¿Qué es un complemento?
Los complementos son un componente clave del kernel semántico. Si ya ha usado complementos de chatGPT o extensiones de Copilot en Microsoft 365, ya está familiarizado con ellos. Con los complementos, puede encapsular las API existentes en una colección que puede usar una inteligencia artificial. Esto le permite dar a la inteligencia artificial la capacidad de realizar acciones que no podrían hacer de otro modo.
En segundo plano, el kernel semántico aprovecha función que llama a, una característica nativa de la mayoría de las MÁQUINAS VIRTUALES más recientes para permitir que las LLM, realicen planeación e invoquen las API. Con la llamada a funciones, los LLM pueden solicitar (es decir, llamar a) una función particular. A continuación, el Kernel Semántico dirige la solicitud a la función adecuada en tu código base y devuelve los resultados al LLM para que este pueda generar una respuesta final.
No todos los SDK de IA tienen un concepto análogo a los complementos (la mayoría solo tiene funciones o herramientas). Sin embargo, en escenarios empresariales, los complementos son valiosos porque encapsulan un conjunto de funcionalidades que refleja cómo los desarrolladores empresariales ya desarrollan servicios y API. Los complementos también juegan bien con la inserción de dependencias. Dentro del constructor de un complemento, puede insertar servicios necesarios para realizar el trabajo del complemento (por ejemplo, conexiones de base de datos, clientes HTTP, etc.). Esto es difícil de lograr con otros SDK que carecen de complementos.
Anatomía de un complemento
En un nivel alto, un complemento es un grupo de funciones de que se pueden exponer a aplicaciones y servicios de inteligencia artificial. Las funciones dentro de los complementos se pueden orquestar mediante una aplicación de inteligencia artificial para realizar solicitudes de usuario. Dentro del kernel semántico, puede invocar estas funciones automáticamente con la llamada a funciones.
Nota
En otras plataformas, las funciones a menudo se conocen como "herramientas" o "acciones". En kernel semántico, se usa el término "funciones", ya que normalmente se definen como funciones nativas en el código base.
Sin embargo, simplemente proporcionar funciones no es suficiente para crear un complemento. Para impulsar la orquestación automática con llamadas a funciones, los complementos también deben proporcionar detalles que describan semánticamente cómo se comportan. Es necesario describir la entrada, salida y efectos secundarios de la función de tal manera que la inteligencia artificial pueda comprenderlos, de lo contrario, no llamará correctamente a la función.
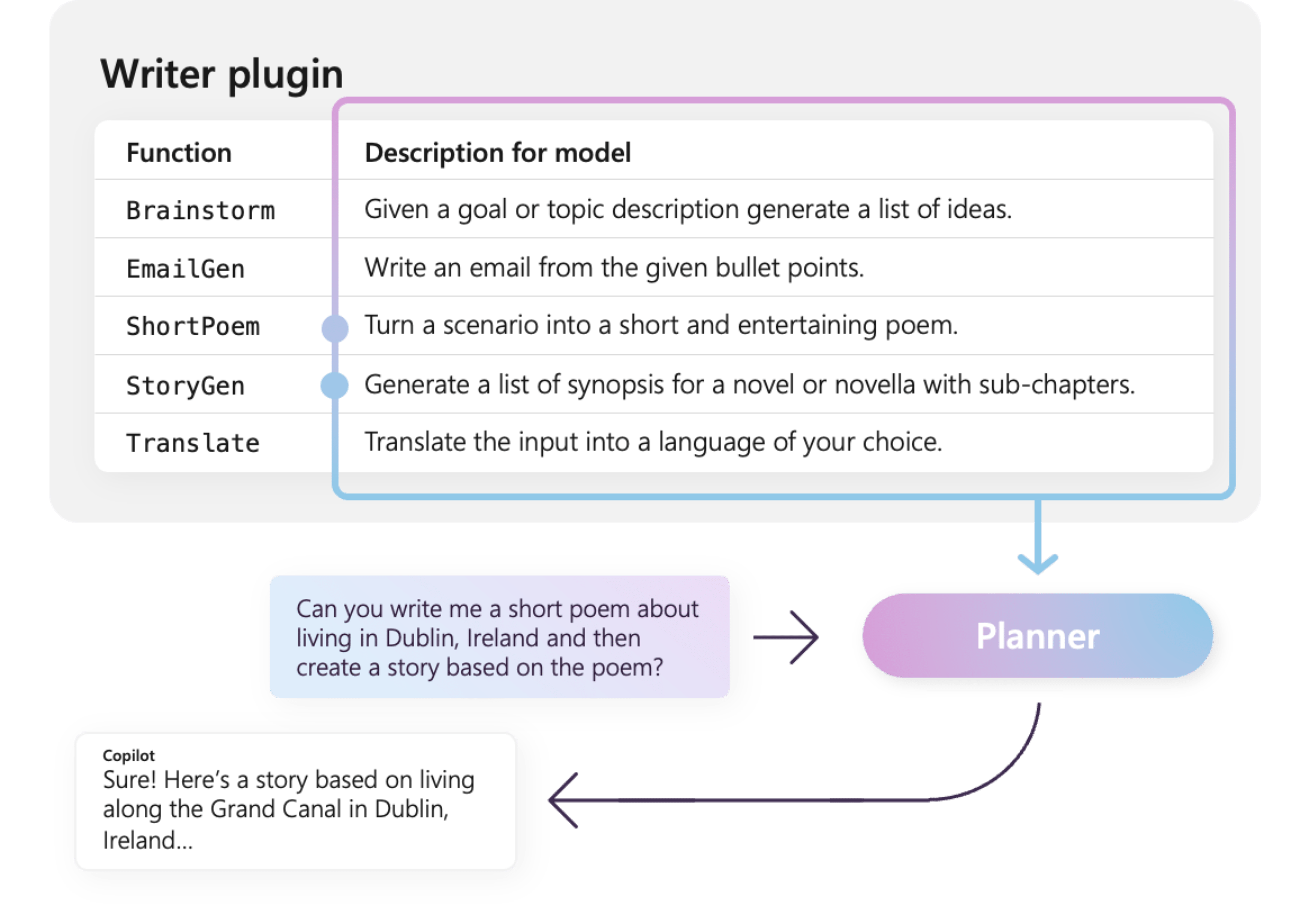
