Introducción a los índices de almacén de columnas
Se aplica a: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW) ![]() Base de datos SQL de Microsoft Fabric
Base de datos SQL de Microsoft Fabric
Los índices de almacén de columnas son el estándar para almacenar y consultar las tablas de hechos de almacenamiento de datos de gran tamaño. Este índice usa el almacenamiento de datos basado en columnas y el procesamiento de consultas para lograr ganancias de hasta 10 veces el rendimiento de las consultas en el almacenamiento de datos sobre el almacenamiento tradicional orientado a filas. También puede lograr ganancias de hasta 10 veces la compresión de datos sobre el tamaño de los datos sin comprimir. Desde SQL Server 2016 (13.x) SP1, los índices de almacén de columnas permiten los análisis operativos, es decir, ejecutar análisis del rendimiento en tiempo real en una carga de trabajo transaccional.
Obtenga información sobre un escenario relacionado:
- Índices de almacén de columnas en el almacenamiento de datos
- Introducción al almacén de columnas para análisis operativos en tiempo real
¿Qué es un índice de almacén de columnas?
Un índice de almacén de columnas es una tecnología de almacenamiento, recuperación y administración de datos que emplea un formato de datos en columnas denominado almacén de columnas.
Términos y conceptos clave
Los términos y conceptos clave siguientes están asociados a los índices de almacén de columnas.
columnstore
Un almacén de columnas son datos organizados lógicamente como una tabla con filas y columnas, y almacenados físicamente en un formato de columnas.
Almacén de filas
Un almacén de filas son datos organizados lógicamente como una tabla con filas y columnas, y almacenados físicamente en un formato de filas. Este formato es la forma tradicional de almacenar los datos de una tabla relacional. En SQL Server, el almacén de filas hace referencia a una tabla en la que el formato de almacenamiento de datos subyacente es un montón, un índice agrupado o una tabla optimizada para memoria.
Nota:
Al tratar los índices de almacén de columnas, usamos los términos almacén de filas y almacén de columnas para hacer hincapié en el formato del almacenamiento de datos.
Grupo de filas
En un grupo de filas, las filas se comprimen al mismo tiempo con el formato del almacén de columnas. Un grupo de filas suele contener el número máximo de filas por grupo, que es 1 048 576 filas.
Para conseguir unas tasas elevadas de rendimiento y compresión, el índice de almacén de columnas segmenta la tabla en grupos de filas y luego comprime cada grupo de filas a modo de columna. El número de filas del grupo de filas debe ser suficientemente grande como para mejorar las tasas de compresión y suficientemente pequeño como para beneficiarse de las operaciones en memoria.
Un grupo de filas del que se han eliminado todos los datos pasa del estado COMPRESSED al estado TOMBSTONE, y luego se elimina mediante un proceso en segundo plano denominado "motor de tupla". Para obtener más información sobre los estados de filas, vea sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Sugerencia
Tener demasiados grupos de filas pequeños reduce la calidad del índice de almacén de columnas. Hasta SQL Server 2017 (14.x), se requiere una operación de reorganización para combinar grupos de filas COMPRESSED más pequeños, siguiendo una directiva de umbral interno que determina cómo quitar las filas eliminadas y combinar los grupos de filas comprimidos.
A partir de SQL Server 2019 (15.x), una tarea de combinación en segundo plano también funciona para combinar filas de grupos COMPRESSED de donde se ha eliminado un gran número de filas.
Después de combinar grupos de filas más pequeños, se debe mejorar la calidad del índice.
Nota:
A partir de SQL Server 2019 (15.x), Azure SQL Database y Azure SQL Managed Instance, y grupos de SQL dedicados en Azure Synapse Analytics, el motor de tuplas cuenta con la ayuda de una tarea de combinación en segundo plano que comprime automáticamente los grupos de filas delta OPEN más pequeños que han existido durante algún tiempo, según lo determinado por un umbral interno, o combina los grupos de filas COMPRESSED desde donde se ha eliminado un gran número de filas. De este modo, se mejora la calidad del índice de almacén de columnas a lo largo del tiempo.
Segmento de columna
Un segmento de columna es una columna de datos perteneciente al grupo de filas.
- Cada grupo de filas contiene un segmento de cada columna de la tabla.
- Cada sector de columna se comprime junto y se almacena en un medio físico.
- Hay metadatos con cada segmento para permitir la eliminación rápida de segmentos sin leerlos.
