Personalización de los modelos de clasificación para mejorar la relevancia en SharePoint
SE APLICA A: 2013 2019
2013 2019  SharePoint Online en Microsoft 365
SharePoint Online en Microsoft 365
Mejorar la relevancia de la búsqueda con la personalización de modelos de clasificación para calcular las puntuaciones de clasificación (por relevancia) con precisión mediante las características de clasificación en SharePoint.
Puede ordenar los resultados de búsqueda en SharePoint de cuatro maneras, una de las cuales es por puntuación de clasificación. Al ordenar los resultados de búsqueda por puntuación de clasificación, SharePoint coloca los resultados más relevantes en la parte superior del conjunto de resultados de búsqueda.
Un resultado de búsqueda es relevante si recibe una puntuación de clasificación alta, que es una puntuación numérica específica calculada el motor de búsqueda con un modelo de clasificación. Un modelo de clasificación es una lista de una o varias fases de clasificación que contienen un conjunto de características de clasificación. El modelo de clasificación define cómo calcula el motor de búsqueda la clasificación por relevancia usando diversos factores, que se representan en el modelo de clasificación como características de rango. Factores que se utiliza para calcular la clasificación de relevancia incluyen, pero no se limitan a, los siguientes:
- La apariencia de los términos de consulta en el índice de texto completo, que incluye información como el título y el cuerpo de un documento.
- Los metadatos asociados a un elemento concreto, como el tipo de archivo o la longitud de la dirección URL de un documento.
- El texto del delimitador asociado con los vínculos de dirección URL que señale a un elemento determinado.
- La información sobre los clics que hace el usuario para cada elemento.
- La proximidad de los términos de consulta en el cuerpo o el título de un documento.
Inicie la personalización de los modelos de clasificación basados en una plantilla de modelo de clasificación de SharePoint
Para facilitar la personalización, comience con uno de los modelos de clasificación predeterminados de SharePoint como una plantilla. A continuación, modifique dicho modelo de clasificación según el conjunto de datos.
De forma predeterminada, SharePoint proporciona catorce modelos de clasificación. Consulte ¿Qué es un modelo de clasificación? (en TechNet) para obtener información detallada sobre estos modelos de clasificación y su propósito.
Importante
Si instala la actualización acumulativa de SharePoint de agosto de 2013, se recomienda usar el Modelo de clasificación de búsqueda con dos fases lineales como el modelo base para su modelo de clasificación personalizado. El Modelo de clasificación de búsqueda con dos fases lineales es una copia del Modelo de búsqueda predeterminado con una segunda fase que es lineal en lugar de una red neuronal.
Puede usar los siguientes cmdlets de Windows PowerShell para personalizar modelos de clasificación:
- Get-SPEnterpriseSearchRankingModel
- New-SPEnterpriseSearchRankingModel
- Remove-SPEnterpriseSearchRankingModel
- Set-SPEnterpriseSearchRankingModel
Para enumerar todos los modelos de clasificación disponibles
- Inicie el Shell de administración de SharePoint como Administrador.
- Ejecute la siguiente secuencia de cmdlets de Windows PowerShell.
$ssa = Get-SPEnterpriseSearchServiceApplication -Identity "Search Service Application"
$owner = Get-SPenterpriseSearchOwner -Level ssa
Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner
Para recuperar un modelo de clasificación predeterminado y usarlo como una plantilla
- Inicie el Shell de administración de SharePoint como Administrador.
- Ejecute la siguiente secuencia de cmdlets de Windows PowerShell; filename.xml es el nombre de un archivo en el que desea guardar el modelo de clasificación.
$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$defaultRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner | Where-Object { $_.IsDefault -eq $True }
$defaultRankingModel.RankingModelXML > filename.xml
Si instala la actualización acumulativa de SharePoint de agosto de 2013, puede usar el siguiente procedimiento para recuperar el modelo de clasificación de búsqueda con dos fases lineales y usarlo como plantilla para el modelo de clasificación personalizado.
Para recuperar el modelo de clasificación de búsqueda con dos fases lineales y usarlo como plantilla.
- Inicie el Shell de administración de SharePoint como Administrador.
- Ejecute la siguiente secuencia de cmdlets de Windows PowerShell; filename.xml es el nombre de un archivo en el que desea guardar el modelo de clasificación.
$ssa = Get-SPEnterpriseSearchServiceApplication
$owner = Get-SPenterpriseSearchOwner -Level ssa
$twoLinearStagesRankingModel = Get-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -Identity 5E9EE87D-4A68-420A-9D58-8913BEEAA6F2
$twoLinearStagesRankingModel.RankingModelXML > filename.xml
Para implementar un modelo de clasificación personalizado
En la lista de modelos de clasificación disponibles, copie el GUID del modelo de clasificación que se va a usar como plantilla. (Consulte Para enumerar todos los modelos de clasificación disponibles para ver la secuencia de cmdlets de Windows PowerShell que se van a usar).
Ejecute la siguiente secuencia de cmdlets de Windows PowerShell mediante el GUID copiado en el paso 1 para <GUID>.
$ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $rm = Get-SPEnterpriseSearchRankingModel -Identity <GUID> -SearchApplication $ssa -Owner $owner $rm.RankingModelXML > myrm.xmlEdite el
myrm.xmlarchivo en un editor XML. Debe usar los nuevos valores GUID para los atributos de id de RankModel2Stage elemento y todos los elementos de RankingModel2NN. Para obtener un nuevo valor GUID puede usar el siguiente comando de Windows PowerShell por ejemplo:[guid]::NewGuid()Cree un nuevo modelo de clasificación con el cmdlet New-SPEnterpriseSearchRankingModel mediante la ejecución de los siguientes comandos.
$myRankingModel = Get-Content .\\myrm.xml $myRankingModel = [String]$myRankingModel $ssa = Get-SPEnterpriseSearchServiceApplication $owner = Get-SPenterpriseSearchOwner -Level ssa $newrm = New-SPEnterpriseSearchRankingModel -SearchApplication $ssa -Owner $owner -RankingModelXML $myRankingModel
Detalle de clasificación
Importante
[!IMPORTANTE] Se proporcionan los detalles del clasificación y la página de ExplainRank que lo acompaña para su comodidad y sólo para ayudarle en la optimización y depuración de sus propios modelos de clasificación personalizado. El contenido del detalle de la clasificación y la página ExplainRank adjunta no son compatibles y pueden cambiar sin previo aviso en futuras actualizaciones y revisiones de software.
El detalle de clasificación es un documento XML que proporciona información detallada acerca de la clasificación puntuación cálculo para un solo elemento que coincide con una consulta de usuario determinado. El detalle de clasificación se almacena en una propiedad administrada especial, denominada rankdetail.
Cada característica de clasificación de un modelo de clasificación tiene un nodo XML independiente en el detalle de clasificación que describe los detalles de la clasificación de puntuación de cálculo. El detalle de clasificación se proporciona sólo para las consultas que tienen resultados de búsqueda que no superen los 100 elementos.
Conceptualmente, el formato general del detalle de la clasificación es similar al ejemplo siguiente.
<rank_log version='15.0.0000.1000' id='[internal guid of ranking model used for calculation]' >
<query tree='[representation of user query used for ranking]'/>
<stage type='linear'>
[Details of rank calculation of the first ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the first stage of the ranking model]
</stage_model>
</stage>
<stage type='neural_net' >
[Details of rank calculation of the second ranking stage. One XML node for each rank feature.]
<stage_model>
[Definition of the second stage of the ranking model]
</stage_model>
</stage>
</rank_log>
Para recuperar el detalle de clasificación, debe ser el Administrador de la aplicación de servicio de búsqueda (SSA).
Para recuperar el detalle de la clasificación
- Inicie el Shell de administración de SharePoint como Administrador.
- Ejecute la siguiente secuencia de cmdlets de Windows PowerShell y sustituya <query_text> y <url> por valores reales.
$app = Get-SPEnterpriseSearchServiceApplication
$searchAppProxy = Get-spenterprisesearchserviceapplicationproxy | Where-Object { ($_.ServiceEndpointUri.PathAndQuery -like $app.Uri.PathAndQuery)}
$request = New-Object Microsoft.Office.Server.Search.Query.KeywordQuery($searchAppProxy)
$request.ResultTypes = [Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults
$request.QueryText = "<query_text> AND path:""<url>"""
$request.SelectProperties.Add("rankdetail")
$searchexecutor = new-Object Microsoft.Office.Server.Search.Query.SearchExecutor
$resultTables = $searchexecutor.ExecuteQuery($request)
$resultTables[([Microsoft.Office.Server.Search.Query.ResultType]::RelevantResults)].Table
Comprender el cálculo de la puntuación de clasificación a través de la página ExplainRank
SharePoint proporciona la página ExplainRank, que se encuentra en la carpeta de diseños (<searchCenter>/_layouts/15/). Esta página contiene información detallada sobre la puntuación de clasificación de cada característica de clasificación basándose en una consulta de búsqueda especificada, el ID de un documento y el ID de un modelo de clasificación opcional. La información se obtienen y se analiza desde el detalle de la clasificación.
Puede acceder a la página ExplainRank con la siguiente dirección URL: http://< searchCenter>/_layouts/15/ExplainRank.aspx?q={x}&d={y}&rm={z}
Donde:
- x es la consulta de búsqueda.
- y es el ID del documento.
- z es el ID opcional del modelo de clasificación. del modelo de clasificación Si no se proporciona el identificador de modelo de clasificación, se usa el modelo de clasificación predeterminado.
Al igual que con el detalle de clasificación, para ver la página ExplainRank, debe ser el Administrador de la aplicación de servicio de búsqueda (SSA).
Ajustar el modelo de clasificación con las características de clasificación
Las características de clasificación funcionan como un dial de ajuste de un modelo de clasificación. Las siguientes secciones describen las características de clasificación que están disponibles en el modelo de clasificación predeterminado de SharePoint y cómo contribuyen al cálculo de clasificación de relevancia.
BM25
La característica de clasificación de BM25 clasifica los artículos según la apariencia de los términos de consulta en el índice de texto completo. La entrada BM25 puede ser cualquiera de las propiedades administradas en el índice de texto completo.
