Aprendizaje automático para Computer Vision
La capacidad de usar filtros para aplicar efectos a imágenes resulta útil en tareas de procesamiento de imágenes, como podría realizar con software de edición de imágenes. Sin embargo, el objetivo de Computer Vision suele ser extraer significado o, al menos, información accionable de imágenes, lo que requiere la creación de modelos de Machine Learning entrenados para reconocer características basadas en grandes volúmenes de imágenes existentes.
Sugerencia
En esta unidad se supone que está familiarizado con los principios fundamentales del aprendizaje automático y que tiene conocimientos conceptuales de aprendizaje profundo con redes neuronales. Si no está familiarizado con el aprendizaje automático, considere la posibilidad de completar el módulo Aspectos básicos del aprendizaje automático en Microsoft Learn.
Redes neuronales convolucionales (CNN)
Una de las arquitecturas de modelo de Machine Learning más comunes para Computer Vision es una red neuronal convolucional (CNN), un tipo de arquitectura de aprendizaje profundo. Las CNN usan filtros para extraer mapas numéricos de características de imágenes y, a continuación, introducen los valores de características a un modelo de aprendizaje profundo para generar una predicción de etiquetas. Por ejemplo, en un escenario de clasificación de imágenes, la etiqueta representa el asunto principal de la imagen (es decir, ¿de qué es esta imagen?). Podría entrenar un modelo de CNN con imágenes de diferentes tipos de fruta (como manzanas, plátanos y naranjas) para que la etiqueta que se prediga sea el tipo de fruta en una imagen determinada.
Durante el proceso de entrenamiento de una CNN, los kernel de filtro se definen inicialmente mediante valores de peso generados aleatoriamente. Entonces, a medida que avance el proceso de entrenamiento, las predicciones de los modelos se evaluarán con los valores de etiqueta conocidos y los pesos de filtro se ajustarán para mejorar la precisión. Finalmente, el modelo entrenado de clasificación de imágenes de fruta usará los pesos de filtro que mejor extraigan las características que ayuden a identificar diferentes tipos de fruta.
En el diagrama siguiente se muestra cómo funciona una CNN para un modelo de clasificación de imágenes:
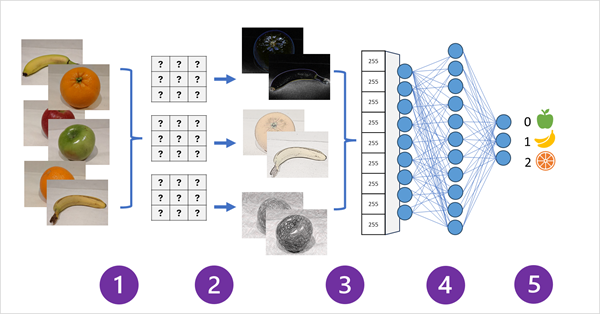
- Las imágenes con etiquetas conocidas (por ejemplo, 0: manzana; 1: plátano o 2: naranja) se introducen en la red para entrenar el modelo.
- Una o varias capas de filtros se usan para extraer características de cada imagen a medida que se alimentan a través de la red. Los kernel de filtro comienzan con pesos asignados aleatoriamente y generan matrices de valores numéricos denominados mapas de características.
- Los mapas de características se aplanan en una matriz unidimensional de valores de características.
- Los valores de características se introducen en una red neuronal totalmente conectada.
- La capa de salida de la red neuronal usa una función softmax o similar para generar un resultado que contenga un valor de probabilidad para cada clase posible. Por ejemplo: [0.2, 0.5, 0.3].
Durante el entrenamiento, las probabilidades de salida se comparan con la etiqueta de clase real. Por ejemplo: una imagen de un plátano (clase 1) debería tener el valor [0.0, 1.0, 0.0]. La diferencia entre las puntuaciones de clase predichas y reales se usa para calcular la pérdida en el modelo, mientras que los pesos de la red neuronal totalmente conectada y los kernel de filtro de las capas de extracción de características se modifican para reducir la pérdida.
El proceso de entrenamiento se repetirá en varias épocas hasta que se haya aprendido un conjunto óptimo de pesos. A continuación, se guardarán los pesos y el modelo se podrá usar para predecir las etiquetas de las nuevas imágenes de las que se desconozca la etiqueta.
Nota:
Normalmente, las arquitecturas de CNN incluyen varias capas de filtros convolucionales y capas adicionales para reducir el tamaño de los mapas de características, restringir los valores extraídos y manipular los valores de las características. Estas capas se han omitido en este ejemplo simplificado para focalizar el concepto de clave, que consiste en que los filtros se usan para extraer características numéricas de imágenes, que luego se usan en una red neuronal para predecir etiquetas de imagen.
