Creación de servicios en la nube tolerantes a errores
Una gran parte de la administración de servicios en la nube y el centro de datos implica el diseño y mantenimiento de un servicio confiable basado en partes no confiables. En la siguiente ilustración se muestra parte de un entrenamiento para las nuevas contrataciones y debería proporcionar una idea del gran número (y tipos) de errores que se experimentan periódicamente en un centro de datos grande.

Figura 2: Problemas de confiabilidad, tal como se muestra en una presentación de entrenamiento
Un error en un sistema se produce como resultado de un estado no válido introducido en el sistema debido a un error. Normalmente, los errores que desarrollan los sistemas son de uno de los siguientes tipos:
- Errores transitorios: Errores temporales en el sistema que se corrigen solos con el tiempo.
- Errores permanentes: Errores de los que no se puede recuperar y que suelen requerir el reemplazo de recursos.
- Errores intermitentes: Errores que se producen periódicamente en un sistema.
Los errores pueden afectar a la disponibilidad del sistema, al detener los servicios o bajar el rendimiento de las funcionalidades del sistema. Un sistema tolerante a errores tiene la capacidad de realizar su función incluso si existen errores en el sistema. En la nube, a menudo se considera un sistema tolerante a errores como aquel que proporciona servicios de manera coherente con un tiempo de inactividad inferior al que permiten los acuerdos de nivel de servicio (SLA).
¿Por qué es importante la tolerancia a errores?
Los errores en grandes sistemas críticos pueden dar lugar a pérdidas monetarias significativas a todas las partes interesadas. La propia naturaleza de los sistemas informáticos en la nube es que tienen una arquitectura en capas. Por lo tanto, un error en una capa de los recursos en la nube puede desencadenar en un error en otras capas superiores u ocultar el acceso a las capas siguientes.
Por ejemplo, un error en cualquier componente de hardware del sistema puede afectar a la ejecución normal de una aplicación SaaS (software como servicio) que se ejecute en una máquina virtual con los recursos defectuosos. Los errores de un sistema en cualquier capa tienen una relación directa con los acuerdos de nivel de servicio entre los proveedores de cada nivel.
Medidas proactivas
Los proveedores de servicios adoptan varias medidas para diseñar el sistema de una manera específica con el fin de evitar problemas conocidos o errores predecibles.
Generación de perfiles y pruebas
Para garantizar la disponibilidad de los servicios son esenciales los recursos de nube de pruebas de carga y esfuerzo para comprender posibles causas de errores. La generación de perfiles de estas métricas ayuda a diseñar un sistema que pueda soportar correctamente la carga esperada sin ningún comportamiento imprevisible.
Exceso de aprovisionamiento
El exceso de aprovisionamiento es la práctica de implementar recursos en volúmenes mayores que el uso previsto general de los recursos en un momento dado. En situaciones en las que no se pueden predecir necesariamente las necesidades exactas del sistema, los recursos con exceso de aprovisionamiento pueden ser una estrategia aceptable para administrar picos inesperados en las cargas.
Considere como ejemplo una plataforma de comercio electrónico que tiene una carga media en los servidores que es coherente a lo largo del año, pero durante la temporada de vacaciones, la expectativa es que el modelo de carga sufra un pico rápidamente. En estas horas punta, es aconsejable aprovisionar recursos adicionales en función de los datos históricos de uso máximo. Un aumento rápido del tráfico suele ser difícil de acomodar en un corto período de tiempo. Tal y como se describe en secciones posteriores, hay un costo de tiempo asociado con el escalado de forma dinámica, el cual implica unos laboriosos pasos de detectar un cambio en el modelo de carga y aprovisionar recursos adicionales para acomodar la nueva carga. Ambos pasos requerirán tiempo. Este retraso en el ajuste puede ser suficiente para sobrecargar y, en el peor caso, bloquear el sistema o, en el mejor de los casos, reducir la calidad del servicio.
El aprovisionamiento excesivo también es una táctica que se usa para defenderse frente a ataques por DoS (denegación de servicio) o DDoS (DoS distribuido), que se dan cuando los atacantes generan solicitudes diseñadas para sobrecargar un sistema generando grandes volúmenes de tráfico en él en un intento por hacer que el sistema produzca un error. En cualquier ataque, el sistema siempre tarda algún tiempo en detectar y tomar medidas correctivas. Aunque se está realizando este análisis de patrones de solicitud, el sistema ya está bajo ataque y debe ser capaz de dar cabida al aumento del tráfico hasta que se pueda implementar una estrategia de mitigación.
