Detección de objetos mediante Fast R-CNN
Tabla de contenido
- Resumen
- Configuración
- Ejecutar el ejemplo de toy
- Ejecución de Pascal VOC
- Entrenamiento de CNTK Fast R-CNN en sus propios datos
- Detalles técnicos
- Detalles del algoritmo
Resumen

En este tutorial se describe cómo usar CNTK Fast R-CNN con BrainScript y cntk.exe. R-CNN rápido mediante la API de Python de CNTK se describe aquí.
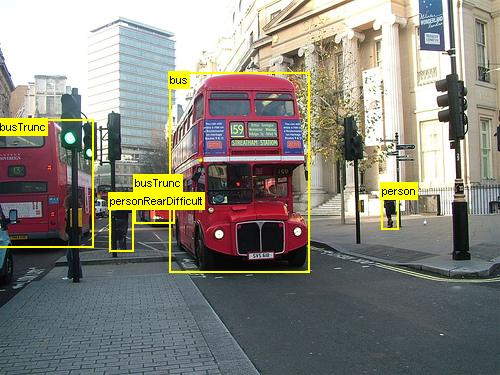
Los anteriores son ejemplos de imágenes y anotaciones de objetos para el conjunto de datos de comestibles (primera imagen) y el conjunto de datos Pascal VOC (segunda imagen) usado en este tutorial.
Fast R-CNN es un algoritmo de detección de objetos propuesto por Ross Girshick en 2015. El documento se acepta en ICCV 2015 y archivado en https://arxiv.org/abs/1504.08083. R-CNN rápido se basa en el trabajo anterior para clasificar eficazmente las propuestas de objetos mediante redes convolucionales profundas. En comparación con el trabajo anterior, Fast R-CNN emplea un esquema de agrupación de regiones de interés que permite reutilizar los cálculos de las capas convolucionales.
Material adicional: un tutorial detallado para la detección de objetos mediante CNTK Fast R-CNN con BrainScript (incluido el entrenamiento opcional de SVM y la publicación del modelo entrenado como API rest) se puede encontrar aquí.
Configurar
Para ejecutar el código en este ejemplo, necesita un entorno de Python de CNTK (consulte aquí para obtener ayuda para la instalación). Además, debe instalar algunos paquetes adicionales. Vaya a la carpeta FastRCNN y ejecute:
pip install -r requirements.txt
Problema conocido: para instalar scikit-learn, es posible que tenga que ejecutarse conda install scikit-learn si usa Anaconda Python.
Necesitará más Scikit-Image y OpenCV para ejecutar estos ejemplos.
Descargue los paquetes de rueda correspondientes e instálelos manualmente. En Linux, puede conda install scikit-image opencv.
Para los usuarios de Windows, visite http://www.lfd.uci.edu/~gohlke/pythonlibs/y descargue:
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
Una vez que descargue los archivos binarios de rueda respectivos, instálelos con:
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[! NOTA: si ve el mensaje No hay módulo denominado pasado al ejecutar los scripts, ejecute pip install future.
En este código de tutorial se supone que usa la versión de 64 bits de Python 3.5 o 3.6, ya que los archivos DLL de Fast R-CNN necesarios en utils están precompilados para esas versiones. Si la tarea requiere el uso de una versión de Python diferente, vuelva a compilar estos archivos DLL en el entorno correcto (consulte a continuación).
En el tutorial se supone además que la carpeta donde reside cntk.exe está en la variable de entorno PATH. (Para agregar la carpeta a la ruta de acceso, puede ejecutar el siguiente comando desde una línea de comandos (suponiendo que la carpeta donde cntk.exe esté en el equipo es C:\src\CNTK\x64\Release): set PATH=C:\src\CNTK\x64\Release;%PATH%).
Archivos binarios compilados previamente para la regresión del rectángulo de selección y la supresión no máxima
La carpeta Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils contiene archivos binarios compilados previamente que son necesarios para ejecutar Fast R-CNN. Las versiones que se encuentran actualmente en el repositorio son Python 3.5 y 3.6, todas 64 bits. Si necesita una versión diferente, puede compilarla siguiendo estos pasos:
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmake- En lugar de
makeejecutarsepython setup.py build_ext --inplacedesde la misma carpeta. En Windows, es posible que tenga que comentar los argumentos de compilación adicionales en lib/setup.py:
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]- En lugar de
copie los archivos binarios y
cython_nmsgeneradoscython_bboxde$FRCN_ROOT/lib/utilsa$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils.