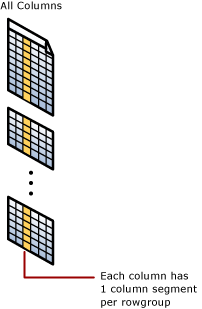
Índice de almacén de columnas agrupado
Un índice de almacén de columnas agrupado es el almacenamiento físico de toda la tabla.
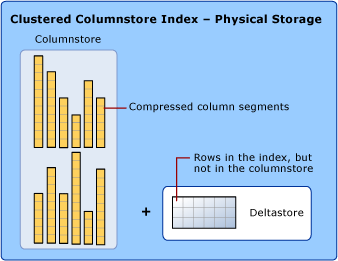
Para reducir la fragmentación de los segmentos de columna y mejorar el rendimiento, el índice de almacén de columnas puede almacenar temporalmente algunos datos en un índice agrupado (denominado almacén delta), así como una lista en forma de árbol B de los identificadores de las filas eliminadas. Las operaciones del almacén delta se administran en segundo plano. Para devolver los resultados correctos de la consulta, el índice clúster de almacén de columnas combina los resultados de la consulta tanto del almacén de columnas como del almacén delta.
Nota:
La documentación utiliza el término árbol B generalmente en referencia a los índices. En los índices del almacén de filas, el motor de la base de datos implementa un árbol B+. Esto no se aplica a los índices de almacén de columnas ni a los índices de tablas optimizadas para memoria. Para obtener más información, consulte la guía de diseño y arquitectura de índices de SQL Server y Azure SQL.
Grupo de filas delta
Un grupo de filas delta es un índice de árbol B agrupado que solo se usa con índices de almacén de columnas. Mejora el rendimiento y la compresión del almacén de columnas mediante el almacenamiento de filas hasta que el número de filas alcanza un umbral (1 048 576 filas) y luego se mueve al almacén de columnas.
Cuando un grupo de filas delta alcanza el número máximo de filas, pasa de un estado OPEN a un estado CLOSED. Un proceso en segundo plano denominado "motor de tupla" comprueba si hay grupos de filas cerrados. Si el proceso encuentra un grupo de filas cerrado, comprime el grupo de filas delta y lo almacena en el almacén de columnas como un grupo de filas COMPRESSED.
Cuando se ha comprimido un grupo de filas delta, el grupo de filas delta existente pasa al estado TOMBSTONE para que lo quite más adelante el motor de tupla cuando no haya referencias a él.
Para obtener más información sobre los estados de filas, vea sys.dm_db_column_store_row_group_physical_stats (Transact-SQL).
Nota:
A partir de SQL Server 2019 (15.x), el motor de tupla cuenta con la ayuda de una tarea de combinación en segundo plano que comprime automáticamente los grupos de filas delta OPEN que han existido durante algún tiempo, según lo determinado por un umbral interno, o combina los grupos de filas COMPRESSED desde donde se ha eliminado un gran número de filas. De este modo, se mejora la calidad del índice de almacén de columnas a lo largo del tiempo.
Almacén delta
Un índice de almacén de columnas puede tener más de un grupo de filas delta. Todos los grupos de filas delta se denominan colectivamente almacén delta.
Durante una gran carga masiva, la mayoría de las filas van directamente al almacén de columnas sin pasar por el almacén delta. Al final de la carga masiva, podría quedar un número de filas menor que el tamaño mínimo de un grupo de filas, que es 102 400 filas. Como resultado, las últimas filas van al almacén delta en lugar de al almacén de columnas. En el caso de cargas masivas pequeñas con menos de 102.400 filas, todas las filas van directamente al almacén delta.
índice no clúster de almacén de columnas
Un índice de almacén de columnas no agrupado y un índice de almacén de columnas agrupado funcionan del mismo modo. La diferencia es que un índice no agrupado es un índice secundario creado en una tabla de almacén de filas, pero un índice de almacén de columnas agrupado es el almacenamiento principal de toda la tabla.
El índice no agrupado contiene una copia de parte o la totalidad de las filas y columnas de la tabla subyacente. El índice se define como una o varias columnas de la tabla y tiene una condición opcional que filtra las filas.
Un índice de almacén de columnas no agrupado permite análisis operativos en tiempo real donde la carga de trabajo OLTP usa el índice agrupado subyacente mientras los análisis se ejecutan simultáneamente en el índice de almacén de columnas. Para más información, consulte Introducción al almacén de columnas para análisis operativos en tiempo real.
