Grupos de disponibilidad para SQL Server en Linux
Se aplica a: ![]() SQL Server - Linux
SQL Server - Linux
En este artículo se describen las características de los grupos de disponibilidad (AG) en instalaciones de SQL Server basadas en Linux. También se tratan las diferencias entre los AG basados en el clúster de conmutación por error de Windows Server (WSFC) y Linux. Consulte Introducción al grupo de disponibilidad Always On para conocer los conceptos básicos de los grupos de disponibilidad, ya que funcionan igual en Windows y Linux, excepto en WSFC.
Nota:
En los grupos de disponibilidad que no usan clústeres de conmutación por error de Windows Server (WSFC), como grupos de disponibilidad de escala de lectura o grupos de disponibilidad en Linux, las columnas de los grupos de disponibilidad de DMV relacionadas con el clúster pueden mostrar datos sobre un clúster predeterminado interno. Estas columnas son solo para uso interno y se pueden ignorar.
Desde un punto de vista de alto nivel, los SQL Server grupos de disponibilidad bajo en Linux son los mismos que los de las implementaciones basadas en WSFC. Esto significa que todas las limitaciones y características son las mismas, con algunas excepciones. Las principales diferencias estriban en lo siguiente:
- El Coordinador de transacciones distribuidas de Microsoft (DTC) es compatible con Linux a partir de SQL Server 2017 CU 16. Pero el DTC todavía no es compatible con los grupos de disponibilidad en Linux. Si las aplicaciones requieren el uso de transacciones distribuidas y necesitan un AG, implemente SQL Server en Windows.
- Las implementaciones basadas en Linux que requieren alta disponibilidad usan Pacemaker para la agrupación en clústeres en lugar de un WSFC.
- A diferencia de la mayoría de las configuraciones de AG en Windows, excepto en el caso del escenario de clúster de grupo de trabajo, Pacemaker nunca necesita Active Directory Domain Services (AD DS).
- El modo en que se produce un error en un AG de un nodo a otro es diferente en Linux y Windows.
- Ciertas opciones de configuración, como
required_synchronized_secondaries_to_commit, solo se pueden cambiar a través de Pacemaker en Linux, mientras que una instalación basada en WSFC utiliza Transact-SQL.
Número de réplicas y nodos de clúster
Un AG en SQL Server Standard puede tener dos réplicas en total: una principal y otra secundaria, que solo se puede usar con fines de disponibilidad. No se puede usar para nada más, como consultas legibles. Un AG en SQL Server Enterprise puede tener hasta nueve réplicas en total: una principal y hasta ocho secundarias, de las cuales tres (incluida la principal) pueden ser sincrónicas. Si usa un clúster subyacente, puede haber un máximo de 16 nodos en total cuando Corosync está implicado. Un grupo de disponibilidad puede abarcar como máximo 9 de los 16 nodos con SQL Server Enterprise y dos con SQL Server Standard.
Una configuración de dos réplicas que requiere la capacidad de conmutar por error automáticamente a otra réplica requiere el uso de una réplica de solo configuración, tal como se describe en Réplica de solo configuración y cuórum. Las réplicas de solo configuración se introdujeron en la actualización acumulativa 1 (CU 1) de SQL Server 2017 (14.x), por lo que debe ser la versión mínima implementada para esta configuración.
Si se usa Pacemaker, debe configurarse correctamente para que siga funcionando. Esto significa que cuórum y la creación de barreras en un nodo con errores se deben implementar correctamente desde una perspectiva de Pacemaker, además de los requisitos de SQL Server como una réplica de solo configuración.
Las réplicas secundarias legibles solo se admiten con SQL Server Enterprise.
Tipo de clúster y modo de conmutación por error
Una novedad en SQL Server 2017 (14.x) es la introducción de un tipo de clúster para AG. Para Linux, hay dos valores válidos: External y None. Un tipo de clúster External significa que Pacemaker se usa debajo del AG. El uso del tipo External para el clúster requiere que el modo de conmutación por error se establezca también en External (esto también es nuevo en SQL Server 2017 (14.x)). Se admite la conmutación automática por error, pero a diferencia de WSFC, el modo de conmutación por error se establece en External, no en automático, cuando se usa Pacemaker. A diferencia de un WSFC, la parte de Pacemaker del AG se crea después de configurar el AG.
Un tipo de clúster None significa que no hay ningún requisito de Pacemaker y que el AF no lo usa. Incluso en los servidores que tienen configurado Pacemaker, si un AG está configurado con un tipo de clúster None, Pacemaker no ve ni administra ese AG. Un tipo de clúster de None solo admite la conmutación por error manual de una réplica principal a una secundaria. Un grupo de disponibilidad creado con None se destina principalmente a actualizaciones y escalado horizontal de lectura. Aunque puede funcionar en escenarios como la recuperación ante desastres o la disponibilidad local donde no es necesaria ninguna conmutación automática por error, no se recomienda. La historia del cliente de escucha también es más compleja sin Pacemaker.