Nota:
La característica de clasificación de BM25 utilizada en este contexto es la versión clasificada por campos: BM25F.
La característica de clasificación de BM25 calcula la puntuación de clasificación de relevancia con la fórmula siguiente.
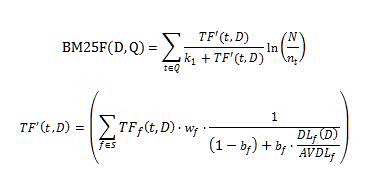
Donde:
- D es un documento, representado como una lista de campos de texto, como el título o el cuerpo.
- Q es la consulta de usuario, representada como una lista de términos de consulta, t.
- S define la lista de campos que contribuyen a la clasificación de relevancia, esta lista se define mediante el modelo de clasificación.
- _w_f es un valor numérico que define el peso del campo relativo f ??? S; este valor se define mediante el modelo de clasificación.
- _b_f es un valor numérico que define la normalización de longitud del documento para cada campo f ??? S.
- _TF_f (t,D) es el número de apariciones del término de consulta t en el campo f del documento D.
- _DL_f (D) es el número total de palabras en el campo f del documento D.
- N es la cantidad total de documentos en el índice.
- _n_t es una cantidad de documentos que contienen el término t en al menos una de sus propiedades.
- _AVDL_f es la media _DL_f (D) en todos los documentos indexados.
- _k_1 es un parámetro escalar; este valor se define mediante el modelo de clasificación.
Debe asignar las propiedades administradas que se usan para la característica de clasificación de BM25 para el índice de texto completo predeterminado en la interfaz de usuario Elegir configuración avanzada que permita búsquedas.
Dentro de una consulta de usuario, se excluyen los términos de consulta que forman parte de los siguientes operadores de cálculos de clasificación de relevancia: NOT(???) en FQL, NOT(???) en KQL y FILTER(???) en FQL.
Además, los términos de consulta que están en el ámbito, por ejemplo, title:apple AND body:orange, se excluyen de los cálculos de clasificación de relevancia.
Ejemplo de definición de característica de clasificación de BM25
<BM25Main name="ContentRank" k1="1">
<Layer1Weights>
<Weight>0.26236235707678</Weight>
</Layer1Weights>
<Properties>
<Property name="body" w="0.019391078235467" b="0.44402228898786156" propertyName="body" />
<Property name="Title" w="0.36096989709360422" b="0.38179554361297785" propertyName="Title" />
<Property name="Author" w="0.15808522836934547" b="0.13896219383271818" propertyName="Author" />
<Property name="Filename" w="0.15115036355698144" b="0.96245017871125826" propertyName="Filename" />
<Property name="QLogClickedText" w="0.3092664171701901" b="0.056446823262849853" propertyName="QLogClickedText" />
<Property name="AnchorText" w="0.021768362296187508" b="0.74173561196103566" propertyName="AnchorText" />
<Property name="SocialTag" w="0.10217215754116529" b="0.55968554315932328" propertyName="SocialTag" />
</Properties>
</BM25Main>
Ejemplo de detalle de la clasificación para la característica de clasificación de BM25
<bm25 name='ContentRank'>
<schema pid_mapping='[1:content::7:%default] [2:content::1:%default] [3:content::5:%default] [56:content::2:%default] [100:content::3:link] [10:content::6:link] [264:content::14:link] ' pids_not_mapped=''/>
<query_term term='WORDS(content:integration, content:integrations, content:integrations)'>
<index name='content' N='10035' n='8'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.500486' weight='1'
tf='0 1 1 0 0 0 0 11 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group id='link'/>
</index>
<rank score='2.37967' score_acc='2.37967' term_weight='7.13439'/>
</query_term>
<query_term term='WORDS(content:effort, content:efforts, content:efforts)'>
<index name='content' N='10035' n='9'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'/>
<group id='link'/>
</index>
<rank score='0' score_acc='2.37967' term_weight='7.01661'/>
</query_term>
<query_term term='PHRASE(content:fastserver, content:plugin)'>
<index name='content' N='10035' n='3'
avdl='1 2.98018 2.00427 1 1 2.39394 1 637.308 1 1 1 1 1 1 1 1 '>
<group id='%default'
ext_doc_id='55' int_doc_id='16' precalc='0' tf_prime='0.0399696' weight='1'
tf='0 0 0 0 0 0 0 3 0 0 0 0 0 0 0 0 '
dl='0 4 9 0 0 2 0 1291 0 0 0 0 0 0 0 0 '/>
<group id='link'/>
</index>
<rank score='0.311896' score_acc='2.69157' term_weight='8.11522'/>
</query_term>
<final score='2.69157' transformed='2.69157' normalized='2.69157' hidden_nodes_adds='0.706166 '/>
</bm25>
Grupos de peso
En un modelo de clasificación personalizado, puede tener dos o más propiedades administradas que se asignan al mismo grupo de peso en el esquema de búsqueda. En estos casos, el contenido de estas propiedades administradas se combina en el índice de texto completo y no pueden clasificarse por separado en el cálculo de BM25. Este efecto es el mismo que establecer valores iguales para los parámetros _w_f y _b_f dentro de cada grupo de propiedades administradas, asignados al mismo grupo de peso en el esquema de búsqueda. Para evitarlo, asigne las propiedades administradas a uno de los grupos de peso diferentes 16 disponibles en el esquema de búsqueda.