Ejecución del modo por lotes
La ejecución del modo por lotes es un método de procesamiento de consultas que se usa para procesar varias filas a la vez. La ejecución del modo por lotes está estrechamente integrada con el formato de almacenamiento de almacén de columnas y optimizada alrededor del mismo. La ejecución en modo por lotes se conoce en ocasiones como ejecución basada en vectores o vectorizada. Las consultas de los índices de almacén de columnas usan la ejecución en modo por lotes, ya que suele duplicar o hasta cuadruplicar el rendimiento de las consultas. Para más información, consulte la Guía de arquitectura de procesamiento de consulta.
¿Por qué debo usar un índice de almacén de columnas?
Un índice de almacén de columnas puede proporcionar un nivel muy alto de compresión de datos, normalmente hasta 10 veces superior, para reducir considerablemente el costo de almacenamiento del almacén de datos. Para el análisis, un índice de almacén ofrece un mejor rendimiento de orden de magnitud que un índice de árbol B. Los índices de almacén de columnas son el formato de almacenamiento de datos preferido para cargas de trabajo de análisis y almacenamiento de datos. Desde SQL Server 2016 (13.x), puede usar índices de almacén de columnas para llevar a cabo análisis operativos en tiempo real en la carga de trabajo operativa.
Motivos por los que los índices de almacén de columnas son tan rápidos:
Las columnas almacenan valores del mismo dominio y normalmente tienen valores similares, lo que resulta en altas tasas de compresión. Los cuellos de botella de E/S del sistema se minimizan o eliminan y la superficie de memoria se disminuye considerablemente.
Los factores de compresión altos mejoran el rendimiento de las consultas mediante la utilización de una superficie en memoria menor. A su vez, el rendimiento de las consultas puede mejorar porque SQL Server puede realizar más consultas y operaciones de datos en memoria.
La ejecución por lotes mejora el rendimiento de las consultas, hasta llegar a duplicarlo o cuadruplicarlo, ya que procesa varias filas juntas.
Con frecuencia, las consultas seleccionan únicamente unas pocas columnas de una tabla, lo que reduce la E/S total desde los medios físicos.
¿Cuándo debo usar un índice de almacén de columnas?
Casos de uso recomendados:
Use un índice de almacén de columnas agrupado para almacenar tablas de hechos y tablas de dimensiones grandes de cargas de trabajo de almacenamiento de datos. Este método mejora el rendimiento de las consultas y la compresión de datos, hasta multiplicarlos por diez. Para más información, consulte Índices de almacén de columnas para el almacenamiento de datos.
Use un índice de almacén de columnas no agrupado para realizar análisis en tiempo real en una carga de trabajo OLTP. Para más información, consulte Introducción al almacén de columnas para análisis operativos en tiempo real.
Para obtener más escenarios de uso para los índices de almacén de columnas, consulte Elección del mejor índice de almacén de columnas para sus necesidades.
¿Cómo elegir entre un índice de almacén de filas y un índice de almacén de columnas?
Los índices de almacén de filas tienen un mejor rendimiento en las consultas que buscan en datos, cuando se busca un valor determinado o en las consultas realizadas en un rango de valores muy acotado. Use índices de almacén de filas en las cargas de trabajo transaccionales, porque tienden a necesitar búsquedas de tabla, más que recorridos de tabla.
Los índices de almacén de columnas ofrecen un alto rendimiento en consultas analíticas en las que se analizan grandes cantidades de datos, especialmente en tablas grandes. Use índices de almacén de columnas en cargas de trabajo de análisis y almacenamiento de datos, especialmente en las tablas de hechos, porque tienden a necesitar recorridos de tabla completos, más que búsquedas de tabla.
Los índices de almacén de columnas agrupados ordenados mejoran el rendimiento de las consultas basadas en predicados de columna ordenados. Los índices de almacén de columnas ordenados pueden mejorar la eliminación de grupos de filas, lo que puede ofrecer mejoras de rendimiento omitiendo por completo los grupos de filas. Para más información, consulte Optimización del rendimiento con índices de almacén de columnas agrupados ordenados. Para obtener disponibilidad ordenada del índice de almacén de columnas, consulte Disponibilidad de índices de columna ordenada.
¿Puedo combinar un almacén de filas y un almacén de columnas en la misma tabla?
