Indexación de datos JSON
Se aplica a: ![]() SQL Server 2016 (13.x) y versiones posteriores
SQL Server 2016 (13.x) y versiones posteriores ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Puede optimizar las consultas en documentos JSON mediante índices estándar. SQL Server no tiene índices JSON personalizados.
- Actualmente, json de SQL Server no es un tipo de datos integrado.
- El tipo de datos JSON se encuentra actualmente en versión preliminar para Azure SQL Database y Azure SQL Instancia administrada (configurado con la directiva de actualización siempre actualizada).
Los índices funcionan de la misma manera en los datos JSON en varchar/nvarchar o en el tipo de datos json nativo.
Los índices de la base de datos mejoran el rendimiento de las operaciones de filtro y ordenación. Sin ellos, SQL Server debe realizar un examen completo de la tabla cada vez que realice consultas de datos.
Indexación de propiedades JSON mediante columnas calculadas
Al almacenar datos JSON en SQL Server, normalmente querrá filtrar u ordenar resultados de consultas por una o varias propiedades de los documentos JSON.
Ejemplo
En este ejemplo se supone que la tabla AdventureWorks.SalesOrderHeader tiene una columna Info, que contiene diversa información en formato JSON sobre pedidos de venta. Por ejemplo, contiene datos no estructurados sobre el cliente, el vendedor, las direcciones de envío y facturación, etc. Podría usar los valores de la columna Info para filtrar los pedidos de venta de un cliente.
De forma predeterminada, la columna Info usada no existe, pero se puede crear en la base de datos AdventureWorks con el código siguiente. Los ejemplos siguientes no se aplican a la serie AdventureWorksLT de bases de datos de ejemplo.
IF NOT EXISTS(SELECT * FROM sys.columns WHERE object_id = OBJECT_ID('[Sales].[SalesOrderHeader]') AND name = 'Info')
ALTER TABLE [Sales].[SalesOrderHeader] ADD [Info] NVARCHAR(MAX) NULL
GO
UPDATE h
SET [Info] =
(
SELECT [Customer.Name] = concat(p.FirstName, N' ', p.LastName),
[Customer.ID] = p.BusinessEntityID,
[Customer.Type] = p.[PersonType],
[Order.ID] = soh.SalesOrderID,
[Order.Number] = soh.SalesOrderNumber,
[Order.CreationData] = soh.OrderDate,
[Order.TotalDue] = soh.TotalDue
FROM [Sales].SalesOrderHeader AS soh
INNER JOIN [Sales].[Customer] AS c ON c.CustomerID = soh.CustomerID
INNER JOIN [Person].[Person] AS p ON p.BusinessEntityID = c.CustomerID
WHERE soh.SalesOrderID = h.SalesOrderID FOR JSON PATH, WITHOUT_ARRAY_WRAPPER
)
FROM [Sales].SalesOrderHeader AS h;
Consulta que se optimizará
Aquí tiene un ejemplo del tipo de consulta que quiere optimizar mediante un índice.
SELECT SalesOrderNumber,
OrderDate,
JSON_VALUE(Info, '$.Customer.Name') AS CustomerName
FROM Sales.SalesOrderHeader
WHERE JSON_VALUE(Info, '$.Customer.Name') = N'Aaron Campbell'
Índice de ejemplo
Si quiere acelerar los filtros o las cláusulas ORDER BY en una propiedad de un documento JSON, puede usar los mismos índices que ya use en otras columnas. En cambio, no puede hacer referencia directamente a las propiedades de los documentos JSON.
- Primero, cree una "columna virtual" que devuelva los valores que quiere utilizar para las operaciones de filtro.
- Después, cree un índice de esa columna virtual.
En el ejemplo siguiente se crea una columna calculada que se puede usar para la indexación. Después, crea un índice en la nueva columna calculada. En este ejemplo se crea una columna que muestra el nombre del cliente, que se almacena en la ruta de acceso $.Customer.Name de los datos JSON.
ALTER TABLE Sales.SalesOrderHeader
ADD vCustomerName AS JSON_VALUE(Info,'$.Customer.Name')
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
Esta instrucción devolverá la siguiente advertencia:
Warning! The maximum key length for a nonclustered index is 1700 bytes.
The index 'vCustomerName' has maximum length of 8000 bytes.
For some combination of large values, the insert/update operation will fail.
La función JSON_VALUE podría devolver valores de texto de hasta 8000 bytes, por ejemplo, como el tipo nvarchar(4000). Sin embargo, los valores de más de 1700 bytes no se pueden indexar. Si intenta escribir el valor en la columna calculada indexada que tiene más de 1700 bytes, se producirá un error en la operación del lenguaje de manipulación de datos (DML).
Para mejorar el rendimiento, intente convertir el valor que expone con la columna calculada en el tipo de datos aplicable más pequeño. Los tipos int y datetime2 en lugar de los tipos de cadena.
Más información sobre la columna calculada
La columna calculada no se conserva. La columna calculada solo calcula cuando hay que volver a generar el índice. No ocupa espacio adicional en la tabla.
Es importante que cree la columna calculada con la misma expresión que tiene pensado usar en las consultas. En este ejemplo, la expresión es JSON_VALUE(Info, '$.Customer.Name').
No tiene que volver a escribir las consultas. Si se usan expresiones con la función JSON_VALUE, como se muestra en la consulta de ejemplo anterior, SQL Server considera que hay una columna calculada equivalente con la misma expresión y aplica un índice, si es posible.
Plan de ejecución de este ejemplo
Este es el plan de ejecución de la consulta de este ejemplo.
