Serialización del modelo de datos hacia y desde diferentes almacenes (versión preliminar)
Para que el modelo de datos se almacene en una base de datos, debe convertirse a un formato que la base de datos pueda comprender. Las distintas bases de datos requieren diferentes formatos y esquemas de almacenamiento. Algunos tienen un esquema estricto al que se debe cumplir, mientras que otros permiten que el usuario defina el esquema.
Opciones de mapeo
Los conectores de almacén de vectores proporcionados por el Kernel Semántico ofrecen varias maneras de lograr esta asignación.
Asignadores integrados
Los conectores de almacén de vectores proporcionados por Kernel Semántico tienen asignadores integrados que asignarán el modelo de datos hacia y desde los esquemas de base de datos. Consulte la página de cada conector para obtener más información sobre cómo los asignadores integrados asignan los datos para cada base de datos.
Asignadores personalizados
Los conectores de almacén de vectores proporcionados por el Kernel Semántico permiten proporcionar mapeadores personalizados en combinación con un VectorStoreRecordDefinition. En este caso, el VectorStoreRecordDefinition puede diferir del modelo de datos proporcionado.
El VectorStoreRecordDefinition se usa para definir el esquema de la base de datos, mientras que el desarrollador usa el modelo de datos para interactuar con el almacén de vectores.
