Modelado de amenazas en inteligencia artificial y aprendizaje automático, sistemas y dependencias
Por Andrew Marshall, Jugal Parikh, Emre Kiciman y Ram Shankar Siva Kumar
Un agradecimiento especial a Raul Rojas y el equipo de ingeniería de seguridad de AETHER
Noviembre de 2019
Este documento es producto de las Prácticas de ingeniería de AETHER para el grupo de trabajo sobre IA, y complementa las prácticas de modelado de amenazas de SDL existentes, ya que proporciona nuevas guías sobre la enumeración y mitigación de amenazas específicas del espacio de inteligencia artificial y aprendizaje automático. Está pensado para usarse como referencia durante las revisiones de los diseños de seguridad de lo siguiente:
Productos o servicios que interactúan con servicios basados en inteligencia artificial o aprendizaje automático o asuman dependencias en estos
Productos/servicios que se creen con inteligencia artificial o aprendizaje automático como base
La mitigación de amenazas de seguridad tradicionales es más importante que nunca. Los requisitos establecidos por el Ciclo de vida de desarrollo de seguridad son esenciales para establecer una base de seguridad de productos sobre la que se basa esta guía. Si no se abordan las amenazas de seguridad tradicionales, se ayudará a permitir los ataques específicos a la inteligencia artificial y el aprendizaje automático que se tratan en este documento tanto en el dominio de software como en el físico, así como considerar trivial los riesgos disminuye la pila de software. Para obtener una introducción a las nuevas amenazas de seguridad en este espacio, consulte Protección del futuro de la inteligencia artificial y el aprendizaje automático en Microsoft.
Los conjuntos de aptitudes de los ingenieros de seguridad y científicos de datos no suelen solaparse. En esta guía se proporciona una manera de que ambas disciplinas mantengan conversaciones estructuradas sobre estas nuevas amenazas y mitigaciones sin necesidad de que los ingenieros de seguridad se conviertan en científicos de datos ni viceversa.
Este documento se divide en dos secciones:
- "Nuevas consideraciones clave en el modelado de amenazas" se centra en las nuevas formas de pensamiento y las nuevas preguntas que se deben formular al modelar las amenazas de los sistemas de inteligencia artificial y aprendizaje automático. Los científicos de datos y los ingenieros de seguridad deben revisar esto, ya que será su cuaderno de estrategias para las conversaciones sobre el modelado de amenazas y las prioridades de mitigación.
- "Amenazas específicas de inteligencia artificial y aprendizaje automático y sus mitigaciones" proporciona detalles sobre ataques específicos, así como los pasos de mitigación específicos que se usan hoy en día para proteger los productos y servicios de Microsoft frente a estas amenazas. Esta sección está dirigida principalmente a los científicos de datos que puedan necesitar implementar mitigaciones de amenazas específicas como salida del proceso de modelado de amenazas y revisión de seguridad.
Esta guía se organiza en torno a la taxonomía de amenazas adversarias de aprendizaje automático creada por Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen y Jeffrey Snover titulada "Modos de error en el aprendizaje automático". Para obtener una guía sobre la administración de incidentes en relación con la evaluación de las amenazas de seguridad que se detallan en este documento, consulte Barra de errores de SDL para amenazas de inteligencia artificial y aprendizaje automático. Todos ellos son documentos vivos que evolucionarán con el tiempo en función del panorama de amenazas.
Nuevas consideraciones clave en el modelado de riesgos: cambio de la forma en que se ven los límites de confianza
Suponga que los datos con los que entrena y el proveedor de datos están comprometidos o envenenados. Aprenda a detectar entradas de datos anómalas y malintencionadas, así como a distinguir entre ellas y recuperarse.
Resumen
Los almacenes de datos de entrenamiento y los sistemas que los hospedan forman parte de su ámbito de modelado de amenazas. En la actualidad, la mayor amenaza de seguridad en el aprendizaje automático es el envenenamiento de datos debido a la falta de detecciones y mitigaciones estándar en este espacio, combinadas con la dependencia en conjuntos de datos públicos que no están mantenidos o no son de confianza como orígenes de datos de entrenamiento. El seguimiento de la procedencia y el linaje de los datos es esencial para garantizar su confiabilidad y evitar un ciclo de entrenamiento de "garbage in, garbage out".
Preguntas que se deben formular en una revisión de seguridad
Si alguien ha envenenado o alterado sus datos, ¿cómo se daría cuenta?
- ¿Qué datos de telemetría tiene para detectar un sesgo en la calidad de los datos de entrenamiento?
¿Entrena el sistema a partir de entradas suministradas por los usuarios?
- ¿Qué tipo de validación/saneamiento de entradas ha puesto en práctica para ese contenido?
- ¿Se documenta la estructura de estos datos de forma similar a las hojas de datos para los conjuntos de datos?
Si entrena el sistema con almacenes de datos en línea, ¿qué pasos da para garantizar la seguridad de la conexión entre el modelo y los datos?
- ¿Tienen aquellos una manera de informar de los peligros a los consumidores de sus fuentes?
- ¿Son acaso capaces de hacerlo?
¿Qué nivel de confidencialidad tienen los datos a partir de los cuales entrena al sistema?
- ¿Catalogar o controla la adición, actualización o eliminación de entradas de datos?