El tipo de clúster se almacena en la vista de administración dinámica (DMV) de SQL Serversys.availability_groups, en las columnas cluster_type y cluster_type_desc.
required_synchronized_secondaries_to_commit
Una novedad en SQL Server 2017 (14.x) es un valor que usan los AG denominado required_synchronized_secondaries_to_commit. Esto indica al AG el número de réplicas secundarias que deben estar en sincronía con la principal. Esto permite cosas como la conmutación automática por error (solo cuando se integra con Pacemaker con un tipo de clúster External) y controla el comportamiento de aspectos como la disponibilidad de la principal si el número adecuado de réplicas secundarias está en línea o sin conexión. Para comprender mejor el funcionamiento, vea Alta disponibilidad y protección de datos para las configuraciones de grupo de disponibilidad. El valor required_synchronized_secondaries_to_commit se establece de forma predeterminada y se mantiene en Pacemaker/ SQL Server. Puede invalidar este valor manualmente.
La combinación de required_synchronized_secondaries_to_commit y el nuevo número de secuencia (que se almacena en sys.availability_groups) informa a Pacemaker y SQL Server que, por ejemplo, puede producirse la conmutación automática por error. En ese caso, una réplica secundaria tendría el mismo número de secuencia que la principal, lo que significa que está actualizada con toda la información de configuración más reciente.
Hay tres valores que se pueden establecer para required_synchronized_secondaries_to_commit: 0, 1 o 2. Controlan el comportamiento de lo que sucede cuando una réplica deja de estar disponible. Los números corresponden al número de réplicas secundarias que se deben sincronizar con la principal. El comportamiento es el siguiente en Linux:
| Configuración | Descripción |
|---|---|
0 |
No es necesario que las réplicas secundarias estén en estado sincronizado con la principal. Sin embargo, si las réplicas secundarias no están sincronizadas, no hay ninguna conmutación automática por error. |
1 |
Una réplica secundaria debe estar en un estado sincronizado con la principal; la conmutación automática por error es posible. La base de datos principal no está disponible hasta que haya una réplica sincrónica secundaria disponible. |
2 |
Ambas réplicas secundarias en una configuración de AG de tres o más nodos deben estar sincronizadas con la principal; la conmutación automática por error es posible. |
required_synchronized_secondaries_to_commit controla no solo el comportamiento de las conmutaciones por error con réplicas sincrónicas, sino la pérdida de datos. Con un valor de 1 o 2, una réplica secundaria debe estar siempre sincronizada, para garantizar la redundancia de los datos. Esto significa que no se produce ninguna pérdida de datos.
Para cambiar el valor de required_synchronized_secondaries_to_commit, use la sintaxis siguiente:
Nota
Al cambiar el valor, se reinicia el recurso, lo que significa una breve interrupción. La única manera de evitar esto es establecer el recurso para que el clúster no lo administre temporalmente.
Red Hat Enterprise Linux (RHEL) y Ubuntu
sudo pcs resource update <AGResourceName> required_synchronized_secondaries_to_commit=<value>
SUSE Linux Enterprise Server (SLES)
sudo crm resource param ms-<AGResourceName> set required_synchronized_secondaries_to_commit <value>
En este ejemplo, <AGResourceName> es el nombre del recurso configurado para el grupo de disponibilidad y <value> es 0, 1 o 2. Para volver a establecerlo en el valor predeterminado de Pacemaker que administra el parámetro, ejecute la misma instrucción sin ningún valor.
La conmutación automática por error de un AG es posible cuando se cumplen las condiciones siguientes:
- Las réplicas principal y secundaria se establecen en movimiento de datos sincrónicos.
- La secundaria tiene un estado (no sincronizando), lo que significa que las dos están en el mismo punto de datos.
- El tipo de clúster se establece en External. No es posible la conmutación automática por error con un tipo de clúster de None.
- La
sequence_numberde la réplica secundaria que se va a convertir en la principal tiene el número de secuencia más alto; en otras palabras, lasequence_numberde la réplica secundaria coincide con la de la réplica principal original.
Si se cumplen estas condiciones y se produce un error en el servidor que hospeda la réplica principal, el AG cambia la propiedad a una réplica sincrónica. El comportamiento para réplicas sincrónicas (de las cuales puede haber tres en total: una principal y dos réplicas secundarias) puede controlarse más mediante required_synchronized_secondaries_to_commit. Esto funciona con AG en Windows y Linux, pero se configura de forma diferente. En Linux, el valor se configura automáticamente mediante el clúster en el propio recurso de AG.