Sí. Desde SQL Server 2016 (13.x), puede crear un índice de almacén de columnas no agrupado actualizable en una tabla de almacén de filas. El índice de almacén de columnas almacena una copia de las columnas seleccionadas, por lo que necesita espacio adicional para estos datos, pero los datos seleccionados se comprimen 10 veces en promedio. Puede ejecutar análisis en el índice de almacén de columnas y realizar transacciones en el índice de almacén de filas al mismo tiempo. El almacén de columnas se actualiza cuando cambian los datos de la tabla de almacén de filas, de modo que ambos índices trabajan con los mismos datos.
Desde SQL Server 2016 (13.x), puede tener uno o varios índices de almacén de filas en un índice de almacén de columnas y realizar búsquedas eficientes de tabla en el almacén de columnas subyacente. También habrá disponibles otras opciones. Por ejemplo, podrá aplicar una restricción de clave principal mediante una restricción UNIQUE en la tabla de almacén de filas. Como un valor que no es único no se inserta en la tabla de almacén de filas, SQL Server no puede insertar ese valor en el almacén de columnas.
Índices de almacén de columnas ordenados
Al habilitar la eliminación eficaz de segmentos, los índices de almacén de columnas agrupados ordenados (CCI) proporcionan un rendimiento mucho más rápido omitiendo grandes cantidades de datos ordenados que no coinciden con el predicado de consulta. La carga de datos en una tabla de CCI ordenado puede tardar más que en una tabla de CCI no ordenado debido a la operación de ordenación de datos; sin embargo, posteriormente las consultas podrán ejecutarse más rápidamente con el CCI ordenado.
- Para obtener más información sobre el ajuste del rendimiento de las cargas de trabajo de almacenamiento de datos en el Motor de base de datos sql con índices de almacén de columnas agrupados ordenados, consulte Optimización del rendimiento con índices de almacén de columnas agrupados ordenados.
- Para obtener más información sobre cuándo usar el tipo de índice de almacén de columnas, vea Elegir el mejor índice de almacén de columnas para sus necesidades.
Disponibilidad ordenada del índice de almacén de columnas
En primer lugar, se presentan con ![]() SQL Server 2022 (16.x), los índices de almacén de columnas ordenados están disponibles en las siguientes plataformas.
SQL Server 2022 (16.x), los índices de almacén de columnas ordenados están disponibles en las siguientes plataformas.
| Plataforma | Índices de almacén de columnas agrupados ordenados | Índices de almacén de columnas no agrupados ordenados |
|---|---|---|
| Azure SQL Database | Sí | Sí |
| Base de datos SQL de Microsoft Fabric | Sí* | Sí |
| SQL Server 2022 (16.x) | Sí | No |
| Instancia administrada de Azure SQL | Sí | Sí |
| Grupo de SQL dedicado en Azure Synapse Analytics | Sí | No |
* En la base de datos SQL de Fabric, las tablas con índices de almacén de columnas agrupados no se reflejan en Fabric OneLake.
Metadatos
Todas las columnas de un índice de almacén de columnas se almacenan en los metadatos como columnas incluidas. El índice de almacén de columnas no tiene columnas de clave.
Tareas relacionadas
Todas las tablas relacionales (a menos que se especifiquen como un índice de almacén de columnas no agrupado) usan el almacén de filas como formato de datos subyacente. CREATE TABLE crea una tabla de almacén de filas a menos que especifique la opción WITH CLUSTERED COLUMNSTORE INDEX.
Cuando se crea una tabla con la instrucción CREATE TABLE, puede crearla como un almacén de columnas especificando la opción WITH CLUSTERED COLUMNSTORE INDEX. Si ya tiene una tabla de almacén de filas y quiere convertirla en un almacén de columnas, puede usar la instrucción CREATE COLUMNSTORE INDEX.
