Migración de StorSimple 1200 a Azure File Sync
StorSimple de la serie 1200 es una aplicación virtual que se ejecuta en un centro de datos local. Los datos de esta aplicación se pueden migrar a un entorno de Azure File Sync. Azure File Sync es el servicio de Azure a largo plazo, estratégico y predeterminado al que se pueden migrar los dispositivos StorSimple. En este artículo se proporcionan los conocimientos básicos y los pasos de migración necesarios para realizar una migración correcta a Azure File Sync.
Nota:
El servicio StorSimple (incluido el Administrador de dispositivos de StorSimple para las series 8000 y 1200 y StorSimple Data Manager) ha llegado al final de la fase de soporte técnico. El final del soporte técnico de StorSimple se publicó en 2019 en las páginas Política del ciclo de vida de Microsoft y Comunicaciones de Azure. Se enviaron notificaciones adicionales por correo electrónico y se publicaron en Azure Portal y en la información general de StorSimple. Póngase en contacto con el servicio de Soporte técnico de Microsoft para obtener más información.
Se aplica a
| Tipo de recurso compartido de archivos | SMB | NFS |
|---|---|---|
| Recursos compartidos de archivos Estándar (GPv2), LRS/ZRS | ||
| Recursos compartidos de archivos Estándar (GPv2), GRS/GZRS | ||
| Recursos compartidos de archivos Premium (FileStorage), LRS/ZRS |
Azure File Sync
Azure File Sync es un servicio en la nube de Microsoft, que se basa en dos componentes principales:
- Sincronización de archivos y nube por niveles.
- Recursos compartidos de archivos como almacenamiento nativo en Azure, a los que se puede acceder a través de varios protocolos, como SMB y FileREST. Un recurso compartido de archivos de Azure es comparable a uno de un servidor de Windows Server, y este último se puede montar de forma nativa como una unidad de red. Admite aspectos importantes de la fidelidad de los archivos, como atributos, permisos y marcas de tiempo. A diferencia de StorSimple, no se requiere ninguna aplicación ni ningún servicio para interpretar los archivos y las carpetas almacenados en la nube. El enfoque ideal y más flexible es almacenar los datos del servidor de archivos de uso general, así como algunos datos de aplicaciones, en la nube.
Este artículo se centra en los pasos de migración. Si quieres obtener más información sobre Azure File Sync, se recomienda consultar los siguientes artículos:
Objetivos de la migración
El objetivo es garantizar la integridad de los datos de producción, así como la disponibilidad. Esta última requiere que el tiempo de inactividad sea mínimo, para ajustarse o solo superar ligeramente las ventanas de mantenimiento regulares.
Ruta de migración de StorSimple 1200 a Azure File Sync
Se requiere un servidor de Windows Server local para ejecutar un agente de Azure File Sync. La edición de Windows Server debe ser como mínimo 2012 R2, pero lo ideal es que sea Windows Server 2019.
Existen numerosas rutas de acceso de migración alternativas y se necesitaría un artículo demasiado largo para documentarlas e ilustrar por qué implican riesgos o desventajas sobre la ruta sugerida como procedimiento recomendado en este artículo.
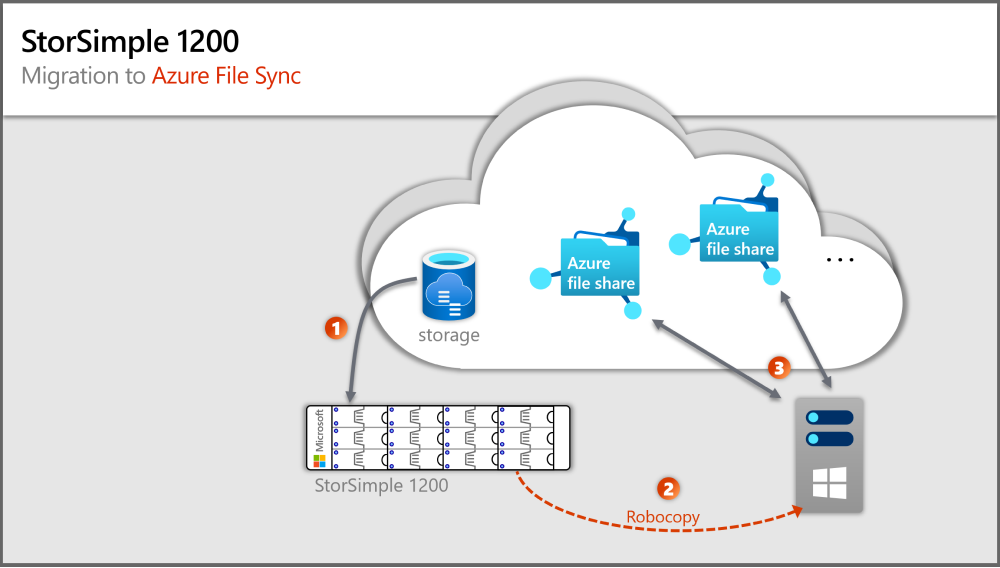
En la imagen anterior se muestran los pasos que corresponden a las secciones de este artículo.