Por ejemplo, el complemento WriterPlugin de ejemplo de la derecha tiene funciones con descripciones semánticas que describen lo que hace cada función. A continuación, un LLM puede usar estas descripciones para elegir las mejores funciones a las que llamar para cumplir la pregunta de un usuario.
En la imagen de la derecha, es probable que un LLM llame a las funciones ShortPoem y StoryGen para satisfacer la petición de los usuarios gracias a las descripciones semánticas proporcionadas.
Importación de diferentes tipos de complementos
Hay dos formas principales de importar complementos en kernel semántico: usar código nativo o usar una especificación de OpenAPI . El primero le permite crear complementos en el código base existente que puede aprovechar las dependencias y los servicios que ya tiene. Este último le permite importar complementos de una especificación de OpenAPI, que se puede compartir entre diferentes lenguajes de programación y plataformas.
A continuación se proporciona un ejemplo sencillo de importación y uso de un complemento nativo. Para obtener más información sobre cómo importar estos diferentes tipos de complementos, consulte los siguientes artículos:
Propina
Al empezar, se recomienda usar complementos de código nativo. A medida que la aplicación madura y a medida que trabaja en equipos multiplataforma, puede considerar la posibilidad de usar especificaciones de OpenAPI para compartir complementos en diferentes lenguajes de programación y plataformas.
Los distintos tipos de funciones de complemento
Dentro de un complemento, normalmente tendrá dos tipos diferentes de funciones, las que recuperan datos para la generación aumentada de recuperación (RAG) y las que automatizan tareas. Aunque cada tipo es funcionalmente el mismo, normalmente se usan de forma diferente dentro de las aplicaciones que usan kernel semántico.
Por ejemplo, con las funciones de recuperación, puede usar estrategias para mejorar el rendimiento (por ejemplo, el almacenamiento en caché y el uso de modelos intermedios más baratos para el resumen). Mientras que con las funciones de automatización de tareas, probablemente querrá implementar procesos de aprobación con intervención humana para asegurarse de que las tareas se completan correctamente.
Para obtener más información sobre los distintos tipos de funciones de complemento, consulte los siguientes artículos:
Introducción a los complementos
El uso de complementos dentro del kernel semántico siempre es un proceso de tres pasos:
- Definir el complemento
- Añade el complemento al kernel
- Luego, invoque las funciones del complemento en una solicitud o mediante una llamada de función
A continuación, proporcionaremos un ejemplo de alto nivel de cómo usar un complemento dentro del kernel semántico. Consulte los vínculos anteriores para obtener información más detallada sobre cómo crear y usar complementos.