¿Puede su modelo generar datos confidenciales?
- ¿Se obtuvieron estos datos con el permiso del origen?
El modelo, ¿solo genera resultados necesarios para alcanzar su objetivo?
¿Devuelve el modelo las puntuaciones de confianza sin procesar o cualquier otro resultado directo que se pueda registrar y duplicar?
¿Cuál es el impacto de que sus datos de entrenamiento se recuperen mediante el ataque o la inversión del modelo?
Si los niveles de confianza de la salida del modelo caen repentinamente, ¿puede averiguar cómo y por qué, así como qué datos lo provocaron?
¿Ha definido una entrada con un formato correcto para el modelo? ¿Qué está haciendo para asegurarse de que las entradas cumplan este formato y qué hace si no lo cumplen?
Si las salidas son incorrectas, pero no causan informes de errores, ¿cómo podría saberlo?
¿Sabe si los algoritmos de entrenamiento son resistentes a las entradas adversarias a nivel matemático?
¿Cómo se recupera de la contaminación adversaria de los datos de entrenamiento?
- ¿Puede aislar o poner en cuarentena el contenido adversario y volver a entrenar los modelos afectados?
- ¿Puede revertir o recuperar a un modelo de una versión anterior para volver a entrenar el sistema?
¿Usa el aprendizaje de refuerzo en el contenido público no mantenido?
Empiece a pensar en el linaje de sus datos: ¿ha encontrado un problema, podría realizar un seguimiento hasta su introducción en el conjunto de datos? Si no es así, ¿es eso un problema?
Sepa de dónde provienen sus datos de entrenamiento e identifique las normas estadísticas para empezar a comprender cómo se ven las anomalías.
- ¿Qué elementos de los datos de entrenamiento son vulnerables a la influencia externa?
- ¿Quién puede contribuir a los conjuntos de datos a partir de los cuales entrena su sistema?
-¿Cómo atacaría usted sus orígenes de datos de entrenamiento para perjudicar a un competidor?
Amenazas y mitigaciones relacionadas en este documento
Perturbación adversaria (todas las variantes)
Envenenamiento de datos (todas las variantes)
Ataques de ejemplo
Forzar la clasificación de correos electrónicos inofensivos como correo no deseado o provocar que un ejemplo malintencionado no se detecte.
Entradas diseñadas por un atacante para reducir el nivel de confianza de la clasificación correcta, en especial en escenarios de alta importancia.
El atacante inserta ruido aleatoriamente en los datos de origen que se están clasificando para reducir la probabilidad de que en el futuro se use la clasificación correcta, con lo que se reduce la inteligencia del modelo de forma eficaz.
Contaminación de los datos de entrenamiento para forzar la clasificación incorrecta de los puntos de datos seleccionados, lo que da lugar a que un sistema realice o omita acciones específicas.
Identificar las acciones que sus modelos o productos y servicios pueden llevar a cabo y que pudiesen causar daños al cliente en línea o en el dominio físico.
Resumen
Si no se mitigan, los ataques a los sistemas de inteligencia artificial y aprendizaje automático pueden abrirse camino hasta el mundo físico. Cualquier escenario que se pueda encadenar hasta una lesión psicológica o física de los usuarios es un riesgo catastrófico para su producto o servicio. Esto se extiende a la información confidencial sobre los clientes usada para entrenar y diseñar opciones que pueden permitir filtrar esos puntos de datos privados.
Preguntas que se deben formular en una revisión de seguridad
¿Entrena con ejemplos adversarios? ¿Qué impacto tienen en la salida del modelo hacia el dominio físico?
¿Cómo sería el trolling en su producto o servicio? ¿Cómo puede detectarlo y responder ante este?
¿Qué se necesita para que el modelo devuelva un resultado que engañe al servicio y lo lleve a denegar el acceso a usuarios legítimos?
¿Cuál es el impacto si copian o roban su modelo?
¿Se puede usar el modelo para inferir la pertenencia de una persona individual en un grupo determinado o simplemente en los datos de entrenamiento?
¿Es posible que un atacante cause daños a la reputación o a las RR. PP de su producto al forzarlo a realizar acciones específicas?
¿Cómo maneja los datos con formato correcto, pero con un claro sesgo, como el proveniente de trols?
Para cada manera de interactuar con el modelo o consultarlo, ¿se puede interrogar a este método para que divulgue los datos de entrenamiento o la funcionalidad del modelo?
Amenazas y mitigaciones relacionadas en este documento
Inferencia de pertenencia
Inversión del modelo
Robo del modelo
Ataques de ejemplo
Reconstrucción y extracción de datos de entrenamiento al consultar repetidamente el modelo para obtener los resultados de confianza máximos.
Duplicación del propio modelo mismo mediante consultas exhaustivas y asociación de respuestas.
Consulta del modelo de forma que revele que un elemento específico de los datos privados se ha incluido en el conjunto de entrenamiento.
Coche autónomo al que se engaña para omitir las señales de alto o los semáforos.