Ejemplo de datos y modelo de línea base
Usamos un modelo AlexNet entrenado previamente como base para el entrenamiento fast-R-CNN. AlexNet previamente entrenado está disponible en https://www.cntk.ai/Models/AlexNet/AlexNet.model. Almacene el modelo en $CNTK_ROOT/PretrainedModels. Para descargar los datos, ejecute
python install_grocery.py
de la Examples/Image/DataSets/Grocery carpeta .
Ejecutar el ejemplo de toy
En el ejemplo de toy entrenamos un modelo CNTK Fast R-CNN para detectar artículos de comestibles en un refrigerador.
Todos los scripts necesarios están en $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript.
Guía rápida
Para ejecutar el ejemplo de toy, asegúrese de que en está establecido "Grocery"en PARAMETERS.pydataset .
- Ejecute
A1_GenerateInputROIs.pypara generar las ROIs de entrada para el entrenamiento y las pruebas. - Ejecute
A2_RunWithBSModel.pypara entrenar y probar mediante cntk.exe y BrainScript. - Ejecute
A3_ParseAndEvaluateOutput.pypara calcular el mAP (precisión media media) del modelo entrenado.
La salida del script A3 debe contener lo siguiente:
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
Para visualizar los cuadros de límite y las etiquetas de predicción que puede ejecutar B3_VisualizeOutputROIs.py (haga clic en las imágenes para ampliar):





Detalles del paso
A1: El script A1_GenerateInputROIs.py genera primero candidatos de ROI para cada imagen mediante la búsqueda selectiva.
A continuación, los almacena en un formato de texto CNTK como entrada para cntk.exe.
Además, se generan los archivos de entrada CNTK necesarios para las imágenes y las etiquetas de verdad básica.
El script genera las siguientes carpetas y archivos en la FastRCNN carpeta :
proc- carpeta raíz para el contenido generado.grocery_2000: contiene todas las carpetas y archivos generados para elgroceryejemplo mediante2000ROIs. Si vuelve a ejecutar con un número diferente de ROIs, el nombre de la carpeta cambiará correspondientemente.rois: contiene las coordenadas de ROI sin procesar para cada imagen almacenada en archivos de texto.cntkFiles: contiene los archivos de entrada CNTK con formato para imágenes (train.txtytest.txt), coordenadas de ROI (xx.rois.txt) y etiquetas de ROI (xx.roilabels.txt) paratrainytest. (A continuación se proporcionan los detalles del formato).
Todos los parámetros se incluyen en PARAMETERS.py, por ejemplo, cambiar cntk_nrRois = 2000 para establecer el número de ROIs que se usan para el entrenamiento y las pruebas. Se describen los parámetros de la sección Parámetros siguientes.
A2: El script A2_RunWithBSModel.py ejecuta cntk mediante cntk.exe y un archivo de configuración brainScript (detalles de configuración).
El modelo entrenado se almacena en la carpeta cntkFiles/Output de la subcarpeta correspondiente proc .
El modelo entrenado se prueba por separado tanto en el conjunto de entrenamiento como en el conjunto de pruebas.
Durante las pruebas de cada imagen y cada ROI correspondiente se predice una etiqueta y se almacena en los archivos test.z y train.z en la cntkFiles carpeta .
A3: El paso de evaluación analiza la salida de CNTK y calcula el mAP comparando los resultados previstos con las anotaciones de verdad básica.
La supresión no máxima se usa para combinar las ROIs superpuestas. Puede establecer el umbral para la supresión no máxima en PARAMETERS.py (detalles).
Scripts adicionales
Hay tres scripts opcionales que puede ejecutar para visualizar y analizar los datos:
B1_VisualizeInputROIs.pyvisualiza las ROIs de entrada candidatas.B2_EvaluateInputROIs.pycalcula la recuperación de las ROIs de verdad básica con respecto a las ROIs candidatas.B3_VisualizeOutputROIs.pyvisualice los cuadros de límite y las etiquetas previstas.
Ejecución de Pascal VOC
Los datos Pascal VOC (PASCAL Visual Object Classes) son un conjunto conocido de imágenes estandarizadas para el reconocimiento de clases de objetos. El entrenamiento o la prueba de CNTK Fast R-CNN en los datos pascales VOC requiere una GPU con al menos 4 GB de RAM. Como alternativa, puede ejecutar mediante la CPU, que sin embargo tardará algún tiempo.