En este caso, se requiere un mapeador personalizado para mapear desde el modelo de datos al esquema de base de datos personalizado definido por el VectorStoreRecordDefinition.
Propina
Consulte Cómo crear un mapeador personalizado para un conector de Vector Store para ver un ejemplo de cómo hacer su propio mapeador personalizado.
Para que el modelo de datos se defina como una clase o una definición que se va a almacenar en una base de datos, debe serializarse en un formato que la base de datos pueda comprender.
Hay dos maneras de hacerlo, ya sea mediante la serialización integrada proporcionada por el kernel semántico o proporcionando su propia lógica de serialización.
En los dos diagramas siguientes se muestran los flujos para la serialización y deserialización de modelos de datos hacia y desde un modelo de almacén.
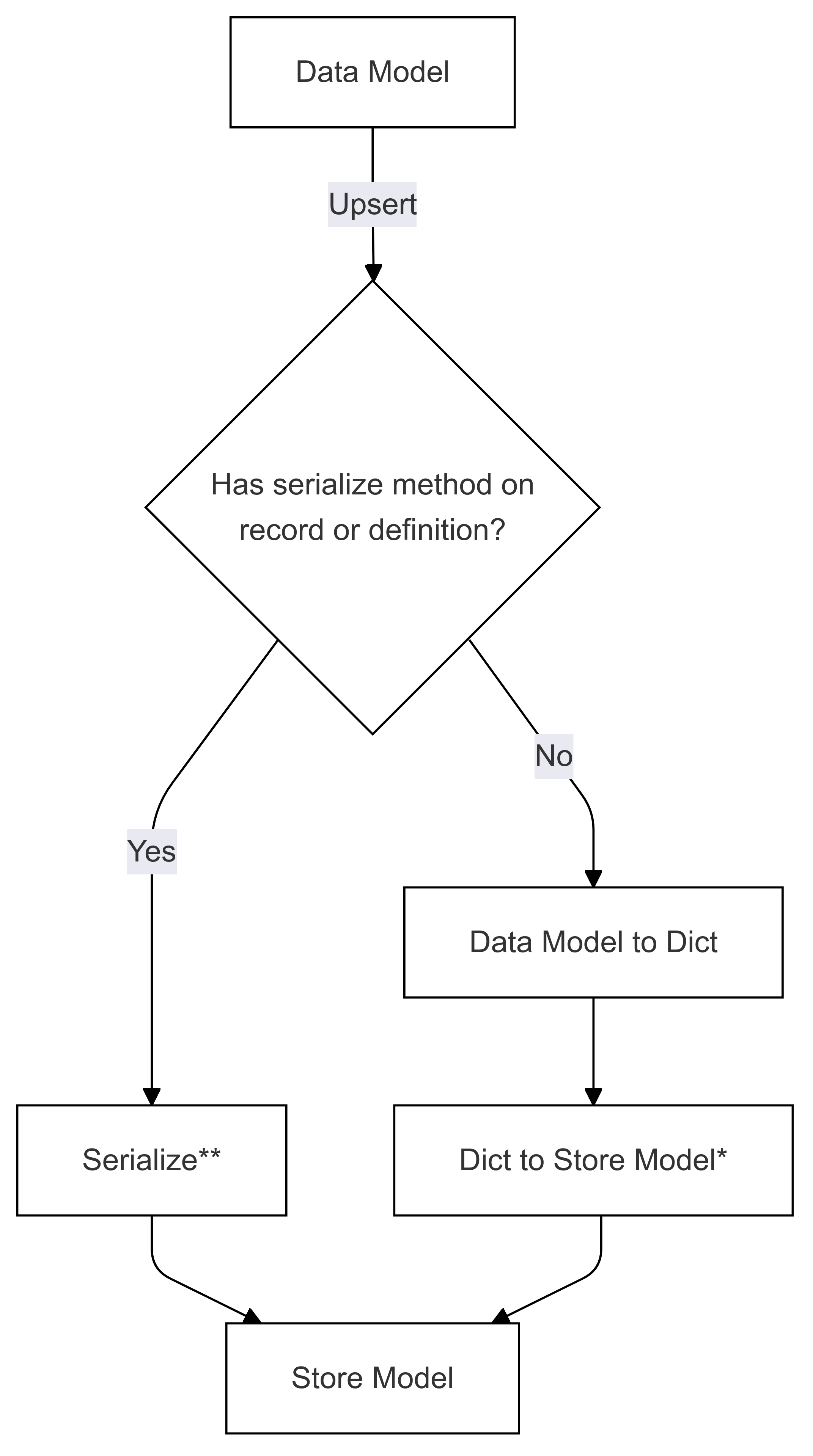
Flujo de serialización (usado en Upsert)
Flujo de deserialización (usado en Obtener y buscar)
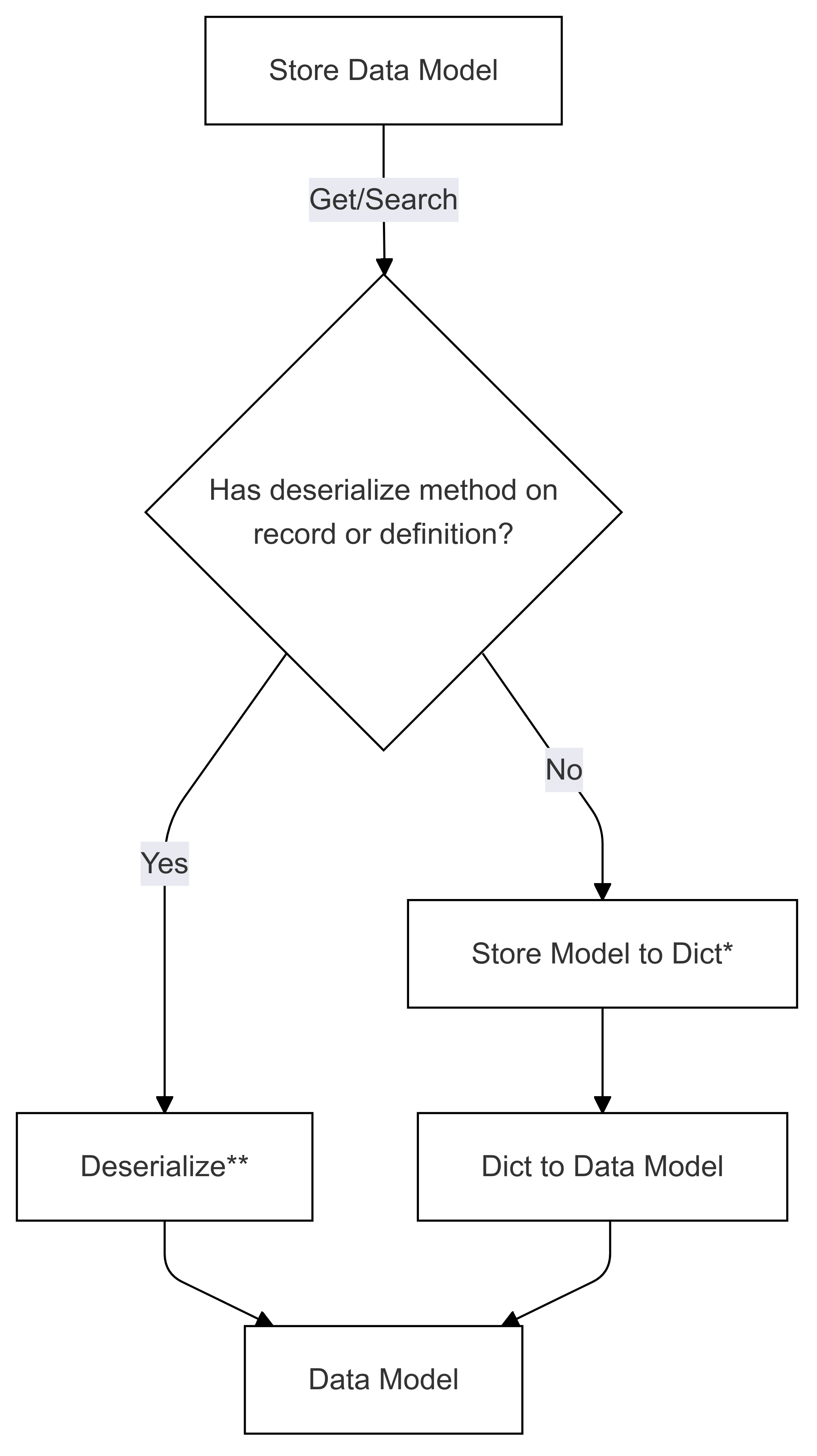
Los pasos marcados con * (en ambos diagramas) se implementan mediante el desarrollador de un conector específico y son diferentes para cada almacén. Los pasos marcados con ** (en ambos diagramas) se proporcionan como método en un registro o como parte de la definición de registro, siempre lo proporciona el usuario, consulte Direct Serialization para obtener más información.