Cuórum y réplica de solo configuración
Otra novedad en SQL Server 2017 (14.x) a partir de la CU 1 es una réplica de solo configuración. Dado que Pacemaker es diferente de un WSFC, especialmente cuando se trata de un cuórum y requiere la creación de barreras en un nodo con errores, tener solo una configuración de dos nodos no funciona cuando se trata de un AG. En el caso de una FCI, los mecanismos de cuórum proporcionados por Pacemaker pueden ser correctos, ya que todo el arbitraje de la conmutación por error de FCI se produce en el nivel de clúster. En el caso de un AG, el arbitraje en Linux se produce en SQL Server, donde se almacenan todos los metadatos. Aquí es donde entra en juego la réplica de solo configuración.
Sin nada más, sería necesario un tercer nodo y al menos una réplica sincronizada. La réplica de solo configuración almacena la configuración de AG en la base de datos master, igual que las demás réplicas en la configuración de AG. La réplica de solo configuración no tiene las bases de datos de usuario que participan en el AG. Los datos de configuración se envían sincrónicamente desde el servidor principal. Estos datos de configuración se usan después durante las conmutaciones por error, ya sean automáticas o manuales.
Para que un AG mantenga el cuórum y habilite las conmutaciones automáticas por error con un tipo de clúster External, debe:
- Tener tres réplicas sincrónicas (solo SQL Server Enterprise); o
- Tener dos réplicas (principal y secundaria) y una réplica de solo configuración.
Pueden producirse conmutaciones por error manuales si se usan tipos de clúster External o None para las configuraciones de AG. Aunque una réplica de solo configuración se puede configurar con un AG que tiene un tipo de clúster de None, no resulta recomendable, ya que complica la implementación. Para esas configuraciones, modifique required_synchronized_secondaries_to_commit manualmente para que tenga un valor de al menos 1, de modo que haya al menos una réplica sincronizada.
Una réplica de solo configuración se puede hospedar en cualquier edición de SQL Server, incluido SQL Server Express. Esto minimiza los costes de licencia y garantizará que funcione con AG en SQL Server Standard. Esto significa que el tercer servidor necesario solo debe cumplir la especificación mínima de SQL Server, ya que no recibe el tráfico de transacciones de usuario para el AG.
Cuando se usa una réplica de solo configuración, tiene el siguiente comportamiento:
De forma predeterminada,
required_synchronized_secondaries_to_commitse estable en 0. Se puede modificar manualmente a 1 si se desea.Si se produce un error en la principal y
required_synchronized_secondaries_to_commites 0, la réplica secundaria se convierte en la nueva principal y está disponible tanto para lectura como para escritura. Si el valor es 1, se produce una conmutación automática por error, pero no se aceptan nuevas transacciones hasta que la otra réplica esté en línea.Si se produce un error en una réplica secundaria y
required_synchronized_secondaries_to_commites 0, la réplica principal sigue aceptando transacciones, pero si se produce un error en la principal en este momento, no hay protección para los datos y la conmutación por error (manual o automática) no es posible, ya que no hay disponible una réplica secundaria.Si se produce un error en la réplica de solo configuración, el AG funciona con normalidad, pero no es posible la conmutación automática por error.
Si se produce un error en una réplica secundaria sincrónica y en la réplica de solo configuración, la principal no puede aceptar transacciones y no tendrá donde producir un error.
En la CU 1 hay un error conocido en el registro del archivo corosync.log que se genera mediante mssql-server-ha. Si una réplica secundaria no puede convertirse en la principal debido al número de réplicas necesarias disponibles, el mensaje actual indica: Expected to receive 1 sequence numbers but only received 2. Not enough replicas are online to safely promote the local replica. Los números se deben invertir y debe indicar Expected to receive 2 sequence numbers but only received 1. Not enough replicas are online to safely promote the local replica.
Varios grupos de disponibilidad
Se puede crear más de un AG por clúster de Pacemaker o conjunto de servidores. La única limitación son los recursos del sistema. El principal muestra la propiedad de AG. Distintos nodos pueden ser propietarios de diferentes AG; no es necesario que todos se ejecuten en el mismo nodo.
Ubicación de unidad y carpeta para las bases de datos
Como con los AG basados en Windows, la unidad y la estructura de carpetas de las bases de datos de usuario que participan en un AG deben ser idénticas. Por ejemplo, si las bases de datos de usuario se encuentran en /var/opt/mssql/userdata en el servidor A, esa misma carpeta debe existir en el servidor B. La única excepción a esto se indica en la sección Interoperabilidad con las réplicas y los grupos de disponibilidad basados en Windows.
