Ejercicio: Análisis de datos con Seaborn
Una de las cosas interesantes sobre Azure Notebooks, y Python en general, es que hay miles de bibliotecas de código abierto que se pueden aprovechar para realizar tareas complejas sin escribir mucho código. En esta unidad se usa Seaborn, una biblioteca para la visualización estadística, para trazar el segundo de los dos conjuntos de datos cargados, que cubre los años 1882 a 2014. Seaborn puede crear una línea de regresión acompañada de una proyección que muestra dónde deberían estar los puntos de datos en función de la regresión con una simple llamada de función.
Coloque el cursor en la celda vacía de la parte inferior del cuaderno. Cambie el tipo de celda a Markdown y escriba "Realizar regresión lineal con Seaborn" como texto.
Agregue una celda de tipo Código y pegue el siguiente código.
plt.scatter(years, mean) plt.title('scatter plot of mean temp difference vs year') plt.xlabel('years', fontsize=12) plt.ylabel('mean temp difference', fontsize=12) sns.regplot(yearsBase, meanBase) plt.show()Ejecute la celda de código para generar un gráfico de dispersión con una línea de regresión y una representación visual del intervalo en el que se espera que se encuentren los puntos de datos.
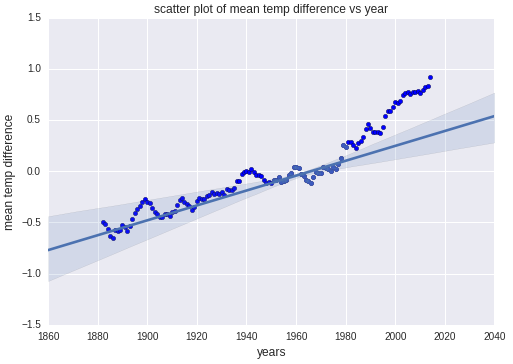
Comparación de valores reales y valores de predicción generados con Seaborn
Observe que los puntos de datos de los primeros 100 años se ajustan perfectamente a los valores de predicción, pero que los puntos de datos de aproximadamente 1980 en adelante no. Son modelos como estos los que llevan a los científicos a creer que el cambio climático se está acelerando.