Bots de conversación manipulados para trolear a usuarios inofensivos
Identificación de todos los orígenes de las dependencias de inteligencia artificial y aprendizaje automático, así como los niveles de presentación de front-end en la cadena de suministro de datos/modelo
Resumen
Muchos ataques a la inteligencia artificial y el aprendizaje automático comienzan con un acceso legítimo a las API con superficie para proporcionar acceso a las consultas a un modelo. Debido a los variados orígenes de datos y a las experiencias de usuario enriquecidas que hay involucradas aquí, el acceso autenticado, pero "inadecuado" (aquí hay un área gris) a los modelos es un riesgo, debido a la capacidad de actuar como capa de presentación sobre un servicio proporcionado por Microsoft.
Preguntas que se deben formular en una revisión de seguridad
¿Qué clientes/socios se autentican para tener acceso a su modelo o a las API de servicio?
- ¿Pueden actuar como capa de presentación encima de su servicio?
- ¿Puede revocar el acceso en caso de peligro?
- ¿Cuál es la estrategia de recuperación en caso de un uso malintencionado del servicio o de las dependencias?
¿Puede un tercero crear una fachada alrededor del modelo para redirigirlo y dañar a Microsoft o a sus clientes?
¿Los clientes le proporcionan datos de entrenamiento directamente?
- ¿Cómo se protegen los datos?
- ¿Qué ocurre si son malintencionados y su servicio es el objetivo?
¿Qué aspecto tiene en este caso un falso positivo? ¿Cuál es el impacto de un falso negativo?
¿Puede medir y hacer un seguimiento de la desviación de las tasas de verdadero positivo frente a falso positivo en varios modelos?
¿Qué tipo de datos de telemetría necesita para demostrar la confiabilidad de la salida del modelo a los clientes?
Identifique todas las dependencias de terceros en la cadena de suministro de datos de entrenamiento/aprendizaje automático, no solo el software de código abierto, sino también los proveedores de datos.
- ¿Por qué los usa y cómo comprueba su confiabilidad?
¿Usa modelos pregenerados de entidades externas o envía los datos de entrenamiento a proveedores de MLaaS externos?
Haga un inventario de noticias sobre ataques a productos o servicios similares. En el entendido de muchas amenazas a la inteligencia artificial y el aprendizaje automático se transfieren entre tipos de modelos, ¿qué impacto tendrían estos ataques en sus propios productos?
Amenazas y mitigaciones relacionadas en este documento
Reprogramación de la red neuronal
Ejemplos adversarios en el dominio físico
Proveedor de aprendizaje automático malintencionado que recupera datos de entrenamiento
Ataque de la cadena de suministro de aprendizaje automático
Modelo de puerta trasera
Dependencias específicas de aprendizaje automático en peligro
Ataques de ejemplo
Un proveedor de MLaaS malintencionado introduce troyanos en el modelo con una omisión específica.
Un cliente adversario detecta una vulnerabilidad en una dependencia de OSS común que usted usa, carga datos de entrenamiento diseñado para poner en peligro su servicio.
Un socio inescrupuloso usa las API de reconocimiento facial y crea una capa de presentación sobre su servicio para producir deepfakes.
Amenazas específicas de inteligencia artificial y aprendizaje automático y sus mitigaciones
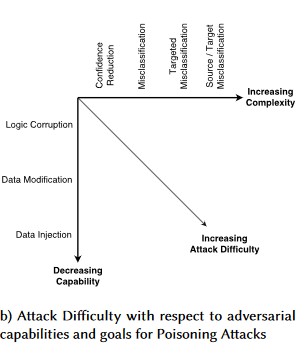
#1: perturbación adversaria
Descripción
En los ataques de estilo perturbación, el atacante modifica de manera furtiva la consulta para obtener una respuesta deseada de un modelo implementado en producción [1]. Se trata de una infracción de la integridad de entrada del modelo, que conduce a ataques al estilo de las pruebas de vulnerabilidad ante datos aleatorios o inesperados, donde el resultado final no es necesariamente una infracción de acceso ni elevación de privilegios (EOP), sino que pone en peligro el rendimiento de clasificación del modelo. Esto también puede manifestarse en forma de trols que usen ciertas palabras de destino de forma que la inteligencia artificial las prohíba, denegando así el servicio a los usuarios legítimos con un nombre que coincida con una palabra "prohibida".
 [24]
[24]
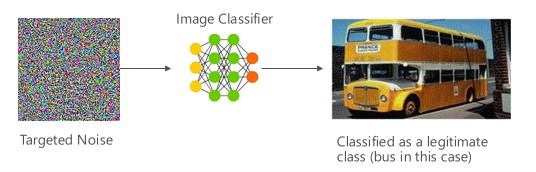
Variante #1a: clasificación incorrecta dirigida
En este caso, los atacantes generan una muestra que no está en la clase de entrada del clasificador de destino, pero logra que el modelo la clasifique como esa clase de entrada determinada. A la vista de una persona, la muestra adversaria puede aparecer como ruido aleatorio, pero los atacantes tienen algún conocimiento del sistema de aprendizaje automático de destino para generar un ruido blanco que no es aleatorio, pero que aprovecha algunos aspectos específicos del modelo de destino. El adversario proporciona una muestra de entrada que no es una muestra legítima, pero el sistema de destino la clasifica como una clase legítima.
Ejemplos
 [6]
[6]
Mitigaciones
Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training [19]: los autores proponen HCNN (vecino próximo de alta confianza), un marco que combina la información de confianza y la búsqueda del vecino más próximo para reforzar la solidez adversaria de un modelo base. Esto puede ayudar a distinguir entre las predicciones de modelo correctas e incorrectas en el vecindario de un punto muestreado a partir de la distribución de entrenamiento subyacente.