Obtención de los datos de Pascal VOC
Necesita los datos 2007 (trainval y test) y 2012 (trainval), así como las ROis precalutadas usadas en el documento original.
Debe seguir la estructura de carpetas que se describe a continuación.
Los scripts asumen que los datos Pascal residen en $CNTK_ROOT/Examples/Image/DataSets/Pascal.
Si usa una carpeta diferente, establezca pascalDataDir en PARAMETERS.py correspondientemente.
- Descargue y desempaquete los datos trainval de 2012 en
DataSets/Pascal/VOCdevkit2012 - Descargar y desempaquetar los datos trainval de 2007 en
DataSets/Pascal/VOCdevkit2007 - Descargar y desempaquetar los datos de prueba de 2007 en la misma carpeta
DataSets/Pascal/VOCdevkit2007 - Descargar y desempaquetar las ROIs precaladas en
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
La VOCdevkit2007 carpeta debe tener este aspecto (similar para 2012):
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
Ejecución de CNTK en Pascal VOC
Para ejecutarse en los datos de Pascal VOC, asegúrese de que en está establecido "pascal"en PARAMETERS.pydataset .
- Ejecute
A1_GenerateInputROIs.pypara generar los archivos de entrada con formato CNTK para el entrenamiento y las pruebas a partir de los datos de ROI descargados. - Ejecute
A2_RunWithBSModel.pypara entrenar un modelo fast R-CNN y calcular los resultados de las pruebas. - Ejecute
A3_ParseAndEvaluateOutput.pypara calcular el mAP (precisión media media) del modelo entrenado.- Tenga en cuenta que esto está en curso y los resultados son preliminares, ya que estamos entrenando nuevos modelos de línea base.
- Asegúrese de tener la versión más reciente del maestro de CNTK para los archivos fastRCNN/pascal_voc.py y fastRCNN/voc_eval.py para evitar errores de codificación.
Entrenamiento por sus propios datos
Preparación de un conjunto de datos personalizado
Opción 1: Herramienta de etiquetado de objetos visuales (recomendado)
Visual Object Tagging Tool (VOTT) es una herramienta de anotación multiplataforma para etiquetar recursos de vídeo e imagen.

VOTT proporciona las siguientes características:
- Etiquetado asistido por ordenador y seguimiento de objetos en vídeos mediante el algoritmo de seguimiento camshift.
- Exportar etiquetas y recursos al formato Fast-RCNN de CNTK para entrenar un modelo de detección de objetos.
- Ejecutar y validar un modelo de detección de objetos CNTK entrenado en vídeos nuevos para generar modelos más seguros.
Anotación con VOTT:
- Descargar la versión más reciente
- Siga el archivo Léame para ejecutar un trabajo de etiquetado.
- Después de etiquetar etiquetas de exportación en el directorio del conjunto de datos
Opción 2: Usar scripts de anotación
Para entrenar un modelo CNTK Fast R-CNN en su propio conjunto de datos, proporcionamos dos scripts para anotar regiones rectangulares en imágenes y asignar etiquetas a estas regiones.
Los scripts almacenarán las anotaciones en el formato correcto según sea necesario en el primer paso de la ejecución de Fast R-CNN (A1_GenerateInputROIs.py).
En primer lugar, almacene las imágenes en la siguiente estructura de carpetas.
<your_image_folder>/negative: imágenes usadas para el entrenamiento que no contienen ningún objeto<your_image_folder>/positive: imágenes usadas para el entrenamiento que contienen objetos<your_image_folder>/testImages: imágenes usadas para pruebas que contienen objetos
Para las imágenes negativas, no es necesario crear ninguna anotación. Para las otras dos carpetas, use los scripts proporcionados:
- Ejecute
C1_DrawBboxesOnImages.pypara dibujar cuadros de límite en las imágenes.- En el script establecido
imgDir = <your_image_folder>(/positiveo/testImages) antes de ejecutarse. - Agregue anotaciones mediante el cursor del mouse. Una vez anotados todos los objetos de una imagen, al presionar la tecla "n", se escribe el archivo .bboxes.txt y, a continuación, se continúa con la siguiente imagen, "u" deshace (es decir, quita) el último rectángulo y "q" sale de la herramienta de anotación.