Paso 1: Aprovisionar el almacenamiento y servidor de Windows Server locales
- Crea un servidor de Windows Server 2019 (como mínimo de la edición 2012 R2), como una máquina virtual (VM) o un servidor físico. También se admite un clúster de conmutación por error de Windows Server.
- Aprovisione o agregue almacenamiento de conexión directa (DAS en lugar de NAS, que no se admite). El tamaño del almacenamiento de Windows Server debe ser igual o mayor que el tamaño de la capacidad disponible de la aplicación virtual StorSimple 1200.
Paso 2: Configurar el almacenamiento de Windows Server
En este paso, debe asignar la estructura de almacenamiento de StorSimple (volúmenes y recursos compartidos) a la estructura de almacenamiento de Windows Server. Si tiene previsto realizar cambios en la estructura de almacenamiento, es decir, el número de volúmenes, la asociación de carpetas de datos a volúmenes o la estructura de subcarpetas encima o debajo de los recursos compartidos de SMB/NFS actuales, ahora es el momento de tener en cuenta estos cambios. Cambiar la estructura de archivos y carpetas después de configurar Azure File Sync es un proceso complicado que debe evitarse. En este artículo se supone que realizas una asignación 1:1, por lo que debes tener en cuenta los cambios de asignación al seguir los pasos de este artículo.
- Ninguno de los datos de producción debe acabar en el volumen del sistema de Windows Server. La nube por niveles no se admite en el volumen del sistema. Sin embargo, esta característica es necesaria para la migración, así como para las operaciones continuas como reemplazo de StorSimple.
- Aprovisione el mismo número de volúmenes en el servidor de Windows Server que tiene en la aplicación virtual StorSimple 1200.
- Defina los roles, las características y las configuraciones de Windows Server que necesite. Se recomienda participar en las actualizaciones de Windows Server para mantener el sistema operativo protegido y actualizado. Del mismo modo, se recomienda optar por Microsoft Update para mantener las aplicaciones de Microsoft actualizadas, incluido el agente de Azure File Sync.
- No configures carpetas ni recursos compartidos antes de leer los pasos siguientes.
Paso 3: Implementar el primer recurso de nube de Azure File Sync
Para completar este paso, necesita las credenciales de la suscripción a Azure.
El recurso principal para configurar Azure File Sync se denomina servicio de sincronización de almacenamiento. Se recomienda implementar solo uno para todos los servidores que sincronizan el mismo conjunto de archivos ahora o en el futuro. Solo debe crear varios servicios de sincronización de almacenamiento si tiene distintos conjuntos de servidores que nunca deben intercambiar datos. Por ejemplo, podría tener servidores que nunca deben sincronizar el mismo recurso compartido de archivos de Azure. De lo contrario, el procedimiento recomendado es contar con un único servicio de sincronización de almacenamiento.
Elija una región de Azure para el servicio de sincronización de almacenamiento que esté cerca de su ubicación. Todos los demás recursos de nube se deben implementar en la misma región. Para simplificar el proceso de administración, cree un nuevo grupo de recursos en la suscripción para hospedar los recursos de sincronización y almacenamiento.
Para más información, consulte la sección sobre la implementación del servicio de sincronización de almacenamiento en el artículo sobre la implementación de Azure File Sync. Siga solo esta sección del artículo. En pasos posteriores, tendrá vínculos a otras secciones del artículo.
Paso 4: Conciliar la estructura de carpetas y el volumen local con los recursos de Azure File Sync y los recursos compartidos de archivos de Azure
En este paso, establecerá cuántos recursos compartidos de archivos de Azure se necesitan. Una sola instancia de Windows Server (o clúster) puede sincronizar hasta 30 recursos compartidos de archivos de Azure.
Es posible que tenga más carpetas en los volúmenes que actualmente comparte localmente como recursos compartidos de SMB en sus usuarios y aplicaciones. La manera más sencilla de visualizar este escenario es imaginar un recurso compartido local que asigne 1:1 a un recurso compartido de archivos de Azure. Si tiene un número suficientemente pequeño de recursos compartidos, por debajo de 30 para una sola instancia de Windows Server, se recomienda una asignación 1:1.
Si tiene más de 30 recursos compartidos, a menudo no es necesaria la asignación 1:1 de recursos compartidos locales a un recurso compartido de archivos de Azure. Considere las opciones siguientes.