Los grupos de peso son también conocido como contexto. Consulte Influir en la clasificación de los resultados de búsqueda mediante el esquema de búsqueda (en TechNet) para obtener más información sobre la relación entre una propiedad administrada y su contexto.
Estática
La característica de clasificación estática clasifica los artículos según las propiedades administradas numéricas que se almacenan en el índice de búsqueda. Las propiedades administradas numéricas usadas para el cálculo de clasificación de relevancia en las características de clasificación estáticas deben ser de tipo Integer y establecerse en Refinable o Sortable en el esquema de búsqueda. No puede usar varios valores de las propiedades administradas en combinación con la característica de clasificación estática.
Antes de que se pueden agregar la característica de clasificación estática con otras características de clasificación, cada característica de clasificación estática se preprocesa a través de una sola transformación. La tabla 1 se enumeran todas las funciones de transformación admitidas.
Tabla 1. Funciones de transformación admitidas para las características estáticas y de clasificación por proximidad

Ejemplo de definición de característica de clasificación estática
<Static name="clickdistance" default="5" propertyName="clickdistance">
<Transform type="InvRational" k="0.27618729159042193" />
<Layer1Weights>
<Weight>0.616326852981262</Weight>
</Layer1Weights>
</Static>
Ejemplo de detalle de la clasificación para una característica de clasificación estática
<static_feature name='clickdistance' property_name='clickdistance'
used_default='1' raw_value='5' raw_value_transformed='5'
transformed='0.420003' normalized='0.420003'
hidden_nodes_adds='0.258859 '/>
Estática periodificada
La característica de clasificación estática periodificado por clasifica los documentos según su tipo de archivo y el idioma. La definición de una característica de clasificación estática periodificado por dentro de un modelo de clasificación depende de si la característica de clasificación forma parte de un modelo lineal o una red neuronal. En los ejemplos siguientes se aplican sólo a los modelos lineales. En el caso de las redes neuronales, el número de <Add> atributos de cada cubo debe coincidir con el número de nodos ocultos de la red neuronal.
Las propiedades administradas usadas para el cálculo de clasificación por relevancia en las características de clasificación estáticas con cubo deben ser de tipo Integer y establecerse en Refinable o Sortable en el esquema de búsqueda. No puede usar varios valores de las propiedades administradas en combinación con la característica de clasificación estática periodificado por.
Ejemplo de definición de la característica de clasificación estática en contenedores para el tipo de archivo
Cada documento tiene un tipo de archivo asociado que el componente de procesamiento de contenido se detecta y se almacena en el índice de búsqueda como un valor entero basado en cero. Cuando se usa la característica de clasificación estática periodificado por a documentos de clasificación en función de sus tipos de archivo, cada tipo de documento está asociado con una puntuación de clasificación de relevancia específico. Por ejemplo, en la siguiente definición, el cubo 2 corresponde a un documento .ppt; el nodo <Add>0.680984743282165</Add> define los puntos de clasificación adicionales que se agregan a los resultados de clasificación de relevancia de todos los documentos .ppt.
<BucketedStatic name="InternalFileType" default="0" propertyName="InternalFileType">
<Bucket name="Html" value="0">
<HiddenNodesAdds>
<Add>0.464062832328107</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Doc" value="1">
<HiddenNodesAdds>
<Add>0.551558196047853</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Ppt" value="2">
<HiddenNodesAdds>
<Add>0.680984743282165</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xls" value="3">
<HiddenNodesAdds>
<Add>-0.143152682829863</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Xml" value="4">
<HiddenNodesAdds>
<Add>-1.29219869408375</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Txt" value="5">
<HiddenNodesAdds>
<Add>-0.456669562992298</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ListItems" value="6">
<HiddenNodesAdds>
<Add>0.170944938307345</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Message" value="7">
<HiddenNodesAdds>
<Add>-0.0666769377412764</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="Image" value="8">
<HiddenNodesAdds>
<Add>0.106988843357609</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
Ejemplo de definición de la característica de clasificación estática en contenedores para el idioma del documento
El componente de procesamiento de contenido detecta automáticamente el idioma para cada documento antes de que se agregue al índice de búsqueda. Cuando se usa la característica de clasificación estática periodificado por para clasificación documentos basados en su idioma, puede definir cómo calcular la puntuación de clasificación en función de si el idioma del documento que se ha detectado automáticamente coincide con el idioma de la consulta.
En el momento de la consulta, la información sobre el idioma del usuario se escribe en el motor de búsqueda como una propiedad de la consulta.
