en redes (TON), IEEE Press
- Xu, Yunjing y Musgrave, Zachary y Noble, Brian y Bailey, Michael (2013). Bobtail: Avoiding Long Tails in the Cloud, 10th USENIX Conference on Networked Systems Design and Implementation, USENIX Association
- Dean, Jeffrey y Barroso, Luiz André (2013). The tail at scale, Communications of the ACM, ACM
- Tene, Gil (2014). [Understanding Latency - Some Key Lessons and Tools](https://www.infoq.com/presentations/latency-lessons-tools/, QCon London