- En el script establecido
- Ejecute
C2_AssignLabelsToBboxes.pypara asignar etiquetas a los cuadros de límite.- En el script establecido
imgDir = <your_image_folder>(/positiveo/testImages) antes de ejecutar... - ... y adapte las clases del script para reflejar las categorías de objetos, por ejemplo
classes = ("dog", "cat", "octopus"). - El script carga estos rectángulos anotados manualmente para cada imagen, los muestra uno a uno y pide al usuario que proporcione la clase de objeto haciendo clic en el botón correspondiente a la izquierda de la ventana. Las anotaciones de verdad básica marcadas como "sin decidir" o "excluir" se excluyen completamente del procesamiento adicional.
- En el script establecido
Entrenamiento en un conjunto de datos personalizado
Antes de ejecutar CNTK Fast R-CNN mediante scripts A1-A3, debe agregar el conjunto de datos a PARAMETERS.py:
- Establezca
dataset = "CustomDataset". - Agregue los parámetros del conjunto de datos en la clase
CustomDatasetpython . Para empezar, copie los parámetros desde .GroceryParameters- Adapte las clases para reflejar las categorías de objetos. Siguiendo el ejemplo anterior, sería similar
self.classes = ('__background__', 'dog', 'cat', 'octopus')a . - Establezca
self.imgDir = <your_image_folder>. - Opcionalmente, puede ajustar más parámetros, por ejemplo, para la generación y eliminación de ROI (consulte la sección Parámetros ).
- Adapte las clases para reflejar las categorías de objetos. Siguiendo el ejemplo anterior, sería similar
¡Listo para entrenarse por sus propios datos! (Siga los mismos pasos que para el ejemplo de toy).
Detalles técnicos
Parámetros
Los parámetros principales de PARAMETERS.py son
dataset: qué conjunto de datos se va a usarcntk_nrRois: el número de ROIs que se van a usar para el entrenamiento y las pruebasnmsThreshold- Umbral de supresión no máximo (en intervalo [0,1]). Cuanto menor sean las ROIs más combinadas. Se usa para la evaluación y la visualización.
Todos los parámetros para la generación de ROI, como el ancho y alto máximo y mínimo, etc., se describen en en PARAMETERS.py la clase Parametersde Python . Todos se establecen en un valor predeterminado que es razonable.
Puede sobrescribirlos en la # project-specific parameters sección correspondiente al conjunto de datos que está usando.
Configuración de CNTK
El archivo de configuración de BrainScript de CNTK que se usa para entrenar y probar Fast R-CNN es fastrcnn.cntk.
La parte que construye la red es la BrainScriptNetworkBuilder sección del Train comando :
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
En la primera línea, alexnet previamente entrenado se carga como modelo base. Las dos partes siguientes de la red se clonan: convLayers contiene las capas convolucionales con pesos constantes, es decir, no se entrenan aún más.
fcLayers contiene las capas totalmente conectadas con los pesos previamente entrenados, que se entrenarán aún más.
Los nombres network.featuresde nodo , network.conv5_y etc. se pueden derivar de examinar la salida del registro de la llamada de cntk.exe (contenida en la salida del registro del A2_RunWithBSModel.py script).
La definición de modelo(model (features, rois) = ...) normaliza primero las características restando 114 para cada canal y píxel.
A continuación, las características normalizadas se insertan a través de convLayersROIPooling y, por último, .fcLayers
La forma de salida (ancho:alto) de la capa de agrupación de ROI se establece (6:6) en , ya que es el tamaño de la forma que espera fcLayers el entrenado previamente del modelo AlexNet. La salida de fcLayers se introduce en una capa densa que predice un valor por etiqueta (NumLabels) para cada ROI.
Las seis líneas siguientes definen la entrada:
- una imagen de tamaño 1000 x 1000 x 3 (
$ImageH$:$ImageW$:$ImageC$), - etiquetas de verdad básicas para cada ROI (
$NumLabels$:$NumTrainROIs$) - y cuatro coordenadas por ROI (
4:$NumTrainROIs$) correspondientes a (x, y, w, h), todos relativos con respecto al ancho completo y el alto de la imagen.
z = model (features, rois) alimenta las imágenes de entrada y las ROIs en el modelo de red definido y asigna la salida a z.
Tanto el criterio (CrossEntropyWithSoftmax) como el error (ClassificationError) se especifican con axis = 1 para tener en cuenta el error de predicción por ROI.