| Tarea | Artículos de referencia | Notas |
|---|---|---|
| Crear una tabla como un almacén de columnas. | CREATE TABLE (Transact-SQL) | A partir de SQL Server 2016 (13.x), puede crear la tabla como un índice agrupado de almacén de columnas. No es necesario crear primero una tabla de almacén de filas y, luego, convertirla en almacén de columnas. |
| Crear una tabla optimizada para memoria con un índice de almacén de columnas. | CREATE TABLE (Transact-SQL) | Desde SQL Server 2016 (13.x), puede crear una tabla optimizada para memoria con un índice de almacén de columnas. El índice de almacén de columnas también se puede agregar una vez creada la tabla mediante el uso de la sintaxis de ALTER TABLE ADD INDEX. |
| Convertir una tabla de almacén de filas en un almacén de columnas. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Convierta un montículo o árbol B existentes en un almacén de columnas. Los ejemplos muestran cómo tratar los índices existentes, así como el nombre del índice, al realizar esta conversión. |
| Convertir una tabla de almacén de columnas en un almacén de filas. | CREATE CLUSTERED INDEX (Transact-SQL) o Volver a convertir una tabla de almacén de columnas en un montón de almacén de filas | Habitualmente, esta conversión no es necesaria pero puede haber ocasiones en las que necesite realizarla. Los ejemplos muestran cómo convertir un almacén de columnas en un montón o un índice agrupado. |
| Crear un índice de almacén de columnas en una tabla de almacén de filas. | CREATE COLUMNSTORE INDEX (Transact-SQL) | Una tabla de almacén de filas puede tener un índice de almacén de columnas. Desde SQL Server 2016 (13.x), los índices de almacén de columnas pueden tener una condición de filtrado. En los ejemplos se usa la sintaxis básica. |
| Crear índices de rendimiento para análisis operativos. | Introducción al almacén de columnas para análisis operativos en tiempo real | Se describe cómo crear índices de almacén de columnas y de árbol B complementarios para que las consultas OLTP usen los índices de árbol B y, las consultas de análisis, los índices de almacén de columnas. |
| Crear índices de almacén de columnas de rendimiento para el almacenamiento de datos. | Índices de almacén de columnas para almacenamiento de datos | Se describe cómo usar índices de árbol B en las tablas de almacén de columnas para crear consultas de almacenamiento de datos de rendimiento. |
| Usar un índice de árbol B para aplicar una restricción de clave principal en un índice de almacén de columnas. | Índices de almacén de columnas para almacenamiento de datos | Se muestra cómo combinar índices de árbol B y de almacén de columnas para aplicar restricciones de clave principal en el índice de almacén de columnas. |
| Eliminar un índice de almacén de columnas. | DROP INDEX (Transact-SQL) | Para eliminar un índice de almacén de columnas, se usa la sintaxis de DROP INDEX estándar que usan los índices de árbol B. Si se elimina un índice de almacén de columnas agrupado, la tabla de almacén de columnas se convierte en un montón. |
| Eliminar una fila de un índice de almacén de columnas. | DELETE (Transact-SQL) | Use DELETE (Transact-SQL) para eliminar una fila. fila de almacén de columna: SQL Server marca la fila como eliminada lógicamente, pero no recupera el almacenamiento físico de la fila hasta que se vuelva a generar el índice. fila de almacén delta: SQL Server elimina la fila lógica y físicamente. |
| Actualizar una fila en el índice de almacén de columnas. | UPDATE (Transact-SQL) | Use UPDATE (Transact-SQL) para actualizar una fila. fila de almacén de columna: SQL Server marca la fila como eliminada lógicamente y, después, inserta la fila actualizada en el almacén delta. fila almacén delta: SQL Server actualiza la fila en el almacén delta. |
| Cargar datos en un índice de almacén de columnas. | Carga de datos de índices de almacén de columnas | |
| Forzar que todas las filas del almacén delta vayan al almacén de columnas. | ALTER INDEX (Transact-SQL) ... REBUILDOptimización del mantenimiento de índices para mejorar el rendimiento de las consultas y reducir el consumo de recursos |
ALTER INDEX con la opción REBUILD hace que todas las filas vayan al almacén de columnas. |
| Desfragmentar un índice de almacén de columnas. | ALTER INDEX (Transact-SQL) | ALTER INDEX ... REORGANIZE desfragmenta los índices de almacén de columnas en línea. |
| Combinar tablas con índices de almacén de columnas. | MERGE (Transact-SQL) |
Contenido relacionado
- Novedades de los índices de almacén de columnas
- Índices de almacén de columnas: Guía de carga de datos
- Rendimiento de las consultas de índices de almacén de columnas
- Introducción al almacén de columnas para análisis operativos en tiempo real
- Índices de almacén de columnas en el almacenamiento de datos
- Desfragmentación de índices de almacén de columnas
- Guía de diseño y de arquitectura de índices de SQL Server y Azure SQL
- Diseño de los índices de almacén de columnas
- CREATE COLUMNSTORE INDEX (Transact-SQL)