(De)Enfoques de serialización
Serialización directa (modelo de datos a modelo de almacenamiento)
La serialización directa es la mejor manera de garantizar el control total sobre cómo se serializan los modelos y optimizar el rendimiento. El inconveniente es que es específico de un almacén de datos y, por lo tanto, al usar esto no es tan fácil cambiar entre almacenes diferentes con el mismo modelo de datos.
Para ello, puede implementar un método que siga el protocolo SerializeMethodProtocol en el modelo de datos o agregando funciones que siguen el SerializeFunctionProtocol a la definición de registro, ambas se pueden encontrar en semantic_kernel/data/vector_store_model_protocols.py.
Cuando haya una de esas funciones, se usará para serializar directamente el modelo de datos en el modelo de almacén.
Incluso podría implementar solo uno de los dos y usar la (de)serialización incorporada para la otra dirección. Esto podría ser útil, por ejemplo, cuando se trabaja con una colección que fue creada fuera de su control y se necesita hacer alguna personalización en la forma en que se deserializa (y de todos modos, no se puede realizar un "upsert").
Serialización/deserialización incorporada (modelo de datos a diccionario y diccionario a modelo de almacén y viceversa)
La serialización integrada se realiza mediante la conversión del modelo de datos en un diccionario y, a continuación, serializarlo en el modelo que el almacén entiende, para cada almacén diferente y definido como parte del conector integrado. La deserialización se realiza en orden inverso.
Paso 1 de serialización: Modelo de datos a dict
En función del tipo de modelo de datos que tenga, los pasos se realizan de maneras diferentes. Hay cuatro maneras de serializar el modelo de datos en un diccionario:
-
to_dictmétodo en la definición (se alinea con el atributo to_dict del modelo de datos, siguiendo elToDictFunctionProtocol) - compruebe si el registro es un
ToDictMethodProtocoly use el métodoto_dict - Verifique si el registro es un modelo Pydantic y use el
model_dumpdel modelo, consulte la nota abajo para más información. - recorrer en bucle los campos de la definición y crear el diccionario
Paso 2 de serialización: Dict to Store Model
El conector debe proporcionar un método para convertir el diccionario en el modelo de almacén. Esto lo hace el desarrollador del conector y es diferente para cada tienda.
Paso 1 de deserialización: Almacenar el modelo en Dict
El conector debe proporcionar un método para convertir el modelo de almacén en un diccionario. Esto lo hace el desarrollador del conector y es diferente para cada tienda.
Paso 2 de deserialización: Dict to Data Model
La deserialización se realiza en orden inverso, intenta estas opciones:
-
from_dictmétodo en la definición (se alinea con el atributo from_dict del modelo de datos, siguiendo elFromDictFunctionProtocol) - compruebe si el registro es un
FromDictMethodProtocoly use el métodofrom_dict - Compruebe si el registro es un modelo Pydantic y use la
model_validatedel modelo, consulte la nota siguiente para obtener más información. - recorrer en bucle los campos de la definición y establecer los valores, este dict se pasa al constructor del modelo de datos como argumentos con nombre (a menos que el modelo de datos sea un dict en sí, en ese caso se devuelve tal como está).
Nota
Uso de Pydantic con serialización integrada
Al definir el modelo mediante un modelo BaseModel pydantic, usará los model_dump métodos y model_validate para serializar y deserializar el modelo de datos hacia y desde un dict. Esto se hace mediante el método model_dump sin parámetros. Si desea controlarlo, considere la posibilidad de implementar la ToDictMethodProtocol en el modelo de datos, ya que eso se intenta primero.
Serialización de vectores
Cuando tiene un vector en el modelo de datos, debe ser una lista de floats o una lista de ints, ya que es lo que necesitan la mayoría de los almacenes, si desea que la clase almacene el vector en un formato diferente, puede usar y serialize_functiondeserialize_function definir en la VectorStoreRecordVectorField anotación. Por ejemplo, para una matriz numpy, puede usar la anotación siguiente:
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
Si usa un almacén de vectores que puede controlar matrices de numpy nativas y no desea convertirlos hacia atrás y hacia adelante, debe configurar el serialización directa y deserialización métodos para el modelo y ese almacén.
Nota
Esto solo se usa cuando se usa la serialización integrada, cuando se usa la serialización directa, puede controlar el vector de cualquier manera que desee.
Próximamente
Más información próximamente.