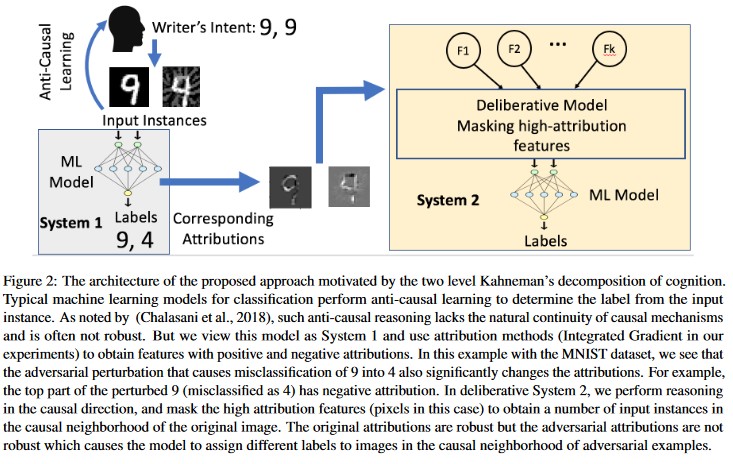
Attribution-driven Causal Analysis [20]: los autores estudian la conexión entre la resistencia a las perturbaciones adversarias y la explicación basada en atribuciones de las decisiones individuales generadas por los modelos de Machine Learning. Informan de que las entradas adversarias no son sólidas en el espacio de las atribuciones, es decir, que enmascarar algunas características con altas atribuciones lleva a cambiar la indecisión del modelo de Machine Learning en los ejemplos adversarios. Por el contrario, las entradas naturales son sólidas en el espacio de las atribuciones.
 [20]
[20]
Estos enfoques pueden hacer que los modelos de Machine Learning sean más resistentes a los ataques adversarios, ya que engañar a este sistema cognitivo de dos niveles exige no solo atacar al modelo original, sino también asegurarse de que la atribución generada para el ejemplo adversario sea similar a los ejemplos originales. Ambos sistemas deben estar en peligro simultáneamente para que un ataque adversario eficaz.
Paralelos tradicionales
Elevación remota de privilegios dado que el atacante está en el control del modelo
Gravedad
Crítico
Variante #1b: clasificación incorrecta de origen o destino
Esto se caracteriza como un intento por parte de un atacante de obtener un modelo para devolver su etiqueta deseada para una entrada determinada. Normalmente, esto obliga a un modelo a devolver un falso positivo o falso negativo. El resultado final es una adquisición sutil de la precisión de clasificación del modelo, por lo que un atacante puede inducir omisiones específicas a su voluntad.
Aunque este ataque tiene un impacto negativo significativo en la precisión de clasificación, también puede llevar más tiempo en realizarse dado que un adversario no solo debe manipular los datos de origen para que ya no se etiqueten correctamente, sino que también se etiqueten específicamente con la etiqueta fraudulenta deseada. Estos ataques suelen implicar varios pasos/intentos para forzar la clasificación incorrecta [3]. Si el modelo es susceptible a ataques de aprendizaje por transferencia que fuercen una clasificación incorrecta, es posible que no se pueda distinguir una superficie de tráfico del atacante, ya que los ataques de sondeo se pueden realizar sin conexión.
Ejemplos
Forzar la clasificación de correos electrónicos inofensivos como correo no deseado o provocar que un ejemplo malintencionado no se detecte. También se conocen como ataques de mimetismo o evasión del modelo.
Mitigaciones
Acciones de detección reactivas/defensivas
- Implemente un umbral de tiempo mínimo entre las llamadas a la API que proporcionan los resultados de clasificación. Esto ralentiza las pruebas de ataques de varios pasos, ya que aumenta la cantidad total de tiempo necesario para encontrar una perturbación correcta.
Acciones proactivas/protectivas
Feature Denoising for Improving Adversarial Robustness [22]: los autores desarrollan una nueva arquitectura de red que aumenta la solidez adversaria mediante la eliminación de ruido de las características. En concreto, las redes contienen bloques que eliminan el ruido de las características a través de medios no locales u otros filtros; todas las redes se entrenan de un extremo a otro. Cuando se combina con el entrenamiento adversario, las redes de eliminación de ruido de las características mejoran sustancialmente el estado de la robustez adversaria en los entornos de ataque tanto de caja blanca como de caja negra.
Entrenamiento adversario y regularización: entrene con ejemplos adversarios conocidos para generar resistencia y solidez contra las entradas malintencionadas. Esto también se puede considerar como una forma de regularización, que penaliza la norma de los degradados de entrada y uniformiza la función de predicción del clasificador (aumentando el margen de entrada). Esto incluye las clasificaciones correctas con tasas de confianza más bajas.
Invierta en el desarrollo de la clasificación monotónica con la selección de características monotónicas. Esto garantiza que el adversario no podrá eludir el clasificador simplemente rellenando características de la clase negativa [13].