1) Definir el complemento
La manera más fácil de crear un complemento es definir una clase y anotar sus métodos con el atributo KernelFunction. Esto le dice al kernel semántico que se trata de una función a la que puede llamar una inteligencia artificial o a la que se puede hacer referencia en un aviso.
También puede importar complementos desde una especificación OpenAPI de .
A continuación, crearemos un complemento que pueda recuperar el estado de las luces y modificar su estado.
Propina
Dado que la mayoría de los LLM han sido entrenados con Python para las llamadas a funciones, se recomienda usar la notación de serpiente para los nombres de funciones y propiedades, incluso si está utilizando el SDK de C# o Java.
using System.ComponentModel;
using Microsoft.SemanticKernel;
public class LightsPlugin
{
// Mock data for the lights
private readonly List<LightModel> lights = new()
{
new LightModel { Id = 1, Name = "Table Lamp", IsOn = false, Brightness = 100, Hex = "FF0000" },
new LightModel { Id = 2, Name = "Porch light", IsOn = false, Brightness = 50, Hex = "00FF00" },
new LightModel { Id = 3, Name = "Chandelier", IsOn = true, Brightness = 75, Hex = "0000FF" }
};
[KernelFunction("get_lights")]
[Description("Gets a list of lights and their current state")]
[return: Description("An array of lights")]
public async Task<List<LightModel>> GetLightsAsync()
{
return lights
}
[KernelFunction("get_state")]
[Description("Gets the state of a particular light")]
[return: Description("The state of the light")]
public async Task<LightModel?> GetStateAsync([Description("The ID of the light")] int id)
{
// Get the state of the light with the specified ID
return lights.FirstOrDefault(light => light.Id == id);
}
[KernelFunction("change_state")]
[Description("Changes the state of the light")]
[return: Description("The updated state of the light; will return null if the light does not exist")]
public async Task<LightModel?> ChangeStateAsync(int id, LightModel LightModel)
{
var light = lights.FirstOrDefault(light => light.Id == id);
if (light == null)
{
return null;
}
// Update the light with the new state
light.IsOn = LightModel.IsOn;
light.Brightness = LightModel.Brightness;
light.Hex = LightModel.Hex;
return light;
}
}
public class LightModel
{
[JsonPropertyName("id")]
public int Id { get; set; }
[JsonPropertyName("name")]
public string Name { get; set; }
[JsonPropertyName("is_on")]
public bool? IsOn { get; set; }
[JsonPropertyName("brightness")]
public byte? Brightness { get; set; }
[JsonPropertyName("hex")]
public string? Hex { get; set; }
}
from typing import TypedDict, Annotated
class LightModel(TypedDict):
id: int
name: str
is_on: bool | None
brightness: int | None
hex: str | None
class LightsPlugin:
lights: list[LightModel] = [
{"id": 1, "name": "Table Lamp", "is_on": False, "brightness": 100, "hex": "FF0000"},
{"id": 2, "name": "Porch light", "is_on": False, "brightness": 50, "hex": "00FF00"},
{"id": 3, "name": "Chandelier", "is_on": True, "brightness": 75, "hex": "0000FF"},
]
@kernel_function
async def get_lights(self) -> Annotated[list[LightModel], "An array of lights"]:
"""Gets a list of lights and their current state."""
return self.lights
@kernel_function
async def get_state(
self,
id: Annotated[int, "The ID of the light"]
) -> Annotated[LightModel | None], "The state of the light"]:
"""Gets the state of a particular light."""
for light in self.lights:
if light["id"] == id:
return light
return None
@kernel_function
async def change_state(
self,
id: Annotated[int, "The ID of the light"],
new_state: LightModel
) -> Annotated[Optional[LightModel], "The updated state of the light; will return null if the light does not exist"]:
"""Changes the state of the light."""
