Implementación de aplicaciones en la nube
Después de diseñar y desarrollar una aplicación en la nube, se puede pasar a la fase de implementación para su lanzamiento para los clientes. La implementación puede ser un proceso de varias fases, cada uno de los cuales implica una serie de comprobaciones para garantizar que se cumplan los objetivos de la aplicación.
Antes de implementar en el entorno de producción una aplicación en la nube, es útil disponer de una lista de comprobación para ayudar a evaluar la aplicación en relación a una lista de prácticas recomendadas esenciales y recomendadas. Entre los ejemplos se incluye la lista de comprobación de implementación de AWS y Azure. Muchos proveedores de nube proporcionan una lista completa de herramientas y servicios que ayudan en la implementación, como este documento de Azure.
Proceso de implementación
La implementación de una aplicación en la nube es un proceso iterativo que comienza al final del desarrollo y continúa hasta el lanzamiento de la aplicación en los recursos de producción:
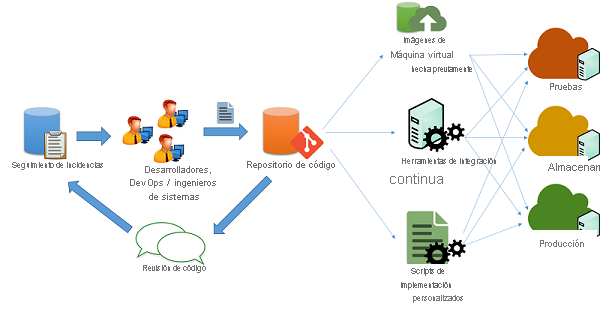
Figura 1: Proceso de implementación del código
Es habitual que los desarrolladores de la nube mantengan varias versiones de sus aplicaciones ejecutándose simultáneamente para canalizar su implementación en distintas fases:
- Prueba
- Ensayo
- Producción
Idealmente, cada una de las tres fases debe tener los mismos recursos y configuraciones, lo que permite a los desarrolladores probar e implementar la aplicación y minimizar las posibilidades de incoherencias derivadas de un cambio en el entorno y la configuración.
Canalización de los cambios en aplicaciones
En un escenario de desarrollo de aplicaciones ágiles típico (como el que se muestra en la ilustración anterior), el mantenimiento de las aplicaciones lo realiza un conjunto de ingenieros y desarrolladores, quienes trabajan en problemas y errores mediante algún tipo de mecanismo de seguimiento de problemas. Los cambios en el código se mantienen a través de un sistema de repositorio de código (por ejemplo, svn, mercurial o git), donde se mantienen ramas independientes para la versión del código. Después de pasar por cambios, revisiones y aprobaciones, el código se puede canalizar a las fases de pruebas, ensayo y producción. Esto se puede hacer de varias maneras:
Scripts personalizados: Los desarrolladores pueden usar scripts personalizados para extraer la versión más reciente del código y ejecutar comandos específicos para compilar la aplicación y ponerla en un estado de producción.
Imágenes de máquina virtual precreadas: Los desarrolladores también pueden aprovisionar y configurar una máquina virtual con todo el entorno y el software necesarios para implementar su aplicación. Una vez configurada, se puede crear una instantánea de la máquina virtual y exportarla a una imagen de máquina virtual. Esta imagen se puede proporcionar a varios sistemas de orquestación en la nube para implementarla y configurarla automáticamente para una implementación de producción.
Sistemas de integración continua: Con el fin de simplificar las diversas tareas que intervienen en la implementación, se pueden usar herramientas de integración continua (CI) para automatizar las tareas (como la recuperación de la versión más reciente de un repositorio, la creación de archivos binarios de la aplicación y la ejecución de casos de prueba) que se deben completar en las distintas máquinas que componen la infraestructura de producción. Algunos ejemplos de herramientas de CI populares son Jenkins, Bamboo y Travis. Azure Pipelines es una herramienta de CI específica de Azure diseñada para trabajar con implementaciones de Azure.
Administración del tiempo de inactividad
Algunos cambios en la aplicación pueden requerir la terminación parcial o completa de los servicios de aplicación para incorporar un cambio en el back-end de la aplicación. Normalmente, los desarrolladores deben programar una hora específica del día para que los clientes de la aplicación vean minimizadas las interrupciones. Es posible que las aplicaciones diseñadas para la integración continua puedan realizar estos cambios en directo en sistemas de producción con una interrupción mínima o inexistente a los clientes de la aplicación.