El cliente de escucha en Linux
El agente de escucha es una funcionalidad opcional para un AG. Proporciona un único punto de entrada para todas las conexiones (de lectura/escritura a la réplica principal y/o de solo lectura a las réplicas secundarias) para que las aplicaciones y los usuarios finales no tengan que saber qué servidor hospeda los datos. En un WSFC, esta es la combinación de un recurso de nombre de red y un recurso IP, que se registra en AD DS (si es necesario) y en DNS. En combinación con el propio recurso de AG, proporciona esa abstracción. Para obtener más información sobre un agente de escucha, consulte Conexión a un agente de escucha de grupo de disponibilidad Always On.
El cliente de escucha en Linux se configura de forma diferente, pero su funcionalidad es la misma. No hay ningún concepto de recurso de nombre de red en Pacemaker, ni tampoco se crea un objeto en AD DS; solo se crea un recurso de dirección IP en Pacemaker que se puede ejecutar en cualquiera de los nodos. Es necesario crear una entrada asociada al recurso IP para el cliente de escucha en DNS con un "nombre descriptivo". El recurso IP para el cliente de escucha solo está activo en el servidor que hospeda la réplica principal para ese grupo de disponibilidad.
Si se usa Pacemaker y se crea un recurso de dirección IP que está asociado al cliente de escucha, hay una breve interrupción a medida que la dirección IP se detenga en el servidor y se inicie en el otro, ya sea automática o manual. Aunque esto proporciona una abstracción a través de la combinación de un nombre único y una dirección IP, no enmascara la interrupción. Una aplicación debe ser capaz de controlar la desconexión al tener algún tipo de funcionalidad para detectarlo y volver a conectarse.
Sin embargo, la combinación del nombre DNS y la dirección IP sigue siendo insuficiente para proporcionar toda la funcionalidad que proporciona un cliente de escucha en un WSFC, como el enrutamiento de solo lectura para las réplicas secundarias. Cuando configura un AG, todavía es necesario configurar un agente de escucha en SQL Server. Esto puede verse en el asistente y en la sintaxis de Transact-SQL. Se puede configurar de dos maneras para que funcione igual que en Windows:
- En el caso de un AG con un tipo de clúster External, la dirección IP asociada al agente de escucha que se crea en SQL Server debe ser la dirección IP del recurso creado en Pacemaker.
- Para un AG creado con un tipo de clúster de None, use la dirección IP asociada a la réplica principal.
La instancia asociada con la dirección IP proporcionada se convierte entonces en el coordinador de cosas como las solicitudes de enrutamiento de solo lectura de las aplicaciones.
Interoperabilidad con réplicas y grupos de disponibilidad basados en Windows
Un AG que tiene un tipo de clúster External o uno que es WSFC no puede tener sus réplicas entre plataformas. Esto es cierto si el AG es SQL Server Standard o SQL Server Enterprise. Esto significa que, en una configuración de AG tradicional con un clúster subyacente, una réplica no puede estar en un WSFC y la otra en Linux con Pacemaker.
Un AG con un tipo de clúster de NONE puede tener sus réplicas entre límites del sistema operativo, por lo que podría haber réplicas basadas en Linux y Windows en el mismo AG. Aquí se muestra un ejemplo en el que la réplica principal se basa en Windows, mientras que la secundaria se encuentra en una de las distribuciones de Linux.
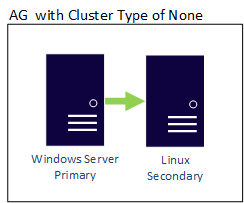
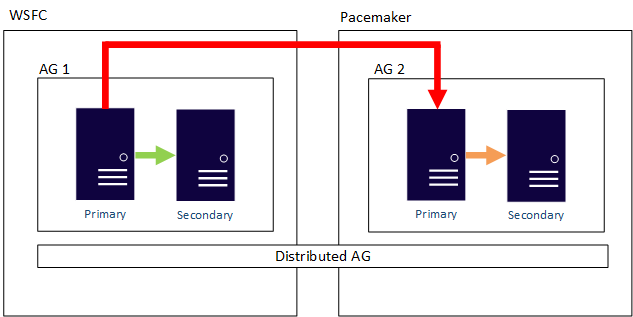
Un AG distribuido también puede cruzar los límites del sistema operativo. Los AG subyacentes están limitados por las reglas de cómo están configuradas, como una configurada con la configuración externa solo para Linux, pero el AG al que está unida podría configurarse con un WSFC. Considere el ejemplo siguiente:
Contenido relacionado
- Configuración de un grupo de disponibilidad AlwaysOn de SQL Server para alta disponibilidad en Linux
- Configuración de un grupo de disponibilidad de SQL Server para escalado de lectura en Linux
- Agregar un recurso de clúster de grupo de disponibilidad en Linux
- Configurar el grupo de disponibilidad de SQL Server Always On en Windows y Linux (multiplataforma)