Uso de AutoML en la interfaz de usuario de Azure Databricks
Puede usar la interfaz gráfica de usuario en el portal de Azure Databricks para crear y administrar experimentos de AutoML.
Configuración de un experimento de AutoML
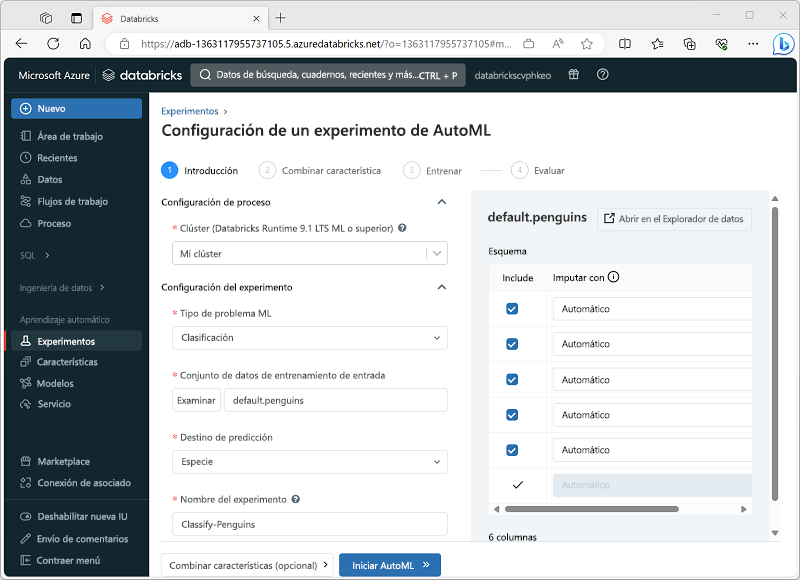
Para configurar el experimento de AutoML, debe especificar la configuración de los requisitos de entrenamiento específicos para el modelo, entre los que se incluyen:
- Clúster en el que va a ejecutar el experimento.
- Tipo de modelo de Machine Learning que se va a entrenar (agrupación en clústeres, regresión o previsión).
- Tabla que contiene los datos de entrenamiento.
- El campo de etiqueta de destino al modelo debe predecirse.
- Nombre único para el experimento de AutoML (las ejecuciones secundarias de cada prueba de entrenamiento se nombran de forma única automáticamente).
- Métrica de evaluación que desea utilizar para determinar el modelo con el mejor rendimiento.
- Marcos de trabajo de entrenamiento de aprendizaje automático que desea probar.
- Tiempo máximo para el experimento.
- Valor de etiqueta positivo (solo para clasificación binaria).
- Columna de hora (solo para modelos de previsión).
- Dónde guardar los modelos entrenados (como artefactos de MLflow o en el almacén de DBFS).
Revisión de los resultados de AutoML
A medida que avanza el experimento de AutoML, se muestran las ejecuciones secundarias, con el experimento que ha producido el modelo con el mejor rendimiento hasta ahora.
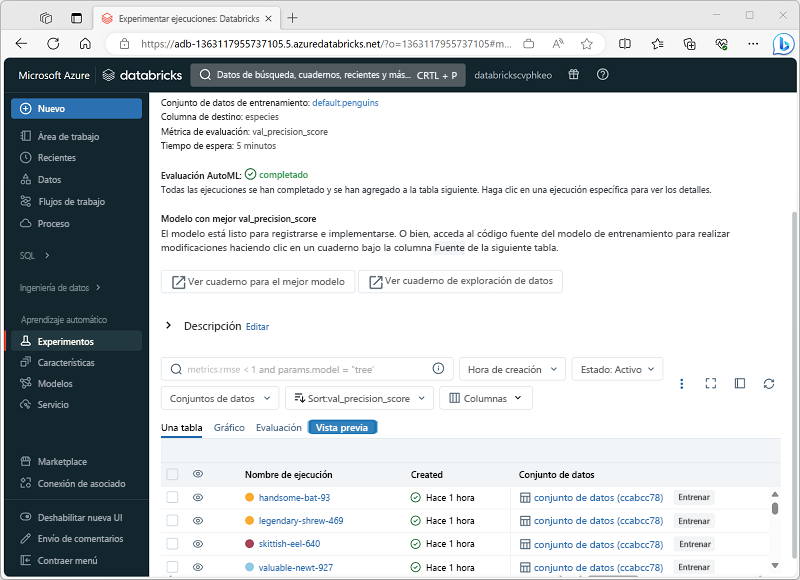
Puede esperar a que finalice el experimento o explorar los modelos producidos hasta ahora y detener el experimento si alguno de ellos satisface sus necesidades.
Puede explorar cada ejecución para ver el cuaderno que se ha generado y las métricas del modelo que ha producido. A continuación, puede registrar el modelo e implementarlo para inferencia.