for light in self.lights:
if light["id"] == id:
light["is_on"] = new_state.get("is_on", light["is_on"])
light["brightness"] = new_state.get("brightness", light["brightness"])
light["hex"] = new_state.get("hex", light["hex"])
return light
return None
public class LightsPlugin {
// Mock data for the lights
private final Map<Integer, LightModel> lights = new HashMap<>();
public LightsPlugin() {
lights.put(1, new LightModel(1, "Table Lamp", false));
lights.put(2, new LightModel(2, "Porch light", false));
lights.put(3, new LightModel(3, "Chandelier", true));
}
@DefineKernelFunction(name = "get_lights", description = "Gets a list of lights and their current state")
public List<LightModel> getLights() {
System.out.println("Getting lights");
return new ArrayList<>(lights.values());
}
@DefineKernelFunction(name = "change_state", description = "Changes the state of the light")
public LightModel changeState(
@KernelFunctionParameter(name = "id", description = "The ID of the light to change") int id,
@KernelFunctionParameter(name = "isOn", description = "The new state of the light") boolean isOn) {
System.out.println("Changing light " + id + " " + isOn);
if (!lights.containsKey(id)) {
throw new IllegalArgumentException("Light not found");
}
lights.get(id).setIsOn(isOn);
return lights.get(id);
}
}
Observe que se proporcionan descripciones para la función, el valor devuelto y los parámetros. Esto es importante para que la inteligencia artificial comprenda lo que hace la función y cómo usarla.
Propina
No tengas miedo de dar descripciones detalladas de tus funciones si una inteligencia artificial tiene problemas para usarlas. Algunos ejemplos de capturas, recomendaciones para cuándo usar (y no usar) la función y las instrucciones sobre dónde obtener los parámetros necesarios pueden resultar útiles.
2) Agregar el complemento al kernel
Una vez que haya definido el complemento, puede agregarlo al kernel creando una nueva instancia del complemento y agregándola a la colección de complementos del kernel.
En este ejemplo se muestra la manera más sencilla de agregar una clase como complemento con el método AddFromType. Para obtener información sobre otras formas de agregar complementos, consulte el artículo adición de complementos nativos.
var builder = new KernelBuilder();
builder.Plugins.AddFromType<LightsPlugin>("Lights")
Kernel kernel = builder.Build();
kernel = Kernel()
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
// Import the LightsPlugin
KernelPlugin lightPlugin = KernelPluginFactory.createFromObject(new LightsPlugin(),
"LightsPlugin");
// Create a kernel with Azure OpenAI chat completion and plugin
Kernel kernel = Kernel.builder()
.withAIService(ChatCompletionService.class, chatCompletionService)
.withPlugin(lightPlugin)
.build();
3) Invocar las funciones del complemento
Por último, puede hacer que la inteligencia artificial invoque las funciones del complemento mediante una llamada a función. A continuación se muestra un ejemplo que demuestra cómo persuadir a la IA para llamar a la función get_lights del complemento Lights antes de llamar a la función change_state para encender una luz.
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
using Microsoft.SemanticKernel.Connectors.OpenAI;
// Create a kernel with Azure OpenAI chat completion
var builder = Kernel.CreateBuilder().AddAzureOpenAIChatCompletion(modelId, endpoint, apiKey);
// Build the kernel
Kernel kernel = builder.Build();
var chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
// Add a plugin (the LightsPlugin class is defined below)
kernel.Plugins.AddFromType<LightsPlugin>("Lights");
// Enable planning
OpenAIPromptExecutionSettings openAIPromptExecutionSettings = new()
{
FunctionChoiceBehavior = FunctionChoiceBehavior.Auto()
};
// Create a history store the conversation
var history = new ChatHistory();
history.AddUserMessage("Please turn on the lamp");
// Get the response from the AI
var result = await chatCompletionService.GetChatMessageContentAsync(
history,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel);
// Print the results
Console.WriteLine("Assistant > " + result);
// Add the message from the agent to the chat history
history.AddAssistantMessage(result);
import asyncio
from semantic_kernel import Kernel
from semantic_kernel.functions import kernel_function
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
from semantic_kernel.connectors.ai.function_choice_behavior import FunctionChoiceBehavior