La compactación de características [18] se puede usar para endurecer los modelos de DNN mediante la detección de ejemplos adversarios. Reduce el espacio de búsqueda disponible para un adversario mediante la combinación de muestras que corresponden a muchos vectores de características diferentes del espacio original en una sola muestra. Al comparar la predicción de un modelo de DNN en la entrada original con la de la entrada compactada, la compactación de características puede ayudar a detectar ejemplos adversarios. Si las muestras originales y comprimidas producen salidas significativamente diferentes del modelo, es probable que la entrada sea adversaria. Al medir el desacuerdo entre las predicciones y seleccionar un valor de umbral, el sistema puede generar la predicción correcta para ejemplos legítimos y rechazar entradas adversarias.

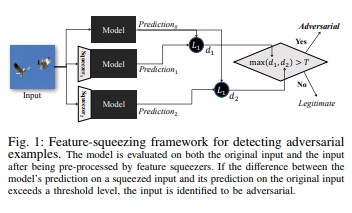 [18]
[18]Certified Defenses against Adversarial Examples [22]: los autores proponen un método basado en una flexibilización semidefinida que genera un certificado que, para una red determinada y una entrada de prueba, ningún ataque puede forzar al error a que supere un determinado valor. En segundo lugar, dado que este certificado es diferenciable, los autores lo optimizan conjuntamente con los parámetros de red, lo que proporciona un regularizador adaptable que fomenta la solidez contra todos los ataques.
Acciones de respuesta
- Emita alertas sobre los resultados de clasificación con varianza alta entre clasificadores, en especial si procede de un solo usuario o de un grupo pequeño de usuarios.
Paralelos tradicionales
Elevación remota de privilegios
Gravedad
Crítico
Variante #1c: clasificación incorrecta aleatoria
Esta es una variación especial en la que la clasificación de destino del atacante puede ser cualquier cosa que no sea la clasificación de origen legítima. En general, el ataque involucra la inserción de ruido aleatoriamente en los datos de origen que se están clasificando para reducir la probabilidad de que en el futuro se use la clasificación correcta [3].
Ejemplos
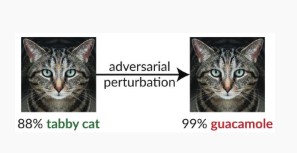
Mitigaciones
Igual que la variante 1a.
Paralelos tradicionales
Denegación de servicio no persistente
Gravedad
Importante
Variante #1d: reducción de la confianza
Un atacante puede diseñar entradas para reducir el nivel de confianza de la clasificación correcta, en especial en escenarios de alta importancia. También puede adoptar la forma de un gran número de falsos positivos destinados a sobrecargar a los administradores o a los sistemas de supervisión con alertas fraudulentas que no se distinguen de las alertas legítimas [3].
Ejemplos

Mitigaciones
- Además de las acciones descritas en la variante #1a, se puede emplear la limitación de eventos para reducir el volumen de las alertas de un único origen.
Paralelos tradicionales
Denegación de servicio no persistente
Gravedad
Importante
#2a: envenenamiento de datos dirigido
Descripción
El objetivo del atacante es contaminar el modelo de la máquina generado en la fase de entrenamiento, de modo que las predicciones de los nuevos datos se modifiquen en la fase de prueba [1]. En los ataques de envenenamiento dirigidos, el atacante desea clasificar erróneamente ejemplos específicos para que se tomen u omitan acciones específicas.
Ejemplos
Envío de software antivirus como malware para forzar su clasificación incorrecta como malintencionada y eliminar el uso del software antivirus dirigido en los sistemas cliente.
Mitigaciones
Defina sensores de anomalías para examinar la distribución de datos de forma diaria y alertar en caso de haber variaciones.
- Mida la variación de los datos de entrenamiento a diario, datos de telemetría para sesgo/desfase.
Validación de entradas, tanto saneamiento como comprobación de integridad.
El envenenamiento inyecta muestras de entrenamiento no relevantes. Dos estrategias principales para contrarrestar esta amenaza:
- Saneamiento/validación de datos: quite las muestras de envenenamiento de los datos de entrenamiento - Bagging para combatir ataques de envenenamiento [14]
- Defensa de rechazo ante impacto negativo (RONI) [15]
- Aprendizaje sólido: elija algoritmos de aprendizaje que sean sólidos en presencia de muestras de envenenamiento.
- Uno de estos enfoques se describe en [21], donde los autores abordan el problema del envenenamiento de los datos en dos pasos: 1) introducción de un nuevo método de factorización sólido de matriz para recuperar el subespacio verdadero y 2) una nueva regresión sólida de componentes principales para eliminar instancias adversarias en función de la base recuperada en el paso (1). Caracterizan las condiciones necesarias y suficientes para recuperar correctamente el subespacio verdadero y presentar un límite en la pérdida de predicción esperada en comparación con la verdad.
Paralelos tradicionales
Host con troyano en el que el atacante persiste en la red. Los datos de entrenamiento o de configuración están en peligro y se infieren o son de confianza para la creación del modelo.
Gravedad
Crítico
#2b: envenenamiento de datos indiscriminado
Descripción
El objetivo es estropear la calidad/integridad del conjunto de datos atacado. Muchos conjuntos de datos son públicos, no son de confianza o no son mantenidos, lo que genera preocupaciones adicionales en cuanto a la capacidad de detectar tales infracciones de integridad de datos en primer lugar. El entrenamiento con datos que no se sabe que se han visto comprometidos es una situación de garbage-in/garbage-out. Una vez detectada, la evaluación debe determinar el alcance de los datos que se han infringido y que deben ponerse en cuarentena/reentrenarse.