Proximidad
La característica de clasificación de proximidad clasifica los artículos según la distancia entre los términos de la consulta en el índice de texto completo. La puntuación de clasificación aumenta cuando dos términos de la consulta aparecen en las mismas propiedades administradas en el índice de texto completo. Los cálculos de proximidad son costosos en términos de la actividad del disco y el uso de la CPU. Como resultado, el aumento de la proximidad se lleva a cabo solo durante la segunda fase del modelo de clasificación predeterminado de SharePoint (siempre que esté disponible).
Hay varias opciones para evaluar la característica de clasificación de proximidad, todas controladas por los atributos que se describen en la tabla 2.
Tabla 2. Los atributos de control de evaluación de las características de clasificación de proximidad
| Atributos | Descripción |
|---|---|
isExact=0 |
En este modelo, el algoritmo de proximidad intenta buscar el intervalo mínimo (distancia) del subconjunto de términos de consulta en un documento. El algoritmo de proximidad considera fragmentos que contienen los términos de la consulta en los mismos pedidos tal como aparecen en la consulta de usuario. Si no existe ningún fragmento para todos los términos de consulta, el algoritmo de proximidad considera fragmentos que contienen todos excepto uno de los términos de consulta. Este proceso se itera con el número de términos de consulta reducido cada vez, hasta que la longitud del fragmento supera maxMinSpan. maxMinSpan es un atributo dentro de la característica de clasificación de proximidad que especifica el umbral de una definición de la longitud máxima de un fragmento. Un fragmento ideal es aquel que contiene todos los términos de consulta, pero es menor que maxMinSpan. |
isExact=1 |
En este modelo, el algoritmo de proximidad intenta encontrar un fragmento de código consecutivo del documento que contiene todos los términos de la consulta (o frase de la consulta). |
isDiscounted |
Este atributo es aplicable a isExact=1 y isExact=0. Cuando isDiscounted está habilitado, el valor de proximidad se multiplica por esta fracción: (número de repeticiones del mejor fragmento o aciertos exactos) dividido por (número de repeticiones del término de consulta más raro en este contexto). |
proximity="complete" |
En este modelo, la característica de clasificación de proximidad solo mejora la posición de los documentos donde todo el texto de consulta de usuario se produce dentro de una propiedad administrada específica. |
proximity="perfect" |
Este modo es similar al complete modo, pero se aplica a campos cortos, como título. La característica de clasificación de proximidad sólo aumenta los documentos que el texto de consulta completo del usuario coincide con un exacta title dentro de una propiedad administrada específica. Si el title contiene términos adicionales fuera de la consulta de usuario, el elemento no se considera el algoritmo de proximidad. |
default |
Este atributo se aplica sólo a las consultas de un solo término. Para los elementos que contienen el término de consulta, el default valor se usa como resultado de la puntuación de clasificación por la característica de clasificación de proximidad. La perfect proximidad es una excepción a esta regla. Para perfect proximidad, nunca se usa el valor predeterminado. En su lugar, se procesan las consultas de un solo término en la misma manera que otras consultas. |
Ejemplo de definición de característica de clasificación de proximidad
El ejemplo siguiente es un fragmento del modelo de clasificación predeterminado de SharePoint. En este modelo, la característica de proximidad solo forma parte del cálculo de la segunda fase, que implica una red neuronal. Por lo tanto, el ejemplo contiene varios elementos de peso, <LayerWeights>, que corresponden al número de neuronas en la capa oculta de la red neuronal.
<MinSpan name="Title_MinSpanExactDiscounted" default="0.43654446989518952" maxMinSpan="1" isExact="1" isDiscounted="1" propertyName="Title">
<Normalize SDev="0.20833333333333334" Mean="0.375" />
<Transform type="Linear" a="1" b="0" maxx="10000" />
<Layer1Weights>
<Weight>0.0399835450090479</Weight>
<Weight>-0.00693681478614802</Weight>
<Weight>0.0286196612755843</Weight>
<Weight>0.11775902923563</Weight>
<Weight>0.0885860088190342</Weight>
<Weight>0.102859503886488</Weight>
</Layer1Weights>
</MinSpan>
Debe asignar las propiedades administradas usadas en las características de clasificación de proximidad al índice de texto completo predeterminado en el esquema de búsqueda.
Ejemplo de detalle de la clasificación para la característica de clasificación de proximidad
<proximity_feature name='Title_MinSpanExactDiscounted' pid='2'
proximity_type='exact_discounted'
used_default='0' raw_value='0' transformed='0'
normalized='-1.8'
hidden_nodes_adds='-0.0719704 0.0124863 -0.0515154 -0.211966 -0.159455 -0.185147 ' />
Dinámico
La característica de clasificación dinámica clasifica un elemento dependiendo de si la propiedad de la consulta coincide con una propiedad administrada determinada. Si hay una coincidencia, se multiplica puntuación de clasificación del elemento con un valor específico para distinguir ese elemento determinado. El atributo weight se usa para controlar cuánto esta característica afecta a la puntuación de clasificación general.
Nota:
La característica de clasificación dinámica no es personalizable; es solo para uso interno. Sin embargo, si instala la actualización acumulativa de SharePoint de agosto de 2013, la característica de clasificación de AnchortextComplete es una característica de clasificación dinámica personalizable que forma parte del modelo de clasificación predeterminado.