from semantic_kernel.connectors.ai.chat_completion_client_base import ChatCompletionClientBase
from semantic_kernel.contents.chat_history import ChatHistory
from semantic_kernel.functions.kernel_arguments import KernelArguments
from semantic_kernel.connectors.ai.open_ai.prompt_execution_settings.azure_chat_prompt_execution_settings import (
AzureChatPromptExecutionSettings,
)
async def main():
# Initialize the kernel
kernel = Kernel()
# Add Azure OpenAI chat completion
chat_completion = AzureChatCompletion(
deployment_name="your_models_deployment_name",
api_key="your_api_key",
base_url="your_base_url",
)
kernel.add_service(chat_completion)
# Add a plugin (the LightsPlugin class is defined below)
kernel.add_plugin(
LightsPlugin(),
plugin_name="Lights",
)
# Enable planning
execution_settings = AzureChatPromptExecutionSettings()
execution_settings.function_call_behavior = FunctionChoiceBehavior.Auto()
# Create a history of the conversation
history = ChatHistory()
history.add_message("Please turn on the lamp")
# Get the response from the AI
result = await chat_completion.get_chat_message_content(
chat_history=history,
settings=execution_settings,
kernel=kernel,
)
# Print the results
print("Assistant > " + str(result))
# Add the message from the agent to the chat history
history.add_message(result)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())
// Enable planning
InvocationContext invocationContext = new InvocationContext.Builder()
.withReturnMode(InvocationReturnMode.LAST_MESSAGE_ONLY)
.withToolCallBehavior(ToolCallBehavior.allowAllKernelFunctions(true))
.build();
// Create a history to store the conversation
ChatHistory history = new ChatHistory();
history.addUserMessage("Turn on light 2");
List<ChatMessageContent<?>> results = chatCompletionService
.getChatMessageContentsAsync(history, kernel, invocationContext)
.block();
System.out.println("Assistant > " + results.get(0));
Con el código anterior, debería obtener una respuesta similar a la siguiente:
| Rol | Mensaje |
|---|---|
| 🔵 usuario | Por favor, enciende la lámpara. |
| 🔴 Assistant (llamada de función) | Lights.get_lights() |
| 🟢 Herramienta | [{ "id": 1, "name": "Table Lamp", "isOn": false, "brightness": 100, "hex": "FF0000" }, { "id": 2, "name": "Porch light", "isOn": false, "brightness": 50, "hex": "00FF00" }, { "id": 3, "name": "Chandelier", "isOn": true, "brightness": 75, "hex": "0000FF" }] |
| 🔴 Assistant (llamada de función) | Lights.change_state(1, { "isOn": true }) |
| 🟢 herramienta | { "id": 1, "name": "Table Lamp", "isOn": true, "brightness": 100, "hex": "FF0000" } |
| 🔴 asistente | La lámpara está ahora activada |
Propina
Aunque puede invocar directamente una función de complemento, esto no se recomienda porque la inteligencia artificial debe ser la que decida qué funciones llamar. Si necesita un control explícito sobre las funciones a las que se llama, considere la posibilidad de usar métodos estándar en el código base en lugar de complementos.
Recomendaciones generales para crear complementos
Teniendo en cuenta que cada escenario tiene requisitos únicos, utiliza diseños de complementos distintos y puede incorporar varios modelos de lenguaje grandes (LLMs), resulta difícil proporcionar una guía única para el diseño de complementos. Sin embargo, a continuación se muestran algunas recomendaciones y directrices generales para asegurarse de que los complementos son compatibles con la inteligencia artificial y que los LLMs pueden consumir de forma fácil y eficaz.
Importar solo los complementos necesarios
Importe solo los complementos que contienen funciones necesarias para su escenario específico. Este enfoque no solo reducirá el número de tokens de entrada consumidos, sino que también minimizará la ocurrencia de llamadas erróneas a funciones que no se utilizan en el escenario. En general, esta estrategia debe mejorar la precisión en la invocación de funciones y reducir el número de falsos positivos.
Además, OpenAI recomienda que no use más de 20 herramientas en una sola llamada API; idealmente, no más de 10 herramientas. Como se indicó en OpenAI: "Se recomienda que no use más de 20 herramientas en una sola llamada API. Normalmente, los desarrolladores ven una reducción de la capacidad del modelo para seleccionar la herramienta correcta una vez que tienen entre 10 y 20 herramientas definidas".* Para obtener más información, puede visitar su documentación en Guía de llamadas de funciones de OpenAI.