Ejemplos
Una empresa aprovecha un sitio web conocido y de confianza de datos de futuros del petróleo para entrenar sus modelos. Posteriormente, el sitio web del proveedor de datos es puesto en peligro a través de un ataque por inyección de código SQL. El atacante puede envenenar el conjunto de datos a su antojo, y el modelo que se está entrenando no tiene ninguna idea de que los datos están dañados.
Mitigaciones
Igual que la variante 2a.
Paralelos tradicionales
Denegación de servicio autenticado contra un recurso de gran valor
Gravedad
Importante
#3: ataques de inversión del modelo
Descripción
Las características privadas que se usan en los modelos de Machine Learning se pueden recuperar [1]. Esto incluye reconstruir los datos de entrenamiento privados a los que el atacante no tiene acceso. También se conocen como ataques hill climbing o de ascenso de colinas en la comunidad biométrica [16, 17], se logra buscando la entrada que maximiza el nivel de confianza devuelto, sujeto a la clasificación que coincide con el destino [4].
Ejemplos
 [4]
[4]
Mitigaciones
Las interfaces a los modelos entrenados a partir de datos confidenciales necesitan un control de acceso seguro.
Límite la tasa de consultas permitidas por modelo.
Implemente las puertas entre los usuarios o autores de llamada y el modelo real mediante la validación de entradas en todas las consultas propuestas, rechazando todo lo que no cumpla con la definición del modelo de corrección de entrada, y devolviendo solo la cantidad mínima de información necesaria para ser útil.
Paralelos tradicionales
Divulgación de información dirigida encubierta
Gravedad
Es Importante de manera predeterminada según la barra de errores estándar de SDL, pero si se extraen datos confidenciales o de identificación personal la elevarían a Crítico.
#4: ataque de inferencia de pertenencia
Descripción
El atacante puede establecer si un registro de datos determinado formaba parte del conjunto de datos de entrenamiento del modelo o no [1]. Los investigadores pudieron predecir el procedimiento principal de un paciente (por ejemplo: la cirugía a la que se sometió el paciente) en función de los atributos (por ejemplo: edad, sexo, hospital) [1].
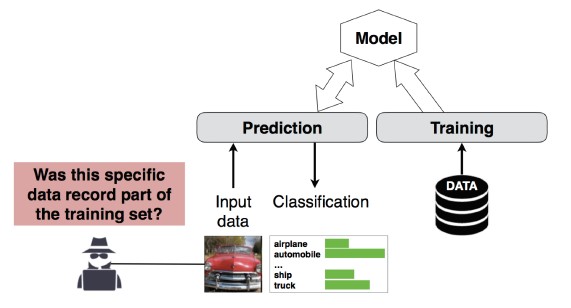 [12]
[12]
Mitigaciones
Los documentos de investigación que demuestran la viabilidad de este ataque indican que la privacidad diferencial [4, 9] sería una mitigación efectiva. Todavía se trata de un campo incipiente en Microsoft, e Ingeniería de seguridad de AETHER recomienda acumular experiencia con inversiones en investigación en este espacio. Esta investigación tendría que enumerar las funcionalidades de privacidad diferencial y evaluar su eficacia práctica como medidas de mitigación y, a continuación, diseñar formas para que estas defensas se hereden de forma transparente en nuestras plataformas de servicios en línea, de forma similar a la que la compilación de código en Visual Studio proporciona protecciones de seguridad activadas de manera predeterminada que son transparentes para el desarrollador y los usuarios.
El uso de la dilución de neuronas (neuron dropout) y el apilamiento de modelos pueden ser mitigaciones eficaces en cierta medida. El uso de la dilución de neuronas no solo aumenta la resistencia de una red neuronal frente a este ataque, sino que también aumenta el rendimiento del modelo [4].
Paralelos tradicionales
Privacidad de los datos. Se están realizando inferencias sobre la inclusión de un punto de datos en el conjunto de entrenamiento, pero sin que se divulguen los propios datos de entrenamiento.
Gravedad
Se trata de un problema de privacidad, no de un problema de seguridad. Se aborda en la guía de modelado de amenazas porque los dominios se superponen, pero toda respuesta al respecto se basaría en la privacidad, no en la seguridad.
#5: robo del modelo
Descripción
Los atacantes recrean el modelo subyacente mediante una consulta legítima al modelo. La funcionalidad del nuevo modelo es la misma que la del modelo subyacente [1]. Una vez que se recrea el modelo, se puede invertir para recuperar información de características o hacer inferencias en los datos de entrenamiento.
Solución de ecuaciones: Para un modelo que devuelve probabilidades de clase a través de la salida de una API, un atacante puede crear consultas para determinar las variables desconocidas de un modelo.
Búsqueda de rutas: Un ataque que aprovecha las peculiaridades de una API para extraer las "decisiones" tomadas por un árbol al clasificar una entrada [7].