Transformadores y modelos multimodales
Las CNN han estado en el núcleo de las soluciones de Computer Vision durante muchos años. Aunque normalmente se usan para resolver problemas de clasificación de imágenes como se ha descrito anteriormente, también son la base de modelos de Computer Vision más complejos. Por ejemplo, los modelos de detección de objetos combinan capas de extracción de características de CNN con la identificación de regiones de interés en imágenes para localizar varias clases de objeto en la misma imagen.
Transformadores
La mayoría de los avances de Computer Vision durante décadas han sido impulsados por mejoras en los modelos basados en CNN. Sin embargo, en otra materia de inteligencia artificial: procesamiento del lenguaje natural (NLP), otro tipo de arquitectura de red neuronal denominado transformador ha habilitado el desarrollo de modelos sofisticados para el lenguaje. Los transformadores funcionan mediante el procesamiento de grandes volúmenes de datos y tokens de lenguaje de codificación (que representan palabras o frases individuales) como incrustaciones basadas en vectores (matrices de valores numéricos). Puede pensar en una inserción como una representación de un conjunto de dimensiones donde cada una representa algún atributo semántico del token. Las incrustaciones se crean de tal forma que los tokens que se usan habitualmente en el mismo contexto están más cerca dimensionalmente que las palabras no relacionadas.
Como ejemplo sencillo, en el diagrama siguiente se muestran algunas palabras codificadas como vectores tridimensionales y trazadas en un espacio 3D:
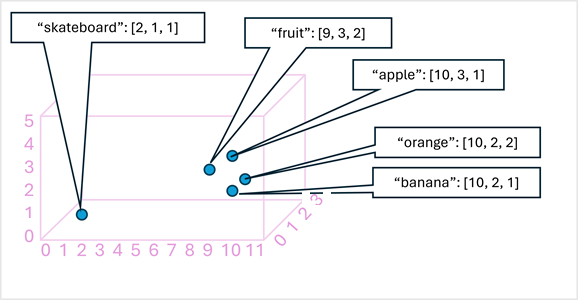
Los tokens que son semánticamente similares se codifican en posiciones similares, creando un modelo de lenguaje semántico que permite crear soluciones sofisticadas de NLP para el análisis de texto, la traducción, la generación de lenguajes y otras tareas.
Nota:
Solo se usaron tres dimensiones porque es fácil de visualizar. En realidad, los codificadores de las redes transformadoras crean vectores con muchas más dimensiones, definiendo relaciones semánticas complejas entre tokens basados en cálculos algebraicos lineales. Las matemáticas implicadas son complejas, al igual que la arquitectura de un modelo de transformador. Nuestro objetivo es proporcionar un reconocimiento conceptual de cómo la codificación crea un modelo que encapsula las relaciones entre entidades.
Modelos multimodales
El éxito de los transformadores como una manera de crear modelos de lenguaje ha llevado a los investigadores de inteligencia artificial a considerar si el mismo enfoque sería eficaz para datos de imagen. El resultado es el desarrollo de modelos multimodales, en los que el modelo se entrena mediante un gran volumen de imágenes con descripción, sin etiquetas fijas. Un codificador de imágenes extrae características de imágenes basadas en valores de píxeles y las combina con incrustaciones de texto creadas por un codificador de lenguaje. El modelo general encapsula las relaciones entre las incrustaciones de tokens de lenguaje natural y las características de imagen, tal y como se muestra aquí:
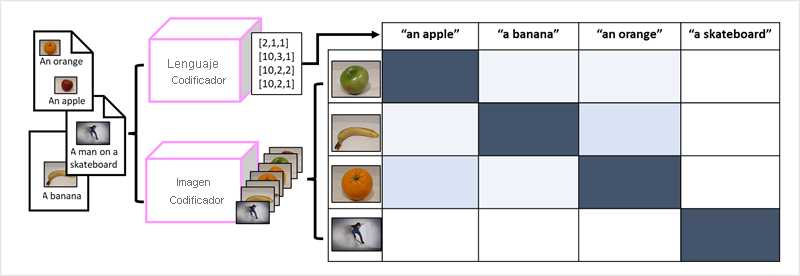
El modelo de Microsoft Florence es simplemente un modelo de este tipo. Entrenado con grandes volúmenes de imágenes con descripción de Internet, incluye un codificador de idioma y un codificador de imágenes. Florence es un ejemplo de un modelo de base. Es decir, un modelo general entrenado previamente en el que se pueden crear varios modelos adaptables para tareas especializadas. Por ejemplo, se puede usar Florence como modelo de base para los modelos adaptables que realizan:
- Clasificación de imágenes: Identificación de la categoría a la que pertenece una imagen.
- Detección de objetos: Buscar objetos individuales dentro de una imagen.
- Subtitulado: Generar descripciones adecuadas de imágenes.
- Etiquetado: Compilar una lista de etiquetas de texto relevantes para una imagen.

Los modelos multimodales, como Florence, están a la vanguardia de la visión general sobre informática e inteligencia artificial, y se espera que lideren los avances de aquellos tipos de soluciones que la inteligencia artificial haga posible.