Ejemplo de definición de característica de clasificación dinámica
<Dynamic name="AnchortextComplete" pid="501" default="0" property="AnchortextCompleteQueryProperty">
<Transform type="Rational" k="0.91495552365614574" />
<Layer1Weights>
<Weight>0.715419978898093</Weight>
</Layer1Weights>
</Dynamic>
Actualización
El modelo de clasificación predeterminado de SharePoint no mejora la clasificación de los resultados de búsqueda en función de lo actuales que sean. Puede lograrlo agregando una nueva característica de clasificación estática que combine la información de la propiedad administrada LastModifiedTime con la propiedad de consulta DateTimeUtcNow, mediante la función de transformación de actualizaciones. La función de transformación de actualizaciones es la única transformación que puede usar para esta característica de clasificación de actualizaciones, puesto que convierte la edad del elemento en días desde una representación interna.
La transformación de actualizaciones se basa en la siguiente fórmula:
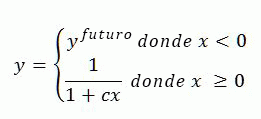
Donde:
- c y _y_futuras se definen en el modelo de clasificación.
- x es la antigüedad de un elemento en días.
- El valor de _y_future define la actualización de los elementos que tienen LastModifiedTime mayor que la fecha y hora actuales.
Ejemplo de definición de característica de clasificación de actualización
<Static name='freshboost' propertyName='LastModifiedTime' default='-1' convertPropertyToDatetime='1' rawValueTransform='compare' property='DateTimeUtcNow'>
<Transform type="Freshness" constant="0.0333" futureValue="2" />
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
Ejemplo de detalle de la clasificación para la característica de clasificación de actualización utilizando un documento anterior (de hace aproximadamente 580 días)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115930137649186' raw_value='9.80661e+018' raw_value_transformed='-5.03135e+014' transformed='0.0490396' normalized='0.0490396' hidden_nodes_adds='0.0490396 '/>
Detalles de clasificación de ejemplo para la característica de clasificación de actualización mediante un nuevo documento (<1 día de antigüedad)
<static_feature name='freshboost' property_name='LastModifiedTime' raw_value_transform='compare' used_default='0' property_value_found='1' property_value='9807115934928966979' raw_value='9.80712e+018' raw_value_transformed='-2.55529e+011' transformed='0.990248' normalized='0.990248'hidden_nodes_adds='0.990248 '/>
Agregación de las características de clasificación
Un modelo de clasificación consta de varias características de clasificación que se consideran juntas para calcular una puntuación de clasificación.
Modelos de clasificación de dos fases
Un modelo de clasificación puede tener dos etapas de clasificación. En la primera fase, el modelo de clasificación aplica a las características de clasificación es relativamente baratas para obtener una clasificación bruta de los resultados. En la segunda etapa, el modelo de clasificación aplica a las características de clasificación más caras y adicionales a los elementos con las puntuaciones de clasificación más altos.
El modelo de clasificación predeterminado de SharePoint es un ejemplo de modelo de segunda fase. En este modelo, la segunda fase funciona con los 1000 elementos resultantes de la primera fase que tienen la puntuación de clasificación más alta.
Una vez completado el proceso de clasificación en la primera fase, el motor de búsqueda ordena volver a todos los elementos, incluidos los elementos que se han excluido de la segunda etapa. Esto normalmente los resultados en los elementos de la segunda etapa tener un menor de clasificación puntuación en comparación con los elementos en la primera fase.
Sin embargo, para asegurarse de que el motor de búsqueda ordena volver a los elementos con precisión, los elementos de la segunda etapa deben tener una puntuación de clasificación mayor que los elementos de la primera fase. Para resolver este problema, se aumenta las clasificación puntuaciones de la segunda etapa. El motor de búsqueda realiza este cálculo automáticamente, basándose en una combinación de las características de clasificación.
Nota:
Si instala la actualización acumulativa de SharePoint de agosto de 2013, el modelo de clasificación predeterminado usa una primera fase lineal y una segunda fase con una red neuronal. El Modelo de clasificación de búsqueda con dos fases lineales es una copia del Modelo de búsqueda predeterminado con dos fases lineales. Se recomienda usar este modelo como base para el modelo de clasificación personalizado porque es más fácil ajustar un modelo lineal que uno con una red neuronal.
Modelo lineal
El modelo lineal define una combinación lineal de puntuaciones de clasificación de las características de clasificación.
La puntuación de clasificación proporcionada por modelos lineales se calcula con la fórmula siguiente:
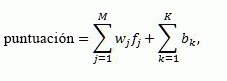
Donde:
- score es la puntuación de clasificación de resultados generada por el modelo lineal.
- M es el número de las características de clasificación, excluyendo las características de clasificación estáticas periodificadas.
- K es el número de características de clasificación estáticas periodificadas.
- _f_j es el valor de la característica _j_th después de la transformación.
- _w_j es el peso de contribución de la característica _j_th a la combinación lineal.
Red neuronal
La red neuronal define una combinación no lineal de puntuaciones de clasificación de las características de clasificación. Actualmente, SharePoint admite redes neuronales limitadas a una capa oculta con un máximo de ocho neuronas.