A continuación se muestra la sección lector de la configuración de CNTK. Usa tres deserializadores:
ImageDeserializerpara leer los datos de la imagen. Recoge los nombres de archivo de imagen detrain.txt, escala la imagen al ancho y alto deseados, a la vez que conserva la relación de aspecto (relleno de áreas vacías con114) y transpone el tensor para que tenga la forma de entrada correcta.- Una
CNTKTextFormatDeserializerpara leer las coordenadas de ROI detrain.rois.txt. - Segundo
CNTKTextFormatDeserializerpara leer las etiquetas de ROI detrain.roislabels.txt.
Los formatos de archivo de entrada se describen en la sección siguiente.
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
Formato de archivo de entrada CNTK
Hay tres archivos de entrada para CNTK Fast R-CNN correspondientes a los tres deserializadores descritos anteriormente:
train.txtcontiene en cada línea primero un número de secuencia, luego un nombre de archivo de imagen y, por último, un elemento0(que actualmente sigue siendo necesario por motivos heredados de ImageReader).
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(Formato de texto CNTK) contiene en cada línea primero un número de secuencia y, a continuación, el|roisidentificador seguido de una secuencia de números. Estos son grupos de cuatro números correspondientes a (x, y, w, h) de un ROI, todos relativos con respecto al ancho completo y alto de la imagen. Hay un total de 4 * números de rois por línea.
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(Formato de texto CNTK) contiene en cada línea primero un número de secuencia y, a continuación, el|roiLabelsidentificador seguido de una secuencia de números. Se trata de grupos de números de número de etiquetas (cero o uno) por codificación de ROI en la clase de verdad básica en una representación one-hot. Hay un total de números de etiquetas * números de rois por línea.
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
Detalles del algoritmo
Fast R-CNN
Los R-CNN para la detección de objetos fueron presentados por primera vez en 2014 por Ross Girshick et al., y se mostraron para superar los enfoques anteriores de última generación en uno de los principales desafíos de reconocimiento de objetos en el campo: Pascal VOC. Desde entonces, se publicaron dos artículos de seguimiento que contienen importantes mejoras de velocidad: Fast R-CNN y Faster R-CNN.
La idea básica de R-CNN es tomar una red neuronal profunda que se entrenó originalmente para la clasificación de imágenes mediante millones de imágenes anotadas y modificarla con el fin de la detección de objetos. La idea básica del primer documento de R-CNN se ilustra en la figura siguiente (tomada del documento): (1) Dada una imagen de entrada, (2) en un primer paso, se generan propuestas de gran número de regiones. (3) Estas propuestas regionales o regiones de interés (ROIs) se envían de forma independiente a través de la red que genera un vector de valores de punto flotante de 4096 para cada ROI. Por último, (4) se aprende un clasificador que toma la representación de ROI flotante 4096 como entrada y genera una etiqueta y confianza para cada ROI.
Aunque este enfoque funciona bien en términos de precisión, es muy costoso calcular, ya que la red neuronal debe evaluarse para cada ROI. R-CNN rápido aborda este inconveniente mediante la evaluación de la mayoría de la red (para ser específico: las capas de convolución) una sola vez por imagen. Según los autores, esto conduce a una velocidad de 213 veces durante las pruebas y una velocidad de 9 veces durante el entrenamiento sin pérdida de precisión. Esto se logra mediante una capa de agrupación de ROI que proyecta el ROI en el mapa de características convolucionales y realiza la agrupación máxima para generar el tamaño de salida deseado que espera la capa siguiente. En el ejemplo de AlexNet que se usa en este tutorial, la capa de agrupación de ROI se coloca entre la última capa convolucional y la primera capa totalmente conectada (consulte código BrainScript).
La implementación original de Caffe que se usa en los documentos de R-CNN se puede encontrar en GitHub: RCNN, Fast R-CNN y Fast R-CNN. En este tutorial se usa parte del código de estos repositorios, especialmente (pero no exclusivamente) para el entrenamiento de SVM y la evaluación del modelo.
Entrenamiento de SVM frente a NN
Patrick Buehler proporciona instrucciones sobre cómo entrenar una SVM en la salida de R-CNN rápida de CNTK (usando las características 4096 de la última capa totalmente conectada), así como una discusión sobre las ventajas y desventajas aquí.
Búsqueda selectiva
Búsqueda selectiva es un método para buscar un conjunto grande de posibles ubicaciones de objetos en una imagen, independientemente de la clase del objeto real. Funciona agrupando píxeles de imagen en segmentos y, a continuación, realizando clústeres jerárquicos para combinar segmentos del mismo objeto en propuestas de objetos.