Agrupación de recursos compartidos
Por ejemplo, si el departamento de RR. HH. tiene 15 recursos compartidos, podría considerar la posibilidad de almacenar todos los datos de RR. HH. en un solo recurso compartido de archivos de Azure. El almacenamiento de varios recursos compartidos locales en un recurso compartido de archivos de Azure no evita que tenga que crear los 15 recursos compartidos de SMB habituales en la instancia local de Windows Server. Solo significa que organiza las carpetas raíz de estos 15 recursos compartidos como subcarpetas en una carpeta común. A continuación, sincronizará esta carpeta común con un recurso compartido de archivos de Azure. De este modo, solo se necesita un único recurso compartido de archivos de Azure en la nube para este grupo de recursos compartidos locales.
Sincronización de volúmenes
Azure File Sync admite la sincronización de la raíz de un volumen con un recurso compartido de archivos de Azure. Si sincroniza la raíz del volumen, todas las subcarpetas y los archivos van al mismo recurso compartido de archivos de Azure.
La sincronización de la raíz del volumen no siempre es la mejor opción. La sincronización de varias ubicaciones ofrece varias ventajas. Por ejemplo, ayuda a disminuir el número de elementos por ámbito de sincronización. Probamos los recursos compartidos de archivos de Azure y Azure File Sync con 100 millones de elementos (archivos y carpetas) por recurso compartido. Pero un procedimiento es intentar mantener el número por debajo de 20 o 30 millones en un solo recurso compartido. La configuración de Azure File Sync con un número de elementos menor no solo es beneficiosa para la sincronización de archivos. Un menor número de elementos también beneficia a escenarios como estos:
- El examen inicial del contenido de la nube puede realizarse más rápido, lo que a su vez reduce la espera de que aparezca el espacio de nombres en un servidor habilitado para Azure File Sync.
- La restauración en la nube a partir de una instantánea de recursos compartidos de archivos de Azure se hará con mayor rapidez.
- La recuperación ante desastres de un servidor local puede acelerarse de forma considerable.
- Los cambios hechos directamente en un recurso compartido de archivos de Azure (sin sincronización) se pueden detectar y sincronizar más rápido.
Sugerencia
Si no está seguro de cuántos archivos y carpetas tiene, consulte la herramienta TreeSize de JAM Software GmbH.
Un enfoque estructurado de una asignación de implementación
Antes de implementar el almacenamiento en la nube en un paso posterior, es importante crear una asignación entre carpetas locales y recursos compartidos de archivos de Azure. Esta asignación informará de cuántos recursos del grupo de sincronización de Azure File Sync se van a aprovisionar y de cuáles van a ser. Un grupo de sincronización está relacionado con el recurso compartido de archivos de Azure y la carpeta de su servidor, y establece una conexión de sincronización.
Para decidir cuántos recursos compartidos de archivos de Azure necesita, revise los límites y procedimientos recomendados siguientes. Eso le va a ayudar a optimizar la asignación.
Un servidor donde está instalado el agente de Azure File Sync puede sincronizarse con hasta 30 recursos compartidos de archivos de Azure.
Un recurso compartido de archivos de Azure se implementa en una cuenta de almacenamiento. Esta disposición hace que la cuenta de almacenamiento sea un destino de escalado para los números de rendimiento, como IOPS y rendimiento.
Preste atención a las limitaciones de IOPS de una cuenta de almacenamiento al implementar recursos compartidos de archivos de Azure. Lo ideal sería asignar recursos compartidos de archivos 1:1 con cuentas de almacenamiento. Pero quizás no sea posible debido a diversos límites y restricciones, tanto de su organización como de Azure. Cuando no sea posible tener un solo recurso compartido de archivos implementado en una cuenta de almacenamiento, tenga en cuenta qué recursos compartidos estarán muy activos y cuales estarán menos activos, con el fin de asegurarse de que los recursos compartidos de archivos más activos no se colocan en la misma cuenta de almacenamiento.
Si tiene previsto mover una aplicación a Azure que usará el recurso compartido de archivos de Azure de forma nativa, es posible que necesite un mayor rendimiento del recurso compartido de archivos de Azure. Si este tipo de uso es una posibilidad, incluso en el futuro, lo mejor es crear un único recurso compartido de archivos de Azure estándar en su propia cuenta de almacenamiento.
Hay un límite de 250 cuentas de almacenamiento por suscripción por cada región de Azure.
Sugerencia
Teniendo en cuenta esta información, suele ser necesario agrupar varias carpetas de nivel superior de sus volúmenes en un nuevo directorio raíz común. Luego se sincroniza este nuevo directorio raíz y todas las carpetas agrupadas en él, en un solo recurso compartido de archivos de Azure. Esta técnica permite permanecer dentro del límite de 30 sincronizaciones de recursos compartidos de archivos de Azure por servidor.