Hacer que los complementos sean amigables con la inteligencia artificial
Para mejorar la capacidad de LLM para comprender y usar complementos, se recomienda seguir estas instrucciones:
Use nombres de función descriptivos y concisos: Asegúrese de que los nombres de función transmitan claramente su propósito para ayudar al modelo a comprender cuándo seleccionar cada función. Si un nombre de función es ambiguo, considere la posibilidad de cambiar su nombre para mayor claridad. Evite usar abreviaturas o acrónimos para acortar los nombres de función. Use el
DescriptionAttributepara proporcionar contexto e instrucciones adicionales solo cuando sea necesario, lo que minimiza el consumo de tokens.Minimizar parámetros de función: Limitar el número de parámetros de función y usar tipos primitivos siempre que sea posible. Este enfoque reduce el consumo de tokens y simplifica la firma de la función, lo que facilita que el LLM coincida con los parámetros de la función de forma eficaz.
Nombra claramente los parámetros de las funciones: Asigna nombres descriptivos a los parámetros de las funciones para aclarar su propósito. Evite usar abreviaturas o acrónimos para acortar los nombres de parámetro, ya que esto ayudará al LLM a razonar sobre los parámetros y proporcionar valores precisos. Al igual que con los nombres de función, use el
DescriptionAttributesolo cuando sea necesario para minimizar el consumo de tokens.
Buscar un equilibrio adecuado entre el número de funciones y sus responsabilidades
Por un lado, tener funciones con una sola responsabilidad es una buena práctica que permite mantener funciones sencillas y reutilizables en varios escenarios. Por otro lado, cada llamada de función incurre en sobrecarga en términos de latencia de ida y vuelta de red y el número de tokens de entrada y salida consumidos: los tokens de entrada se usan para enviar la definición de función y el resultado de la invocación al LLM, mientras que los tokens de salida se consumen al recibir la llamada de función del modelo.
Como alternativa, se puede implementar una sola función con varias responsabilidades para reducir el número de tokens consumidos y reducir la sobrecarga de red, aunque esto conlleva una menor reutilización en otros escenarios.
Sin embargo, la consolidación de muchas responsabilidades en una sola función puede aumentar el número y la complejidad de los parámetros de función y su tipo de valor devuelto. Esta complejidad puede provocar situaciones en las que el modelo puede tener dificultades para coincidir correctamente con los parámetros de función, lo que da lugar a parámetros o valores que faltan o a valores de tipo incorrecto. Por lo tanto, es esencial alcanzar el equilibrio adecuado entre el número de funciones para reducir la sobrecarga de red y el número de responsabilidades que tiene cada función, lo que garantiza que el modelo pueda coincidir con precisión con los parámetros de función.
Transformación de funciones de kernel semántico
Utilice las técnicas de transformación para las funciones del kernel semántico tal y como se describe en la entrada del blog 'Transformación de funciones del kernel semántico' a:
Cambiar el comportamiento de la función: Hay escenarios en los que el comportamiento predeterminado de una función puede no alinearse con el resultado deseado y no es factible modificar la implementación de la función original. En tales casos, puede crear una nueva función que encapsula la original y modifica su comportamiento en consecuencia.
Proporcionar información de contexto: Functions puede requerir parámetros que el LLM no puede o no debe deducir. Por ejemplo, si una función necesita actuar en nombre del usuario actual o requiere información de autenticación, este contexto suele estar disponible para la aplicación host, pero no para el LLM. En tales casos, puedes transformar la función para invocar a la original proporcionando la información de contexto necesaria desde la aplicación anfitriona, junto con los argumentos proporcionados por el LLM.
Lista de parámetros de cambio, tipos y nombres: Si la función original tiene una firma compleja que el LLM tiene dificultades para interpretar, puede transformar la función en una con una firma más sencilla que el LLM pueda comprender más fácilmente. Esto puede implicar cambiar los nombres de parámetro, los tipos, el número de parámetros y aplanar o desaplanar parámetros complejos, entre otros ajustes.
Uso del estado local
Al diseñar complementos que funcionan en conjuntos de datos relativamente grandes o confidenciales, como documentos, artículos o correos electrónicos que contienen información confidencial, considere la posibilidad de usar el estado local para almacenar datos originales o resultados intermedios que no es necesario enviar al LLM. Las funciones de estos escenarios pueden aceptar y devolver un identificador de estado, lo que permite buscar y acceder a los datos localmente en lugar de pasar los datos reales al LLM, solo para recibirlos como argumento para la siguiente invocación de función.
Al almacenar los datos localmente, puede mantener la información privada y segura a la vez que evita el consumo innecesario de tokens durante las llamadas de función. Este enfoque no solo mejora la privacidad de los datos, sino que también mejora la eficacia general en el procesamiento de conjuntos de datos grandes o confidenciales.