Para complementar las ROIs detectadas de la búsqueda selectiva, agregamos ROIs que cubren uniformemente la imagen a diferentes escalas y relaciones de aspecto. La primera imagen muestra una salida de ejemplo de búsqueda selectiva, donde un rectángulo verde visualiza cada ubicación de objeto posible. Las ROIs que son demasiado pequeñas, demasiado grandes, etc. se descartan (segunda imagen) y, por último, las ROIs que cubren uniformemente la imagen se agregan (tercera imagen). Estos rectángulos se usan después como regiones de interés (ROIs) en la canalización de R-CNN.
El objetivo de la generación de ROI es encontrar un pequeño conjunto de ROIs que, sin embargo, cubren estrechamente tantos objetos de la imagen como sea posible. Este cálculo debe ser suficientemente rápido, mientras que al mismo tiempo buscar ubicaciones de objetos en diferentes escalas y relaciones de aspecto. Se mostró que la búsqueda selectiva funciona bien para esta tarea, con una buena precisión para acelerar las ventajas.
NMS (supresión no máxima)
Los métodos de detección de objetos suelen generar varias detecciones que cubren completamente o parcialmente el mismo objeto en una imagen.
Estas ROIs deben combinarse para poder contar objetos y obtener sus ubicaciones exactas en la imagen.
Esto se realiza tradicionalmente mediante una técnica denominada Supresión no máxima (NMS). La versión de NMS que usamos (y que también se usó en las publicaciones de R-CNN) no combina ROIs, sino que intenta identificar qué ROIs mejor cubren las ubicaciones reales de un objeto y descarta todas las demás ROIs. Esto se implementa mediante la selección iterativa del ROI con mayor confianza y la eliminación de todas las demás ROIs que se superponen significativamente a este ROI y se clasifican como de la misma clase. El umbral de la superposición se puede establecer en PARAMETERS.py (detalles).
Resultados de detección antes (primera imagen) y después (segunda imagen) Supresión no máxima:

mAP (media precisión media)
Una vez entrenado, la calidad del modelo se puede medir mediante criterios diferentes, como precisión, recuperación, precisión, área bajo curva, etc. Una métrica común que se usa para el desafío de reconocimiento de objetos Pascal VOC es medir la precisión media (AP) para cada clase. La siguiente descripción de La precisión media se toma de Everingham et. al. La precisión media media (mAP) se calcula tomando el promedio sobre los AP de todas las clases.
Para una tarea y clase determinada, la curva de precisión y recuperación se calcula a partir de la salida clasificada de un método. La recuperación se define como la proporción de todos los ejemplos positivos clasificados por encima de una clasificación determinada. La precisión es la proporción de todos los ejemplos anteriores que son de la clase positiva. El AP resume la forma de la curva de precisión y recuperación, y se define como la precisión media en un conjunto de once niveles de recuperación espaciados igualmente espaciados [0,0,1, . . . ,1]:
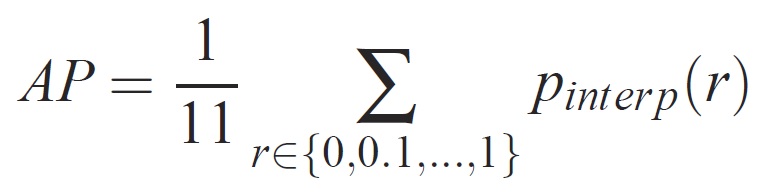
La precisión en cada nivel de recuperación r se interpola tomando la precisión máxima medida para un método para el que la recuperación correspondiente supera r:
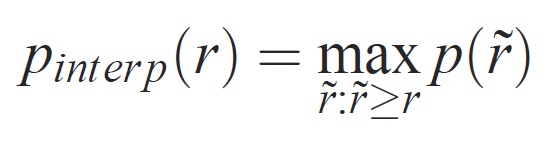
donde p() es la precisión medida en la recuperación COMPARADOR. La intención de interpolar la curva de precisión y recuperación de esta manera es reducir el impacto de las "alternancias" en la curva de precisión y recuperación, causada por pequeñas variaciones en la clasificación de ejemplos. Debe tenerse en cuenta que para obtener una puntuación alta, un método debe tener precisión en todos los niveles de recuperación: esto penaliza los métodos que recuperan solo un subconjunto de ejemplos con alta precisión (por ejemplo, vistas laterales de automóviles).