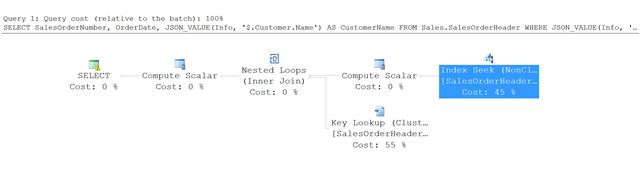
En lugar examinar toda la tabla, SQL Server busca un índice en el índice no agrupado e identifica las filas que satisfacen las condiciones especificadas. Después, realiza una búsqueda de claves en la tabla SalesOrderHeader para capturar las otras columnas a las que se hace referencia en la consulta (en este ejemplo, SalesOrderNumber y OrderDate).
Mayor optimización del índice con la inclusión de columnas
Si agrega las columnas necesarias al índice, podrá evitar esta búsqueda adicional en la tabla. Puede agregar estas columnas como columnas incluidas estándar, tal y como se muestra en el ejemplo siguiente, que amplía el ejemplo CREATE INDEX anterior.
CREATE INDEX idx_soh_json_CustomerName
ON Sales.SalesOrderHeader(vCustomerName)
INCLUDE(SalesOrderNumber,OrderDate)
En este caso, SQL Server no tiene que leer más datos de la tabla SalesOrderHeader, ya que todo lo que necesita se incluye en el índice JSON no agrupado. Este tipo de índice es una buena forma de combinar datos JSON y de columna en las consultas y de crear índices óptimos para la carga de trabajo.
Los índices JSON son índices de intercalación
Una característica importante de los índices basados en datos JSON es que son compatibles con la intercalación. El resultado de la función JSON_VALUE que usa al crear la columna calculada es un valor de texto que hereda la intercalación de la expresión de entrada. Por tanto, los valores del índice se ordenan con las reglas de intercalación definidas en las columnas de origen.
Para demostrar que los índices son de intercalación, en el ejemplo siguiente se crea una tabla de colección simple con una clave principal y el contenido JSON.
CREATE TABLE JsonCollection
(
id INT IDENTITY CONSTRAINT PK_JSON_ID PRIMARY KEY,
[json] NVARCHAR(MAX) COLLATE SERBIAN_CYRILLIC_100_CI_AI
CONSTRAINT [Content should be formatted as JSON]
CHECK(ISJSON(json)>0)
)
El comando anterior especifica la intercalación del serbio (cirílico) para la columna json. En el ejemplo siguiente se rellena la tabla y crea un índice en la propiedad name.
INSERT INTO JsonCollection
VALUES
(N'{"name":"Иво","surname":"Андрић"}'),
(N'{"name":"Андрија","surname":"Герић"}'),
(N'{"name":"Владе","surname":"Дивац"}'),
(N'{"name":"Новак","surname":"Ђоковић"}'),
(N'{"name":"Предраг","surname":"Стојаковић"}'),
(N'{"name":"Михајло","surname":"Пупин"}'),
(N'{"name":"Борислав","surname":"Станковић"}'),
(N'{"name":"Владимир","surname":"Грбић"}'),
(N'{"name":"Жарко","surname":"Паспаљ"}'),
(N'{"name":"Дејан","surname":"Бодирога"}'),
(N'{"name":"Ђорђе","surname":"Вајферт"}'),
(N'{"name":"Горан","surname":"Бреговић"}'),
(N'{"name":"Милутин","surname":"Миланковић"}'),
(N'{"name":"Никола","surname":"Тесла"}')
GO
ALTER TABLE JsonCollection
ADD vName AS JSON_VALUE(json,'$.name')
CREATE INDEX idx_name
ON JsonCollection(vName)
Los comandos anteriores crean un índice estándar de la columna calculada vName, que representa el valor de la propiedad JSON $.name. En la página de códigos del serbio cirílico, el orden de las letras es А, Б, В, Г, Д, Ђ, Е, etc. El orden de los elementos del índice cumple las reglas del serbio cirílico porque el resultado de la función JSON_VALUE hereda la intercalación de la columna de origen. En el ejemplo siguiente se realiza una consulta de esta colección y se ordenan los resultados por nombre.
SELECT JSON_VALUE(json,'$.name'),*
FROM JsonCollection
ORDER BY JSON_VALUE(json,'$.name')
Si observa el plan de ejecución real, verá que emplea los valores ordenados del índice no agrupado.

Aunque la consulta tiene una cláusula ORDER BY, el plan de ejecución no usa un operador Sort. El índice JSON ya está ordenado según reglas del serbio (cirílico). Por lo tanto, SQL Server puede utilizar el índice no agrupado donde los resultados ya están ordenados.
A pesar de esto, si cambia la intercalación de la expresión ORDER BY (por ejemplo, si agrega COLLATE French_100_CI_AS_SC después de la función JSON_VALUE), recibirá otro plan de ejecución de consulta.

Puesto que el orden de los valores en el índice no cumple las reglas de intercalación del francés, SQL Server no puede utilizar el índice para ordenar los resultados. Por lo tanto, agrega un operador Sort que ordena los resultados mediante las reglas de intercalación del francés.
Vídeos de Microsoft
Nota:
Es posible que algunos de los vínculos de vídeo de esta sección no funcionen en este momento. Microsoft está migrando contenido que anteriormente estaba en Channel 9 a una nueva plataforma. Actualizaremos los vínculos a medida que los vídeos se migren a la nueva plataforma.
Para obtener una introducción visual a la compatibilidad integrada de JSON en SQL Server y Azure SQL Database, vea los siguientes vídeos:
- JSON as a bridge between NoSQL and relational worlds (JSON como puente entre los universos NoSQL y relacional)