Esta agrupación bajo una raíz común no afecta al acceso a sus datos. Las ACL se mantienen como están. Solo tiene que ajustar algunas rutas de acceso a los recursos compartidos (como las de los recursos compartidos SMB o NFS) que podría haber en las carpetas de servidor locales que ahora han cambiado a una raíz común. No cambia nada más.
Importante
El vector de escala más importante para Azure File Sync es el número de elementos (archivos y carpetas) que tienen que sincronizarse. Para más información, revise los objetivos de escala de Azure File Sync.
Se recomienda mantener bajo el número de elementos por ámbito de sincronización. Ese es un factor importante que se debe tener en cuenta en la asignación de carpetas a recursos compartidos de archivos de Azure. Azure File Sync se prueba con 100 millones elementos (archivos y carpetas) por recurso compartido. Pero a menudo es mejor mantener el número de elementos por debajo de 20 o 30 millones en un solo recurso compartido. Divida el espacio de nombres en varios recursos compartidos si empieza a superar estos números. Puede seguir agrupando varios recursos compartidos locales en el mismo recurso compartido de archivos de Azure, siempre y cuando se mantenga aproximadamente por debajo de estos números. Esto le proporcionará más espacio para crecer.
En una situación tal, es posible que un conjunto de carpetas pueda sincronizarse de forma lógica con el mismo recurso compartido de archivos de Azure (mediante el nuevo enfoque de carpeta raíz común mencionado anteriormente). Pero puede que siga siendo mejor reagrupar carpetas de modo que se sincronicen con dos recursos compartidos de archivos de Azure en lugar de uno. Puede usar este enfoque para mantener equilibrado el número de archivos y carpetas por recurso compartido de archivos en el servidor. También puede dividir los recursos compartidos locales y sincronizarlos entre más servidores locales, lo que agrega la posibilidad de sincronizar 30 recursos compartidos de archivos de Azure más por cada servidor adicional.
Escenarios y consideraciones comunes de sincronización de archivos
| # | Escenario de sincronización | Compatible | Consideraciones (o limitaciones) | Solución (o solución alternativa) |
|---|---|---|---|---|
| 1 | Servidor de archivos con varios discos o volúmenes y varios recursos compartidos en el mismo recurso compartido de archivos de Azure de destino (consolidación) | No | Un recurso compartido de archivos de Azure de destino (punto de conexión en la nube) solo admite la sincronización con un grupo de sincronización. Un grupo de sincronización solo admite un punto de conexión de servidor por servidor registrado. |
1) Comience con la sincronización de un disco (su volumen raíz) para el recurso compartido de archivos de Azure de destino. Empezar con el disco o volumen más grande, ayudará con los requisitos de almacenamiento locales. Configure la nube por niveles para organizar en capas todos los datos en la nube, lo que libera espacio en el disco del servidor de archivos. Mueva datos de otros volúmenes o recursos compartidos al volumen actual que se está sincronizando. Continúe los pasos uno por uno hasta que todos los datos estén en capas en la nube o migrados. 2) Tenga un solo volumen raíz (disco) como destino a la vez. Use la nube por niveles para organizar en capas todos los datos para tener como destino el recurso compartido de archivos de Azure. Quite el punto de conexión de servidor del grupo de sincronización, vuelva a crear el punto de conexión con el siguiente volumen o disco raíz, sincronice y repita el proceso. Nota: Es posible que sea necesario volver a instalar el agente. 3) Se recomienda usar varios recursos compartidos de archivos de Azure de destino (misma o diferente cuenta de almacenamiento en función de los requisitos de rendimiento) |
| 2 | Servidor de archivos con un único volumen y varios recursos compartidos en el mismo recurso compartido de archivos de Azure de destino (consolidación) | Sí | No se pueden tener varios puntos de conexión de servidor por servidor registrado que se sincronicen con el mismo recurso compartido de archivos de Azure de destino (igual que anteriormente) | Sincronice la raíz del volumen que contiene varios recursos compartidos o carpetas de nivel superior. Consulte Concepto de agrupación de recursos compartidos y Sincronización de volúmenes para obtener más información. |
| 3 | Servidor de archivos con varios recursos compartidos o volúmenes en varios recursos compartidos de archivos de Azure en una sola cuenta de almacenamiento (asignación de recursos compartidos de 1:1) | Sí | Una sola instancia de Windows Server (o clúster) puede sincronizar hasta 30 recursos compartidos de archivos de Azure. Una cuenta de almacenamiento es un destino de escalado para el rendimiento. IOPS y el rendimiento se comparten entre recursos compartidos de archivos. Mantenga el número de elementos por grupo de sincronización por debajo de 100 millones de elementos (archivos y carpetas) por recurso compartido. Idealmente, es mejor permanecer por debajo de 20 o 30 millones por recurso compartido. |