Redundancia y tolerancia a errores
Los procedimientos recomendados para la implementación de aplicaciones normalmente suponen que la infraestructura de la nube es efímera y podría no estar disponible o cambiar en cualquier momento. Por ejemplo, las máquinas virtuales implementadas en un servicio de IaaS se pueden programar para que finalicen según el criterio del proveedor de nube, en función del tipo de acuerdo de nivel de servicio.
Las aplicaciones deben abstenerse de codificar de forma rígida o asumir puntos de conexión estáticos para varios componentes, como bases de datos y puntos de conexión de almacenamiento. Las aplicaciones bien diseñadas deberían usar API de servicio para consultar y detectar recursos y conectarse a ellos de manera dinámica.
Los errores graves en los recursos o la conectividad pueden producirse de un momento a otro. Las aplicaciones críticas deben diseñarse con anticipación a estos errores y teniendo en cuenta la redundancia de conmutación por error.
Muchos proveedores de servicios en la nube diseñan sus centros de recursos en regiones y zonas. Una región es un sitio geográfico específico que aloja un centro de datos completo, mientras que las zonas son secciones individuales dentro de un centro de datos que están aisladas para la tolerancia a errores. Por ejemplo, dos o más zonas dentro de un centro de datos pueden tener una infraestructura de alimentación, refrigeración y conectividad independiente para que un error en una zona no afecte a la infraestructura del otro. Los proveedores de servicios en la nube suelen poner a disposición de los clientes y desarrolladores información sobre la región y la zona para diseñar y desarrollar aplicaciones que puedan usar esta propiedad de aislamiento.
Por tanto, los desarrolladores pueden configurar su aplicación para que use recursos en varias regiones o zonas con el fin de mejorar la disponibilidad de su aplicación y tolerar errores que puedan producirse en una zona o región. Es necesario que configuren sistemas que puedan enrutar y equilibrar el tráfico entre regiones y zonas. También se pueden configurar los servidores DNS para que respondan a las solicitudes de búsqueda de dominio a direcciones IP concretas en cada zona, en función de dónde se originó la solicitud. De esta forma, se proporciona un método de equilibrio de carga basado en la proximidad geográfica de los clientes.
Seguridad y protección en producción
La ejecución de aplicaciones de Internet en una nube pública debe realizarse con cuidado. Dado que los intervalos de IP en la nube son ubicaciones que resultan un objetivo valioso, es importante asegurarse de que todas las aplicaciones implementadas en la nube siguen las prácticas recomendadas para proteger y reforzar los puntos de conexión y las interfaces. Entre los principios básicos que se deben seguir se incluyen los siguientes:
- Se debe cambiar todo el software al modo de producción. La mayoría de los programas de software admiten el "modo de depuración" para las pruebas locales y el "modo de producción" para las implementaciones reales. Normalmente, las aplicaciones en modo de depuración filtran una gran cantidad de información a los atacantes que envían entradas con formato incorrecto, por lo que son una fuente fácil de reconocimiento para los hackers. Da igual si usa un marco web como Django y Rails, o una base de datos como Oracle, es importante que siga las directrices pertinentes para la implementación de aplicaciones de producción.
- El acceso a servicios no públicos se debe restringir a determinadas direcciones IP internas para el acceso de administrador. Asegúrese de que los administradores no pueden iniciar sesión directamente en un recurso crítico desde Internet sin tener que visitar un Launchpad interno. Configure firewalls con reglas basadas en puertos y direcciones IP para permitir el conjunto mínimo de accesos necesarios, especialmente a través de SSH y otras herramientas de conectividad remota.
- Siga el principio de usar privilegios mínimos. Ejecute todos los servicios como el usuario con los menores privilegios que puede realizar el rol requerido. Restrinja el uso de credenciales raíz a inicios de sesión manuales específicos por parte de los administradores del sistema que necesitan depurar o configurar algunos problemas críticos en el sistema. Esto también se aplica al acceso a las bases de datos y a los paneles administrativos. Los accesos generalmente deben protegerse mediante un par de claves pública-privada aleatorias y largas, y este par de claves se debe almacenar de forma segura en una ubicación restringida y cifrada. Todas las contraseñas deben tener requisitos estrictos.
- Utilice técnicas y herramientas de defensa conocidas para obtener sistemas de detección y prevención de intrusiones (IDS/IPS), información de seguridad y administración de eventos (SIEM), firewalls de nivel de aplicación y sistemas antimalware.
- Configure una programación de revisión que coincida con las versiones de revisión del proveedor de los sistemas que use. A menudo, los proveedores como Microsoft tienen un ciclo de versión fijo para las revisiones.