Configuración de un conjunto de escalado de máquinas virtuales
Al usar el escalado, se agregan instancias al conjunto de escalado de máquinas virtuales. En el escenario de la empresa de transportes, el escalado es una buena forma de procesar el número variable de solicitudes en el tiempo. El escalado ajusta el número de máquinas virtuales en las que se ejecuta la aplicación web a medida que cambia el número de usuarios. De esta forma, el sistema mantiene un tiempo de respuesta uniforme, con independencia de la carga actual.
En esta unidad, obtendrá información sobre cómo escalar un conjunto de escalado de máquinas virtuales. Puede escalar de forma manual si establece explícitamente el número de instancias de máquinas virtuales en el conjunto de escalado. Puede configurar el escalado automático si define reglas de escalado que desencadenen la asignación y desasignación de máquinas virtuales. Estas reglas de escalado determinan cuándo se escala el sistema, mediante la supervisión de varias métricas de rendimiento.
Escalado manual de conjuntos de escalado de máquinas virtuales
Puede escalar de forma manual un conjunto de escalado de máquinas virtuales si aumenta o reduce el recuento de instancias. Puede realizar esta tarea mediante programación o en Azure Portal.
En el código siguiente, se usa la CLI de Azure para cambiar el número de instancias de un conjunto de escalado de máquinas virtuales:
az vmss scale \
--name webServerScaleSet \
--resource-group MyResourceGroup \
--new-capacity 6
Escalado automático de conjuntos de escalado de máquinas virtuales
El escalado manual es útil en algunas circunstancias. Pero en muchas situaciones, el escalado automático es mejor. Permite que el sistema controle el número de instancias de un conjunto de escalado.
Puede basar el escalado automático en lo siguiente:
- Programación: Use este enfoque si sabe que tiene una mayor carga de trabajo en un período de fecha o hora especificado.
- Métricas: ajuste el escalado mediante la supervisión de las métricas de rendimiento asociadas al conjunto de escalado. Cuando estas métricas superan el umbral especificado, el conjunto de escalado puede iniciar automáticamente nuevas instancias de máquinas virtuales. Cuando las métricas indican que los recursos adicionales ya no son necesarios, el conjunto de escalado puede detener las instancias que sobren.
Definición de condiciones, reglas y límites de escalado automático
La escalabilidad automática se basa en un conjunto de condiciones, reglas y límites de escala. En una condición de escalado, se combinan el tiempo y un conjunto de reglas de escalado. Si la hora actual se encuentra dentro del período definido en la condición de escalado, se evalúan las reglas de escalado de la condición. Los resultados de esta evaluación determinan si se agregarán instancias al conjunto de escalado o se quitarán de este. La condición de escalado también define los límites de escalado para el número máximo y mínimo de instancias.
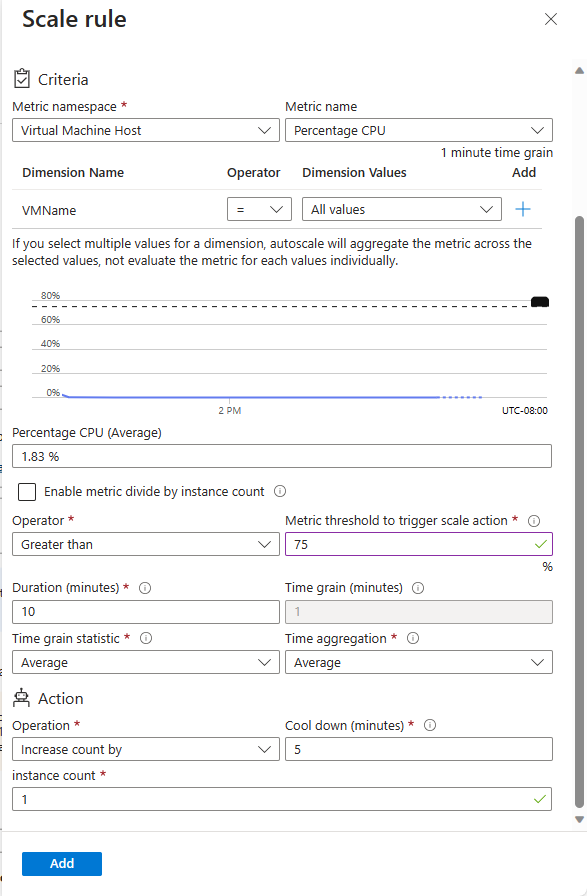
En el escenario de la empresa de transportes, puede agregar reglas de escalado que supervisen el uso de CPU en todo el conjunto de escalado. Si el uso de CPU supera el umbral del 75 %, la regla de escalado puede incrementar el número de instancias de máquinas virtuales. Una segunda regla de escalado también puede supervisar el uso de CPU, pero reducir el número de instancias de máquina virtual cuando el uso cae por debajo del 50 %. Como se trata de una aplicación global, estas reglas necesitan estar activas continuamente, no solo a horas concretas.
Un conjunto de escalado de máquinas virtuales puede contener muchas condiciones de escalado. Se actúa sobre todas las condiciones de escalado que coinciden. Un conjunto de escalado también puede contener una condición de escala predeterminada que se usará si ninguna otra condición de escala coincide con la hora actual y las métricas de rendimiento. La condición de escalado predeterminada siempre está activa. No contiene ninguna regla de escalado, actuando eficazmente como una condición de escalado null que no se escala vertical u horizontalmente. Sin embargo, puede modificar la condición de escalado predeterminada para establecer un recuento de instancias predeterminado, o puede agregar un par de reglas de escalado que se escalan horizontalmente y, de nuevo, verticalmente.