1) Use varios grupos de sincronización (número de grupos de sincronización = número de recursos compartidos de archivos de Azure con los que sincronizar). 2) Solo se pueden sincronizar 30 recursos compartidos en este escenario a la vez. Si tiene más de 30 recursos compartidos en ese servidor de archivos, use el concepto de agrupación de recursos compartidos y la sincronización de volúmenes para reducir el número de carpetas raíz o de nivel superior en el origen. 3) Use servidores File Sync adicionales locales y divida o mueva datos a estos servidores para solucionar las limitaciones del servidor Windows de origen. |
| 4 | Servidor de archivos con varios recursos compartidos o volúmenes en varios recursos compartidos de archivos de Azure en una cuenta de almacenamiento diferente (asignación de recursos compartidos de 1:1) | Sí | Una sola instancia de Windows Server (o clúster) puede sincronizar hasta 30 recursos compartidos de archivos de Azure (la misma cuenta de almacenamiento o una diferente). Mantenga el número de elementos por grupo de sincronización por debajo de 100 millones de elementos (archivos y carpetas) por recurso compartido. Idealmente, es mejor permanecer por debajo de 20 o 30 millones por recurso compartido. |
El mismo enfoque que más arriba |
| 5 | Varios servidores de archivos con un único (volumen raíz o recurso compartido) en el mismo recurso compartido de archivos de Azure de destino (consolidación) | No | Un grupo de sincronización no puede usar el punto de conexión en la nube (recurso compartido de archivos de Azure) ya configurado en otro grupo de sincronización. Aunque un grupo de sincronización puede tener puntos de conexión de servidor en distintos servidores de archivos, los archivos no pueden ser distintos. |
Siga las instrucciones del escenario n.º 1 anterior con una consideración adicional sobre tener un único servidor de archivos como destino a la vez. |
Creación de una tabla de asignación

Use la información anterior para decidir cuántos recursos compartidos de archivos de Azure necesita, y qué partes de los datos existentes terminarán en cuál recurso compartido de archivos de Azure.
Cree una tabla para registrar sus ideas, de modo que pueda consultarla cuando sea necesario. La organización es importante, ya que puede ser fácil perder detalles del plan de asignación cuando se aprovisionan muchos recursos de Azure a la vez. Descargue el siguiente archivo de Excel para usarlo como plantilla para ayudar a crear la asignación.

|
Descargue una plantilla de asignación de espacios de nombres. |
Paso 5: Aprovisionar los recursos compartidos de archivos de Azure
Un recurso compartido de archivos de Azure en la nube en una cuenta de almacenamiento de Azure. Aquí se aplica otro nivel de consideraciones relativas al rendimiento.
Si tiene recursos compartidos muy activos (recursos compartidos que usan muchos usuarios o aplicaciones), dos recursos compartidos de archivos de Azure podrían alcanzar el límite de rendimiento de una cuenta de almacenamiento.
Un procedimiento recomendado es implementar cuentas de almacenamiento con un recurso compartido de archivos cada una. Puede agrupar varios recursos compartidos de archivos de Azure en la misma cuenta de almacenamiento si tiene recursos compartidos de archivo o que espera que tengan escasa actividad diaria.
Estas consideraciones se aplican más al acceso directo a la nube (a través de una VM de Azure) que a Azure File Sync. Si tiene pensado usar solo Azure File Sync en estos recursos compartidos, es correcta la agrupación de varios en una sola cuenta de almacenamiento de Azure.
Si ha creado una lista de recursos compartidos, tiene que asignar cada recurso compartido a la cuenta de almacenamiento en la que se encontrará.
En la fase anterior, estableció el número adecuado de recursos compartidos. En este paso, tiene una asignación de cuentas de almacenamiento a recursos compartidos de archivos. Ahora debe implementar el número adecuado de cuentas de almacenamiento de Azure con el número adecuado de recursos compartidos de archivos de Azure en ellas.
Asegúrese de que la región de cada una de las cuentas de almacenamiento sea la misma y coincida con la región del recurso del servicio de sincronización de almacenamiento que ya ha implementado.
Precaución
Si crea un recurso compartido de archivos de Azure con un límite de 100 TiB, ese recurso compartido puede usar solo las opciones de redundancia de almacenamiento con redundancia local o de zona. Tenga en cuenta sus necesidades de redundancia de almacenamiento antes de usar recursos compartidos de archivos de 100 TiB.
Los recursos compartidos de archivos de Azure todavía se crean con un límite de 5 TiB de forma predeterminada. Para crear un recurso compartido de archivos grande, siga los pasos de Creación de un recurso compartido de archivos de Azure.