Replicación
Los componentes críticos del sistema se pueden duplicar mediante componentes de hardware y software adicionales para controlar los errores de forma silenciosa en partes del sistema sin que se llegue a producir un error en todo el sistema. La replicación tiene dos estrategias básicas:
- Replicación activa, donde todos los recursos replicados están activos simultáneamente y responden a todas las solicitudes y las procesan. Esto significa que, para cualquier solicitud de cliente, todos los recursos reciben la misma solicitud, todos los recursos responden a la misma solicitud y el orden de las solicitudes mantiene el estado en todos los recursos.
- Replicación pasiva, donde solo la unidad principal procesa las solicitudes, y las unidades secundarias solo mantienen el estado y toman el control cuando se produzca un error en la unidad principal. El cliente solo está en contacto con el recurso principal, que retransmite el cambio de estado a todos los recursos secundarios. La desventaja de la replicación pasiva es que es posible que se interrumpan algunas solicitudes o que la calidad de servicio se vea degradada al cambiar de la instancia principal a la secundaria.
También hay una estrategia híbrida, denominada semiactiva, que es muy similar a la estrategia activa. La diferencia es que solo se expone la salida del recurso principal al cliente. Las salidas de los recursos secundarios se suprimen y registran y están listas para intercambiarse en cuanto se produzca un error en el recurso principal. En la siguiente ilustración se muestran las diferencias entre las estrategias de replicación.
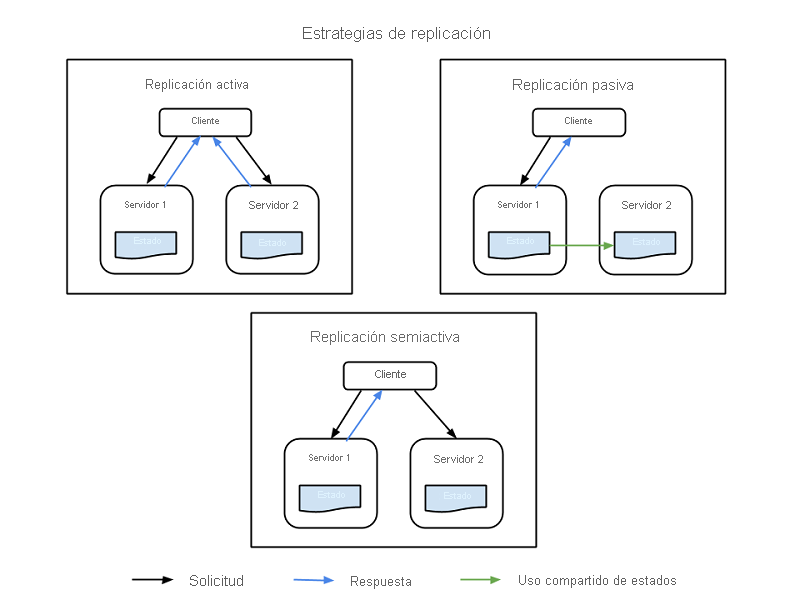
Figura 3: Estrategias de replicación
Un factor importante a tener en cuenta en la replicación es el número de recursos secundarios que se van a usar. Aunque esto difiere de una aplicación a otra en función de la importancia del sistema, hay tres niveles formales de replicación:
- N+1: Básicamente, esto significa que para una aplicación que necesita N nodos para funcionar correctamente, se aprovisiona un recurso adicional de seguridad.
- 2N: En este nivel, se aprovisiona un nodo adicional de seguridad para cada nodo necesario para la función normal.
- 2N+1: En este nivel, se aprovisiona un nodo adicional general y un nodo adicional de seguridad para cada nodo necesario para la función normal.
Medidas reactivas
Además de las medidas predictivas, los sistemas pueden tomar medidas reactivas y enfrentarse a los errores a medida que se producen:
Comprobaciones y supervisión
Todos los recursos se supervisan constantemente para comprobar si hay algún comportamiento impredecible o la pérdida de recursos. En función de la información de supervisión, las estrategias de recuperación o reconfiguración están diseñadas para reiniciar los recursos o para usar otros nuevos. La supervisión puede ayudar en la identificación de errores en los sistemas. Los errores que provocan que un servicio no esté disponible se denominan errores de bloqueo y los que provocan un comportamiento irregular o incorrecto en el sistema se denominan errores bizantinos.