Uso de escalado automático basado en programación
En el escalado basado en programación se especifica una hora de inicio y finalización, así como el número de instancias que se agregarán al conjunto de escalado. En la captura de pantalla siguiente, se muestra un ejemplo en Azure Portal. El número de instancias se escala a 20 entre las 6:00 y las 18:00 cada lunes y miércoles. Fuera de este horario, si no se activa ninguna otra condición de escalado, se aplica la predeterminada.
En este caso, la regla predeterminada vuelve a reducir la escala del sistema a dos instancias. Este valor es el Máximo en esta condición de escalado predeterminada.

Uso de escalado automático basado en métricas
Una regla de escalado basada en métricas especifica los recursos que se van a supervisar, como el uso de CPU o el tiempo de respuesta. Esta regla de escalado agrega o quita instancias del conjunto de escalado según los valores de estas métricas. Especifique límites sobre el número de instancias para impedir que en un conjunto de escalado se escale o reduzca horizontalmente en exceso.
En el escenario de ejemplo, quiere incrementar el recuento de instancias en uno cuando el uso medio de CPU supere el 75 %. Además, quiere limitar la operación de escalabilidad horizontal a 50 instancias. Este límite puede ayudar a evitar el escalado descontrolado debido a un ataque. De forma similar, quiere escalar verticalmente cuando el uso medio de CPU esté por debajo del 50 %.
Estas métricas se usan habitualmente para supervisar un conjunto de escalado de máquinas virtuales:
- Porcentaje de CPU: esta métrica indica el uso de CPU en todas las instancias. Un valor elevado muestra que las instancias realizan un uso intensivo de CPU, lo que podría retrasar el procesamiento de las solicitudes cliente.
- Flujos de entrada y flujos de salida: estas métricas muestran la rapidez con la que el tráfico de red entra y sale de las máquinas virtuales en el conjunto de escalado.
- Operaciones de escritura por segundo en disco y operaciones de lectura por segundo en disco: estas métricas muestran el volumen de E/S de disco en el conjunto de escalado.
- Profundidad de cola del disco de datos: esta métrica muestra el número de solicitudes de E/S solo en los discos de datos de las máquinas virtuales que están en espera de mantenimiento.
Una regla de escalado agrega los valores recuperados para una métrica de todas las instancias. Agrega los valores en un período conocido como intervalo de agregación. Cada métrica tiene su propio intervalo de agregación, pero normalmente este período es de un minuto. El valor agregado se conoce como agregación de tiempo. Las opciones de agregación de tiempo son promedio, mínimo, máximo, total, último y recuento.
Un intervalo de un minuto es demasiado breve para determinar si un cambio en la métrica tiene una duración suficiente para que el escalado automático resulte adecuado. Una regla de escalado realiza un segundo paso para aumentar más el valor de la agregación de tiempo a lo largo de un período más largo especificado por el usuario. Este período se denomina duración. La duración mínima es de cinco minutos. Por ejemplo, si la duración se establece en 10 minutos, la regla de escalado agrega los diez valores calculados para el intervalo de agregación.
El cálculo de la agregación de la duración puede diferir del cálculo de agregación del intervalo de agregación. Por ejemplo, imagine que la agregación de tiempo es promedio y que la estadística recopilada es porcentaje de CPU en un intervalo de tiempo de un minuto. Por cada minuto, se calcula el uso medio del porcentaje de CPU en todas las instancias durante ese minuto. Si la estadística de intervalo de agregación se establece en máximo y la duración de la regla en 10 minutos, el máximo de los 10 valores promedio para el porcentaje de uso de CPU determina si se ha superado el umbral de la regla.
Cuando una regla de escalado detecta que una métrica pasa un umbral, puede realizar una acción de escalado. Una acción de escalado puede ser de escalabilidad horizontal o de reducción horizontal. Una acción de escalabilidad horizontal aumenta el número de instancias. Una acción de reducción horizontal reduce el recuento de instancias.
Una acción de escalado usa un operador como menor que, mayor que o igual a para determinar cómo reaccionar ante el umbral. Las acciones de escalabilidad horizontal suelen usar el operador mayor que para comparar el valor de la métrica con el umbral. Las acciones de reducción horizontal tienden a comparar el valor de la métrica con el umbral mediante el operador menor que. Una acción de escalado también establece el recuento de instancias en un nivel específico, en lugar de incrementar o reducir el número disponible.
Una acción de escalado tiene un tiempo de recuperación, que se especifica en minutos. Durante este período, la regla de escalado no se vuelve a desencadenar. La recuperación permite al sistema estabilizarse entre eventos de escalado. El proceso para iniciar o apagar las instancias tarda tiempo, por lo que es posible que las métricas recopiladas no muestren cambios importantes durante varios minutos. El tiempo de recuperación mínimo es de cinco minutos.
Por último, debe planear el escalado vertical cuando se reduzca una carga de trabajo. También puede definir reglas de escalado en parejas en la misma condición de escalado. Una regla de escala necesita indicar cómo escalar horizontalmente el sistema si una métrica supera un umbral superior. La otra regla necesita definir cómo volver a reducir horizontalmente el sistema si la misma métrica se sitúa por debajo de un umbral inferior. Evite que los dos valores de umbral sean iguales. De lo contrario, podría desencadenar una serie de eventos oscilantes que se escalan horizontalmente y después se reducen.
En la siguiente imagen se muestra una regla de escalado definida en Azure Portal.