Otra consideración a la hora de implementar una cuenta de almacenamiento es la redundancia de Azure Storage. Consulte las Opciones de redundancia de Azure Storage.
Los nombres de los recursos también son importantes. Por ejemplo, si agrupa varios recursos compartidos para el Departamento de Recursos Humanos en una cuenta de almacenamiento de Azure, debe asignar el nombre adecuado a la cuenta de almacenamiento. Del mismo modo, al asignar el nombre a los recursos compartidos de archivos de Azure, tiene que usar nombres similares a los que se usan para sus homólogos locales.
Configuración de cuentas de almacenamiento
Hay muchas configuraciones que puede realizar en una cuenta de almacenamiento. La siguiente lista de comprobación se debe usar para las configuraciones de la cuenta de almacenamiento. Por ejemplo, puedes cambiar la configuración de red una vez completada la migración.
- Firewall y redes virtuales: deshabilitado. No configure restricciones de IP ni limite el acceso de la cuenta de almacenamiento a una red virtual específica. El punto de conexión público de la cuenta de almacenamiento se usa durante la migración. Se deben permitir todas las direcciones IP de las máquinas virtuales de Azure. Es mejor configurar las reglas de firewall en la cuenta de almacenamiento después de la migración.
- Puntos de conexión privados: admitido. Puede habilitar puntos de conexión privados, pero el punto de conexión público se usa para la migración y debe permanecer disponible.
Paso 6: Configurar las carpetas de destino de Windows Server
En los pasos anteriores, has tenido en cuenta todos los aspectos que determinarán los componentes de las topologías de sincronización. Ahora es el momento de preparar el servidor para recibir los archivos para la carga.
Crea todas las carpetas, cada una de las cuales se sincronizará con su propio recurso compartido de archivos de Azure. Es importante seguir la estructura de carpetas que ha documentado anteriormente. Si, por ejemplo, has decidido sincronizar varios recursos compartidos de SMB locales en un único recurso compartido de archivos de Azure, deberás colocarlos en una carpeta raíz común en el volumen. Cree esta carpeta raíz de destino en el volumen ahora.
El número de recursos compartidos de archivos de Azure que has aprovisionado debe coincidir con el número de carpetas que has creado en este paso y con el número de volúmenes que quieres sincronizar en el nivel raíz.
Paso 7: Implementar el agente de Azure File Sync
En esta sección se instala el agente de Azure File Sync en una instancia de Windows Server.
En la guía de implementación se explica que es preciso desactivar la configuración de seguridad mejorada de Internet Explorer. Esta medida de seguridad no se puede aplicar con Azure File Sync. Si la desactiva, puede autenticarse en Azure sin ningún problema.
Abra PowerShell. Instale los módulos de PowerShell necesarios mediante los siguientes comandos. Asegúrese de instalar el módulo completo y el proveedor de NuGet cuando se le solicite hacerlo.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
Si tiene algún problema para conectarse a Internet desde el servidor, ahora es el momento de solucionarlo. Azure File Sync usa cualquier conexión de red disponible a Internet. También se admite la exigencia de un servidor proxy para tener acceso a Internet. Ya puede configurar un proxy en toda la máquina, o bien, durante la instalación del agente, especificar un proxy que solo va a usar Azure File Sync.
Si para configurar un proxy debe abrir los firewalls del servidor, es posible que ese enfoque le resulte aceptable. Al final de la instalación del servidor, después de haber completado el registro del servidor, un informe de conectividad de red le mostrará las direcciones URL exactas de los puntos de conexión en Azure, con las que Azure File Sync necesita comunicarse en la región que ha seleccionado. El informe también indica por qué se necesita la comunicación. Puede usar el informe para bloquear los firewalls del servidor en direcciones URL específicas.
También puede adoptar un enfoque más conservador y no abrir totalmente los firewalls. En su lugar puede limitar el servidor para que se comunique con espacios de nombres DNS de nivel superior. Para más información, consulte Configuración del proxy y el firewall de Azure File Sync. Siga sus propios procedimientos recomendados de redes.
Al final del Asistente para la instalación del servidor, se abrirá un Asistente para el registro del servidor. Registre el servidor en el recurso de Azure del servicio de sincronización de almacenamiento anterior.
Estos pasos se describen con más detalle en la guía de implementación, que incluye los módulos de PowerShell que se deben instalar primero: Instalación de agente de Azure File Sync.
Use el agente más reciente. Puede descargarlo del Centro de descarga de Microsoft: Agente de Azure File Sync.
Después de una instalación y un registro del servidor correctos, puede confirmar que ha completado correctamente este paso. Vaya al recurso de Storage Sync Service en Azure Portal. En el menú de la izquierda, vaya a Servidores registrados. Verá que el servidor aparece en esa lista.