Ataque de transferibilidad: Un adversario puede entrenar un modelo local —posiblemente mediante la emisión de consultas de predicción al modelo de destino— y usarlo para crear ejemplos adversarios que se transfieran al modelo de destino [8]. Si se extrae su modelo y se descubre que es vulnerable a un tipo de entrada adversaria, el atacante que ha extraído una copia del modelo puede desarrollar completamente sin conexión los nuevos ataques contra el modelo implementado en producción.
Ejemplos
En los entornos donde un modelo de aprendizaje automático se use para detectar comportamientos adversarios, como la identificación de correo no deseado, la clasificación de malware y la detección de anomalías de red, la extracción del modelo puede facilitar ataques de evasión [7].
Mitigaciones
Acciones proactivas/protectivas
Minimice u ofusque los detalles devueltos en las API de predicción, a la vez que se mantiene su utilidad en las aplicaciones "honesta" [7].
Defina una consulta bien formada para las entradas del modelo y solo devuelva resultados en respuesta a entradas completas y bien formadas que coincidan con ese formato.
Devuelva valores de confianza redondeados. La mayoría de los autores de llamada legítimos no necesitan varios lugares decimales de precisión.
Paralelos tradicionales
Alteración sin autenticar y de solo lectura de datos del sistema, divulgación de información de alto valor dirigida.
Gravedad
Importante en los modelos que afectan a la seguridad, moderada en caso contrario
#6: reprogramación de la red neuronal
Descripción
Por medio de una consulta diseñada especialmente de un adversario, los sistemas de aprendizaje automático se pueden reprogramar para una tarea que se desvíe de la intención original del creador [1].
Ejemplos
Controles de acceso débiles en una API de reconocimiento facial permite a terceros incorporar aplicaciones diseñadas para perjudicar a los clientes de Microsoft, como un generador de deepfakes.
Mitigaciones
Sólida autenticación mutua cliente<->servidor y control del acceso a las interfaces de modelo.
Eliminación de las cuentas infractoras.
Identifique y aplique un contrato de nivel de servicio para las API. Determine el tiempo de corrección aceptable para un problema una vez que se haya comunicado, y asegúrese de que el problema ya no se reproduzca una vez que el contrato de nivel de servicio expire.
Paralelos tradicionales
Se trata de un escenario de abuso. Es menos probable que abra un incidente de seguridad por esto a que simplemente deshabilite la cuenta del infractor.
Gravedad
De importante a crítico
#7: ejemplo adversario en el dominio físico (bits->átomos)
Descripción
Un ejemplo adversario es una entrada o consulta de una entidad malintencionada, enviada con el único objetivo de confundir al sistema de aprendizaje automático [1].
Ejemplos
Estos ejemplos pueden manifestarse en el dominio físico, por ejemplo, se engaña a un coche autónomo para que no se detenga en una señal de alto debido a un determinado color de luz (la entrada adversaria) que brilla en la señal de alto, lo que obliga al sistema de reconocimiento de imágenes a no seguir viendo la señal de alto como tal.
Paralelos tradicionales
Elevación de privilegios, ejecución remota de código
Mitigaciones
Estos ataques se manifiestan porque no se mitigaron los problemas de la capa de aprendizaje automático (la capa de datos y algoritmos por debajo de la toma de decisiones controlada por inteligencia artificial). Al igual que con cualquier otro software *o* sistema físico, la capa situada debajo del destino siempre se puede atacar a través de vectores tradicionales. Por este motivo, las prácticas de seguridad tradicionales son más importantes que nunca, en especial con la capa de vulnerabilidades sin mitigar (la capa de datos y algoritmo) que se usa entre la inteligencia artificial y el software tradicional.
Gravedad
Crítico
#8: proveedores de ML malintencionados que pueden recuperar datos de entrenamiento
Descripción
Un proveedor malintencionado presenta un algoritmo de puerta trasera, donde se recuperan los datos de entrenamiento privados. Pudieron reconstruir caras y textos, dado el modelo por sí solo.
Paralelos tradicionales
Divulgación de información dirigida
Mitigaciones
Los documentos de investigación que demuestran la viabilidad de este ataque indican que el cifrado homomórfico sería una mitigación efectiva. Se trata de un área con escasa inversión actual en Microsoft, e Ingeniería de seguridad de AETHER recomienda acumular experiencia con inversiones en investigación en este espacio. Esta investigación tendría que enumerar los principios del cifrado homomórfico y evaluar su eficacia práctica como mitigaciones ante proveedores malintencionados de aprendizaje automático como servicio.
Gravedad
Importante si los datos son información de identificación personal, moderada en caso contrario
#9: ataque de la cadena de suministro de ML
Descripción
Debido a la gran cantidad de recursos (datos y cálculos) necesarios para entrenar los algoritmos, la práctica actual consiste en reutilizar los modelos entrenados por grandes corporaciones y modificarlos ligeramente según las tareas en cuestión (por ejemplo: ResNet es un modelo popular de reconocimiento de imágenes de Microsoft). Estos modelos se mantienen en un zoológico de modelos (Caffe hospeda modelos conocidos de reconocimiento de imágenes). En este ataque, el adversario ataca los modelos hospedados en Caffe, con lo que envenena el pozo de donde beben todos los otros usuarios. [1]
Paralelos tradicionales
Riesgo de una dependencia de terceros no relacionada con la seguridad
La tienda de aplicaciones hospeda malware sin saberlo
Mitigaciones
Minimice las dependencias de terceros para los modelos y los datos siempre que sea posible.