La puntuación de clasificación producida por una red neuronal se calcula con la siguiente fórmula:
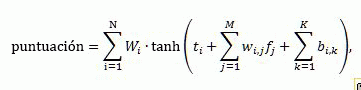
Donde:
- score es la puntuación de clasificación de resultados generada por la red neuronal.
- N es el número de neuronas de la capa oculta de la red neuronal.
- M es el número de las características de clasificación, excluyendo las características de clasificación estáticas periodificadas.
- K es el número de las características de clasificación estáticas periodificadas.
- _W_i es el peso de contribución de la neurona oculta _i_th.
- _t_i es el umbral de la neurona oculta _i_th.
- _W_i,j es el peso de contribución de la característica _j_th de la neurona oculta _i_th.
- _b_i,k es la adición de la característica estática periodificada _k_th de la neurona oculta _i_th.
El esquema general de clasificación cálculo puntuación con una red neuronal de capa de dos se representa en el siguiente diagrama. Este diagrama no tenga en cuenta la característica de clasificación estática periodificado por que contribuye a redes neuronal agregando valores personalizados directamente en los nodos ocultos, sin transformación ni normalización.
Figura 1. Esquema general del cálculo de la puntuación de clasificación con una red neuronal de dos capas
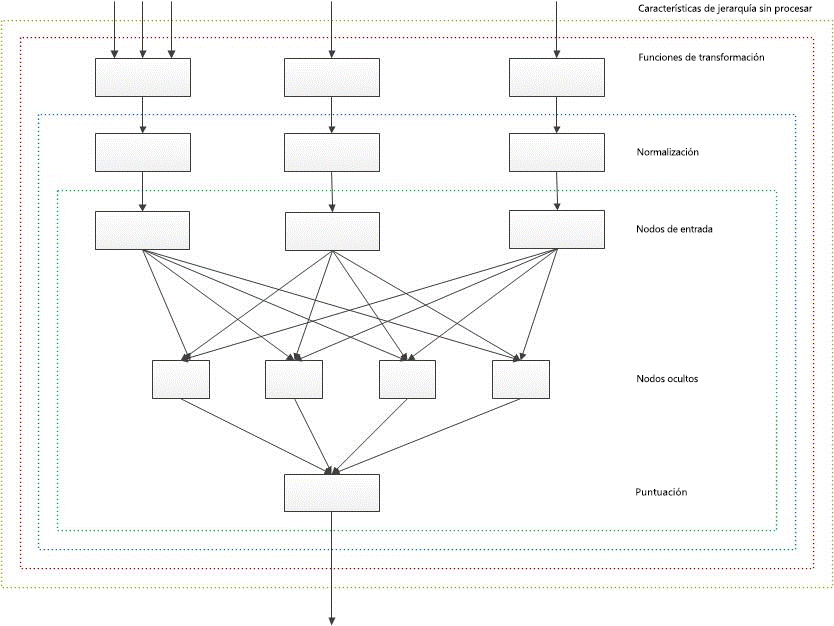
Cálculo previo de BM25 y características de clasificación estáticas
En un modelo de clasificación, BM25 y las características de clasificación estáticas pueden beneficiarse de precalculations para mejorar la latencia de consulta para los términos de consulta que con frecuencia se producen en los elementos. Esta mejora de la latencia de consulta se consigue con el costo de indización adicionales, tanto en términos de espacio en disco usado por el índice de búsqueda y el consumo de CPU.
Debe usar cálculo previo sólo en la primera fase de un modelo de clasificación. Por consiguiente, si se habilita el cálculo previo, el detalle de clasificación de la primera fase no estará completado.
Para habilitar el cálculo previo, establezca el atributo precalcEnabled en 1 en la definición de la fase de clasificación. Solo puede utilizar el cálculo previo una vez que ya esté en un modelo de clasificación.
Propiedades de la consulta
Propiedades de la consulta es un mecanismo de clasificación que rellena información adicional útil para clasificación puntuación cálculo. Por ejemplo, las propiedades de la consulta pueden ser la hora y fecha cuando se ejecutó la consulta, que se puede usar la característica de clasificación de la actualización. Tabla 3 se enumeran las propiedades de consulta disponibles para clasificación. No puede configurar propiedades de la consulta.
Tabla 3. Propiedades de la consulta de clasificación
| Propiedad de la consulta | Descripción |
|---|---|
| AnchortextCompleteQueryProperty |
Mejora la posición cuando aparecen textos de anclaje completos. |
| DateTimeUtcNow |
Fecha y hora actuales. Esta propiedad de consulta se puede utilizar la característica de clasificación de la actualización. |
| DetectedLanguageRanking |
Identificador del lenguaje de consulta. Esta propiedad de consulta se usa la característica de clasificación de DetectedLanguageRanking. |
| PersonalizationData |
Rangos de datos personalizados. |
| RecommendedforQueryProperty |
Recomendaciones de clasificaciones. |
Ejemplo 1: Modelo de clasificación básica con una fase lineal y una única característica de clasificación estática
Este modelo de clasificación se supone que el cliente ha creado una propiedad administrada denominada CustomRating. La característica de clasificación estática requiere CustomRating para ser del tipo de datos de Integer y configurarse como Sortable o Refinable en el esquema de búsqueda. Para cada documento en el conjunto de resultados, la puntuación de clasificación generada por este modelo de clasificación es igual al valor de CustomRating para ese documento. El efecto de este modelo es similar a ordenar todos los resultados de búsqueda, descendente, con el CustomRating propiedad administrada.