Paso 8: Configurar la sincronización
Este paso une todos los recursos y carpetas que ha configurado en la instancia de Windows Server durante los pasos anteriores.
- Inicie sesión en Azure Portal.
- Busque el recurso del servicio de sincronización de almacenamiento.
- Cree un nuevo grupo de sincronización en el recurso del servicio de sincronización de almacenamiento para cada recurso compartido de archivos de Azure. En la terminología de Azure File Sync, el recurso compartido de archivos de Azure se convertirá en punto de conexión de la nube en la topología de sincronización que describe con la creación de un grupo de sincronización. Cuando cree el grupo de sincronización, asígnele un nombre descriptivo para poder reconocer qué conjunto de archivos se sincroniza allí. Asegúrese de hacer referencia al recurso compartido de archivos de Azure con un nombre coincidente.
- Después de haber creado el grupo de sincronización, aparecerá una fila para él en la lista de grupos de sincronización. Seleccione el nombre (un vínculo) para mostrar el contenido del grupo de sincronización. Verá el recurso compartido de archivos de Azure en Puntos de conexión en la nube.
- Busque el botón Agregar punto de conexión de servidor. La carpeta del servidor local que ha aprovisionado se convertirá en la ruta de acceso de este punto de conexión del servidor.
Advertencia
Asegúrese de activar la nube por niveles. Esta acción es necesaria si el servidor local no tiene espacio suficiente para almacenar el tamaño total de los datos en el almacenamiento en la nube de StorSimple. Establece la directiva de niveles temporalmente en un espacio libre del volumen del 99 % y cámbiala a un nivel más razonable una vez completada la migración.
Repite los pasos de creación de grupos de sincronización e incorporación de la carpeta de servidor correspondiente como un punto de conexión de servidor para todos los recursos compartidos de archivos de Azure o las ubicaciones del servidor, que deban configurarse para la sincronización.
Paso 9: Copiar los archivos
El enfoque de migración básico es una ejecución de RoboCopy de la aplicación virtual StorSimple a Windows Server y Azure File Sync a recursos compartidos de archivos de Azure.
Ejecute la primera copia local en la carpeta de destino de Windows Server:
- Identifique la primera ubicación en la aplicación virtual StorSimple.
- Identifique la carpeta coincidente en el servidor de Windows Server, que ya tiene Azure File Sync configurado.
- Inicie la copia con RoboCopy.
El siguiente comando RoboCopy recuperará los archivos del almacenamiento de StorSimple en Azure al almacenamiento de StorSimple local y, a continuación, los moverá a la carpeta de destino de Windows Server. Windows Server los sincronizará con los recursos compartidos de archivos de Azure. A medida que el volumen local de Windows Server se llena, la nube por niveles se iniciará y organizará por niveles los archivos que ya se han sincronizado correctamente. La nube por niveles generará espacio suficiente para continuar con la copia desde la aplicación virtual StorSimple. La nube por niveles realiza comprobaciones cada hora para averiguar qué se ha sincronizado y para liberar espacio en disco para alcanzar el 99 % de espacio libre del volumen.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Modificador | Significado |
|---|---|
/MT:n |
Permite que Robocopy se ejecute en modo multiproceso. El valor predeterminado para n es 8. La cantidad máxima es de 128 subprocesos. Aunque un número elevado de subprocesos contribuye a saturar el ancho de banda disponible, no significa que la migración sea siempre más rápida con más subprocesos. Las pruebas realizadas con Azure Files indican que entre 8 y 20 proporcionan un rendimiento equilibrado para la ejecución de una copia inicial. Las ejecuciones subsiguientes de /MIR se ven afectadas progresivamente por el proceso disponible en comparación con el ancho de banda de red disponible. Para las ejecuciones posteriores, haga coincidir más estrechamente el valor del número de subprocesos con el número de núcleos del procesador y el número de subprocesos por núcleo. Considere si es necesario reservar los núcleos para otras tareas que quizá tenga un servidor de producción. Las pruebas realizadas con Azure Files han demostrado que, con un máximo de 64 subprocesos, se obtiene un buen rendimiento, pero solo si los procesadores pueden mantenerlos activos al mismo tiempo. |
/R:n |