Hay varias tácticas de supervisión que se utilizan para comprobar los errores de bloqueo en un sistema. Dos de estas tácticas son las siguientes:
- Eco de pin: El servicio de supervisión pregunta a cada recurso su estado, al que se le asigna un período de tiempo para responder.
- Latido: Cada instancia envía el estado al servicio de supervisión a intervalos regulares, sin ningún desencadenador.
La supervisión de errores bizantinos normalmente depende de las propiedades del servicio que se proporciona. Los sistemas de supervisión pueden comprobar las métricas básicas, como la latencia, el uso de la CPU y el uso de memoria, y comprobar los valores esperados para ver si se está degradando la calidad del servicio. Además, los registros de supervisión específicos de la aplicación normalmente se mantienen en cada punto de ejecución de servicio importante y se analizan periódicamente para ver que el servicio funciona correctamente en todo momento (o si hay errores insertados en el sistema).
Punto de control y reinicio
Varios modelos de programación en la nube implementan estrategias de puntos de control, en las que el estado se guarda en varias fases de ejecución para habilitar la recuperación al último punto de control guardado. En las aplicaciones de análisis de datos, a menudo hay tareas distribuidas paralelas de ejecución prolongada que se ejecutan en terabytes de conjuntos de datos para extraer información. Puesto que dichas tareas se ejecutan en varios fragmentos pequeños de ejecución, cada paso de la ejecución del programa puede guardar el estado general de la ejecución como un punto de control. En los puntos de error en los que los nodos individuales no pueden completar su trabajo, se puede reiniciar la ejecución desde un punto de control anterior. El mayor desafío al identificar los puntos de control válidos para la reversión es cuando los procesos paralelos comparten información. Un error en uno de los procesos puede provocar una reversión en cascada en otro proceso, ya que los puntos de control realizados en ese proceso pueden ser el resultado de un error en los datos compartidos por el proceso con errores. Obtendrá más información sobre la tolerancia a errores para los modelos de programación en módulos posteriores.
Casos prácticos en pruebas de resistencia
Los servicios en la nube deben compilarse teniendo en cuenta la redundancia y la tolerancia a errores, ya que ningún componente único de un sistema distribuido grande puede garantizar un tiempo de actividad o una disponibilidad del 100 %.
Todos los errores (incluidos los errores de dependencias en el mismo nodo, bastidor, centro de datos o implementaciones con redundancia regional) deben controlarse correctamente sin que afecten a todo el sistema. Es importante probar la capacidad del sistema para controlar los errores catastróficos, ya que a veces bastan unos pocos segundos de tiempo de inactividad o degradación del servicio para provocar cientos de miles, si no millones, de dólares en pérdida de ingresos.
Es necesario realizar pruebas de errores con tráfico real con regularidad para que el sistema esté protegido y pueda hacer frente a una interrupción imprevista. Se han creado varios sistemas para probar la resistencia. Uno de estos conjuntos de pruebas es Simian Army, creado por Netflix.
Simian Army se compone de servicios (denominados Monkeys) en la nube para generar diversos tipos de errores, detectar condiciones anómalas y probar la capacidad del sistema para sobrevivir a ellos. El objetivo es mantener la seguridad en la nube y la alta disponibilidad. Algunos de los Monkeys que se encuentran en Simian Army son los siguientes:
- Chaos Monkey: Una herramienta que selecciona aleatoriamente una instancia de producción y la deshabilita para asegurarse de que la nube sobrevive a los tipos de error comunes sin ningún impacto en el cliente. Netflix describe Chaos Monkey como "La idea de soltar un mono salvaje armado en el centro de datos (o región de la nube) para abatir las instancias de forma aleatoria y mordisquear los cables, todo ello mientras se sigue atendiendo a los clientes sin interrupción". Este tipo de pruebas con supervisión detallada pueden exponer varias formas de puntos débiles en el sistema, y se pueden crear estrategias de recuperación automática en función de los resultados.
- Latency Monkey: Un servicio que induce retrasos en la comunicación de RESTful entre diferentes clientes y servidores, y simula la degradación del servicio y el tiempo de inactividad.
- Doctor Monkey: Un servicio que detecta instancias que muestran comportamientos incorrectos (por ejemplo, la carga de la CPU) y las quita del servicio. Proporciona algo de tiempo a los propietarios del servicio para determinar el motivo del problema y finalmente finaliza la instancia.
- Chaos Gorilla: Un servicio que puede simular la pérdida de toda una zona de disponibilidad de AWS. Se usa para probar si los servicios reequilibran automáticamente la funcionalidad entre las zonas restantes sin impacto visible para el usuario o intervención manual.