<?xml version="1.0"?>
<RankingModel2Stage name="RankModel1"
description="Rank model -- example 1"
id="D3FAF680-D213-4916-A95A-0409031643F8"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="619F2ECD-24F7-41CD-824C-234FC2EFDDCA" precalcEnabled="0" >
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<Static name="CustomRating" propertyName="CustomRating" default="0.0">
<Transform type="Linear" a="1" b="0" maxx="1000"/>
<Layer1Weights>
<Weight>1.0</Weight>
</Layer1Weights>
</Static>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Ejemplo 2: Modelo de clasificación más complejo con una fase lineal y cuatro características de clasificación
Este modelo de clasificación con una fase lineal contiene estas cuatro características de clasificación:
BM25Esta característica de clasificación se basa en las propiedades administradas Título y cuerpo; Elwatributo de title se establece de modo que los aciertos de los términos de consulta en Title son dos veces (2 veces) más importantes que los aciertos de los términos de consulta en el cuerpo.UrlDepthEsta característica de clasificación se basa en la propiedad UrlDepth administrados, que está disponible de forma predeterminada en las instalaciones de SharePoint. UrlDepth contiene el número de barras diagonales inversas (\) en la dirección URL de un documento. La transformación inversa racional (InvRational) garantiza que los documentos con direcciones URL más cortas recibirán puntuaciones de clasificación superiores.TitleProximityEsta característica de clasificación mejora la posición de los documentos si algunos de los términos de consulta se producen próximos entre sí en el title de estos documentos.InternalFileTypeEsta característica de clasificación aumenta documentos de tipo HTML, DOC, XLS o PPT. Los nombres de los cubos en la definición del modelo de clasificación se proporcionan para mejorar la legibilidad sólo.Nota:
La
InternalFileTypepropiedad administrada, disponible de forma predeterminada, usa el valor cero (0) para codificar documentos HTML, valor1para DOC, valor2para XLS, etc. Vea la definición del modelo de clasificación predeterminado de SharePoint para obtener una lista de todos los tipos de archivo utilizado para la propiedad FileType administrado.
<?xml version="1.0"?>
<RankingModel2Stage name=" RankModel2"
description="Rank model -- example 2"
id="DE48A3A1-67CE-44A2-9712-E8A5128787CF"
xmlns="urn:Microsoft.Search.Ranking.Model.2NN">
<RankingModel2NN id="A0A030D1-805D-437E-A001-CC151ED7473A" precalcEnabled="0">
<HiddenNodes count="1">
<Thresholds>
<Threshold>0</Threshold>
</Thresholds>
<Layer2Weights>
<Weight>1</Weight>
</Layer2Weights>
</HiddenNodes>
<RankingFeatures>
<BM25Main name="BM25" k1="1">
<Layer1Weights>
<Weight>1</Weight>
</Layer1Weights>
<Properties>
<Property name="Title" propertyName="Title" w="2" b="0.5" />
<Property name="body" propertyName="body" w="1" b="0.5" />
</Properties>
</BM25Main>
<Static name="UrlDepth" propertyName="UrlDepth" default="1">
<Transform type="InvRational" k="1.5"/>
<Layer1Weights>
<Weight>0.5</Weight>
</Layer1Weights>
</Static>
<MinSpan name="TitleProximity" propertyName="Title" default="0" maxMinSpan="1" isExact="0" isDiscounted="0">
<Normalize SDev="1" Mean="0"/>
<Transform type="Linear" a="1" b="-0.5" maxx="2"/>
<Layer1Weights>
<Weight>1.2</Weight>
</Layer1Weights>
</MinSpan>
<BucketedStatic name="InternalFileType" propertyName="InternalFileType" default="0">
<Bucket name="http" value="0">
<HiddenNodesAdds>
<Add>1.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="doc" value="1">
<HiddenNodesAdds>
<Add>2.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="ppt" value="2">
<HiddenNodesAdds>
<Add>0.5</Add>
</HiddenNodesAdds>
</Bucket>
<Bucket name="xls" value="3">
<HiddenNodesAdds>
<Add>-3.5</Add>
</HiddenNodesAdds>
</Bucket>
</BucketedStatic>
</RankingFeatures>
</RankingModel2NN>
</RankingModel2Stage>
Vea también
- Buscar en SharePoint
- Referencia de la sintaxis del lenguaje de consultas de palabras clave (KQL)
- Referencia de sintaxis sobre el lenguaje de consulta FAST (FQL)
- Información general de los resultados de búsqueda de clasificación en SharePoint
- Create a custom ranking model by using the Ranking Model Tuning App (Crear un modelo de clasificación personalizado mediante la aplicación Ranking Model Tuning)