¿Qué es AutoML?
AutoML es una característica de Azure Databricks que permite automatizar el entrenamiento y la evaluación de un modelo de Machine Learning usando diferentes combinaciones de algoritmos y valores de hiperparámetros. Con AutoML, puede reducir el esfuerzo que supone un proceso de entrenamiento de modelos iterativo y crear un modelo óptimo para los datos con más rapidez.
¿Cómo funciona AutoML?
AutoML funciona generando varias ejecuciones de un experimento, cada una de las cuales entrena un modelo usando una combinación de algoritmos e hiperparámetros diferente. En cada ejecución, se entrena y evalúa un modelo en función de los datos y la métrica predictiva que especifique. Azure Databricks hace un seguimiento de las ejecuciones y los modelos que producen usando MLflow. Esto permite identificar el modelo con el mejor rendimiento e implementarlo en producción.
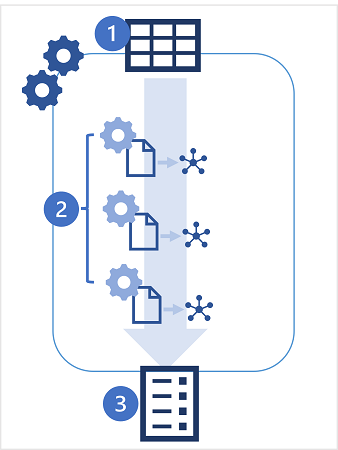
- Inicie un experimento de AutoML, especificando una tabla en el área de trabajo de Azure Databricks como origen de datos para el entrenamiento y la métrica de rendimiento específica que usará para la optimización.
- El experimento de AutoML genera varias ejecuciones de MLflow, cada una de las cuales produce un cuaderno con código para preprocesar los datos antes de entrenar y validar un modelo. Los modelos entrenados se guardan como artefactos en las ejecuciones o los archivos de MLflow en el almacén de DBFS.
- Las ejecuciones del experimento se enumeran en función del rendimiento, mostrando en primer lugar los modelos con el mejor rendimiento. Puede explorar los cuadernos que se han generado para cada ejecución, elegir el modelo que desea usar y, después, registrarlo e implementarlo.
Sugerencia
Para obtener más información sobre las transformaciones de preprocesamiento específicas y los algoritmos de entrenamiento que usa AutoML, consulte Funcionamiento de AutoML de Azure Databricks en la documentación de Azure Databricks.
Preparación de los datos para AutoML
AutoML necesita un origen de datos de entrenamiento que incluya valores de características y etiquetas. Para proporcionar estos datos, cree una tabla en el metastore de Hive en el área de trabajo de Azure Databricks.
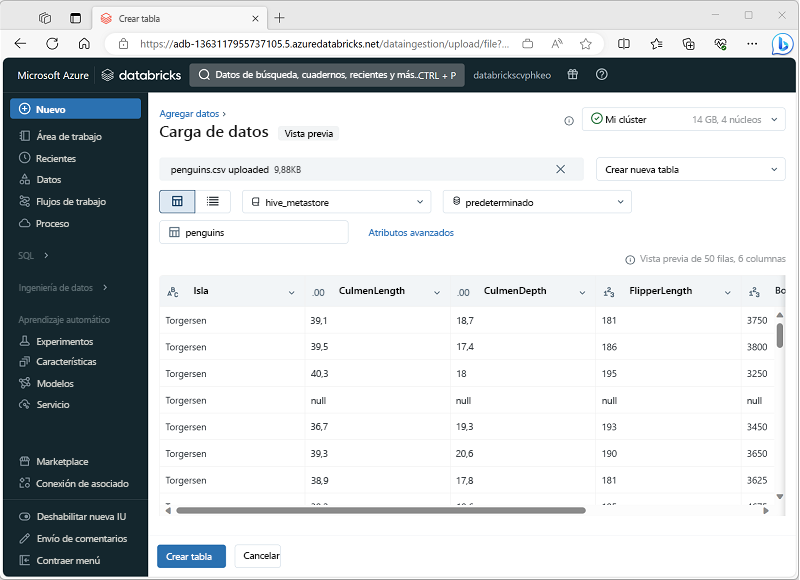
Una manera sencilla de crear una tabla de datos de entrenamiento para AutoML es cargar un archivo de datos en el portal de Azure Databricks, como se muestra aquí.
AutoML genera código para controlar tareas comunes de preprocesamiento de datos, como la codificación de variables de categorías, el escalado de variables numéricas, el control de valores NULL y el tratamiento de conjuntos de datos desequilibrados.