Incorpore estas dependencias en el proceso de modelado de amenazas.
Aproveche la autenticación sólida, el control de acceso y el cifrado entre el sistema propio y el de terceros.
Gravedad
Crítico
#10: aprendizaje automático de puerta trasera
Descripción
El proceso de entrenamiento se externaliza a un tercero malintencionado que altera los datos de entrenamiento y ha entregado un modelo troyano que aplica clasificaciones incorrectas intencionadas, como la clasificación de un virus determinado como no malintencionado [1]. Este es un riesgo en escenarios de generación de modelos de aprendizaje automático como servicio.
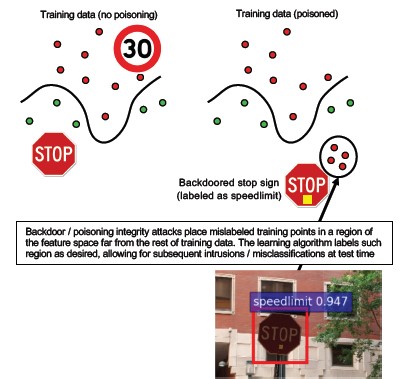 [12]
[12]
Paralelos tradicionales
Riesgo de una dependencia de terceros relacionada con la seguridad
Mecanismo de actualización de software comprometido
Riesgo de la entidad de certificación
Mitigaciones
Acciones de detección reactivas/defensivas
- Los daños ya se han hecho una vez que se ha detectado esta amenaza, por lo que no se puede confiar en el modelo ni en los datos de entrenamiento proporcionados por el proveedor malintencionado.
Acciones proactivas/protectivas
Entrene todos los modelos confidenciales de manera interna.
Catalogue los datos de entrenamiento o asegúrese de que provengan de un tercero de confianza con sólidas prácticas de seguridad.
Modele las amenazas en la interacción entre el proveedor de MLaaS y sus propios sistemas.
Acciones de respuesta
- Las mismas que para el riesgo de una dependencia externa.
Gravedad
Crítico
#11: aprovechamiento de dependencias de software del sistema de ML
Descripción
En este ataque, el atacante NO manipula los algoritmos. En su lugar, aprovecha las vulnerabilidades de software, como los desbordamientos del búfer o el scripting entre sitios [1]. Todavía es más fácil poner en peligro las capas de software debajo de la inteligencia artificial o el aprendizaje automático que atacar directamente la capa de entrenamiento, por lo que las prácticas de mitigación de amenazas de seguridad tradicionales que se detallan en el Ciclo de vida de desarrollo de seguridad son esenciales.
Paralelos tradicionales
Dependencia de software de código abierto comprometida
Vulnerabilidad del servidor web (error de validación de entrada de API, XSS, CSRF)
Mitigaciones
Trabaje con su equipo de seguridad para seguir los procedimientos recomendados del Ciclo de vida de desarrollo de seguridad o de la Garantía de seguridad operativa.
Gravedad
Variable, hasta el nivel crítico según el tipo de vulnerabilidad de software tradicional.
Bibliografía
[1] Failure Modes in Machine Learning, Ram Shankar Siva Kumar, David O’Brien, Kendra Albert, Salome Viljoen y Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Lineage v-team
[3] Adversarial Examples in Deep Learning: Characterization and Divergence, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha, and T. Ristenpart, “Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures”, en Proceedings of the 2015 ACM SIGSAC Conference on Computer and Communications Security (CCS).
[6] Nicolas Papernot & Patrick McDaniel- Adversarial Examples in Machine Learning AIWTB 2017
[7] Stealing Machine Learning Models via Prediction APIs, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, The University of North Carolina at Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] The Space of Transferable Adversarial Examples, Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh y Patrick McDaniel
[9] Understanding Membership Inferences on Well-Generalized Learning Models Yunhui Long1, Vincent Bindschaedler1, Lei Wang2, Diyue Bu2, Xiaofeng Wang2, Haixu Tang2, Carl A. Gunter1 y Kai Chen3,4
[10] Simon-Gabriel et al., Adversarial vulnerability of neural networks increases with input dimension, ArXiv 2018;
[11] Lyu et al., A unified gradient regularization family for adversarial examples, ICDM 2015
[12] Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Adversarially Robust Malware Detection UsingMonotonic Classification Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto y Fabio Roli. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks
[15] An Improved Reject on Negative Impact Defense, Hongjiang Li y Patrick P.K. Chan
[16] Adler. Vulnerabilities in biometric encryption systems. 5th Int’l Conf. AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Ortega-Garcia. On the vulnerability of face verification systems to hill-climbing attacks. Patt. Rec., 2010
[18] Weilin Xu, David Evans, Yanjun Qi. Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks. 2018 Network and Distributed System Security Symposium. 18-21 de febrero.
[19] Reinforcing Adversarial Robustness using Model Confidence Induced by Adversarial Training - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Attribution-driven Causal Analysis for Detection of Adversarial Examples, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Robust Linear Regression Against Training Data Poisoning – Chang Liu et al.
[22] Feature Denoising for Improving Adversarial Robustness, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Certified Defenses against Adversarial Examples - Aditi Raghunathan, Jacob Steinhardt, Percy Liang