Número máximo de reintentos para un archivo que no se puede copiar en el primer intento. Robocopy prueba n veces antes de determinar que el archivo, definitivamente, no se copia en la ejecución. Para optimizar el rendimiento de la ejecución, elija un valor de dos o tres si cree que hubo problemas de tiempo de espera que causaron errores en el pasado. Esto puede ser más habitual a través de vínculos WAN. Elija no reintentarlo o un valor de uno si cree que el archivo no se pudo copiar porque estaba en uso de forma activa. Volver a intentarlo unos segundos más tarde puede no ser suficiente tiempo para que cambie el estado de “en uso” del archivo. Es posible que los usuarios o aplicaciones que tienen abierto el archivo necesiten más tiempo. En este caso, puede que, si acepta que el archivo no se ha copiado y lo incluye en una ejecución posterior planeada de Robocopy, el archivo se copie finalmente. Esto ayuda a que la ejecución en curso finalice más rápido al no prolongarla con muchos reintentos que, al final, dan lugar a una mayoría de errores de copia porque los archivos siguen abiertos después del tiempo de espera de reintento. |
/W:n |
Especifica el tiempo que espera Robocopy antes de intentar copiar un archivo que no se ha copiado correctamente en el último intento. n es el número de segundos de espera entre reintentos. /W:n a menudo se usa junto con /R:n. |
/B |
Ejecuta Robocopy en el mismo modo que usaría una aplicación de copia de seguridad. Este conmutador permite que Robocopy mueva los archivos para los que el usuario actual no tiene permisos. El modificador de la copia de seguridad depende de la ejecución del comando Robocopy en una consola con privilegios elevados de administrador o en una ventana de PowerShell. Si usa Robocopy para Azure Files, asegúrese de montar el recurso compartido de archivos de Azure con la clave de acceso de la cuenta de almacenamiento en lugar de una identidad de dominio. Si no lo hace, es posible que los mensajes de error no lo lleven intuitivamente a una solución del problema. |
/MIR |
(Reflejar origen en destino). Permite que Robocopy solo tenga que copiar las diferencias entre el origen y el destino. Se copiarán los subdirectorios vacíos. Se copiarán los elementos (archivos o carpetas) que hayan cambiado o no existan en el destino. Los elementos que existan en el destino, pero no en el origen, se purgarán (se eliminarán) del destino. Cuando use este conmutador, haga coincidir exactamente con las estructuras de carpetas de origen y de destino. Coincidencia significa que se copia desde el nivel de carpeta y origen correctos en el nivel de carpeta del destino coincidente. Solo entonces se puede realizar correctamente una copia de "puesta al día". Cuando el origen y el destino no coinciden, el uso de /MIR dará lugar a eliminaciones y nuevas copias a gran escala. |
/IT |
Garantiza que se conserve la fidelidad en ciertos escenarios de reflejo. Por ejemplo, si un archivo experimenta un cambio de ACL y una actualización de atributo entre dos ejecuciones de Robocopy, se marca como oculto. Sin /IT, Robocopy podría omitir el cambio de ACL y no se transferiría a la ubicación de destino. |
/COPY:[copyflags] |
Fidelidad de la copia del archivo. Predeterminado: /COPY:DAT. Marcas de copia: D = datos, A = atributos, T = marcas de tiempo, S = seguridad = ACL de NTFS, O = información del propietario, U = información de aDditoría. No se puede almacenar la información de auditoría en un recurso compartido de archivos de Azure. |
/DCOPY:[copyflags] |
Fidelidad de la copia de directorios. Predeterminado: /DCOPY:DA. Marcas de copia: D = Datos, A = Atributos, T = Marcas de tiempo. |
/NP |
Especifica que no se mostrará el progreso de la copia de cada archivo y carpeta. Mostrar el progreso reduce significativamente el rendimiento de la copia. |
/NFL |
Especifica que los nombres de archivo no se han registrado. Mejora el rendimiento de la copia. |
/NDL |
Especifica que los nombres de directorio no se han registrado. Mejora el rendimiento de la copia. |
/XD |
Especifica los directorios que se excluirán. Cuando ejecute Robocopy en la raíz de un volumen, considere la posibilidad de excluir la carpeta System Volume Information oculta. Si se usa como está previsto, toda la información que contiene es específica del volumen exacto en este sistema exacto y se puede recompilar a petición. Copiar esta información no será útil en la nube ni cuando los datos se vuelvan a copiar en otro volumen Windows. Dejar este contenido atrás no debe considerarse una pérdida de datos. |
/UNILOG:<file name> |
Escribe el estado en el archivo de registro como Unicode. (Sobrescribe el registro existente). |
/L |
Solo para una ejecución de prueba Los archivos solo se mostrarán en la lista. No se copiarán, no se eliminarán y no tendrán marca de tiempo. Por lo general, se usa con /TEE para la salida de la consola. Es posible que las marcas del script de ejemplo, como /NP, /NFL y /NDL, se tengan que quitar para lograr los resultados de la prueba documentados correctamente. |
/LFSM |
Solo para destinos con almacenamiento en niveles. No se admite cuando el destino sea un recurso compartido de SMB remoto. Especifica que Robocopy funciona en "modo de espacio libre bajo". Este conmutador solo es útil para destinos con almacenamiento en capas que pueden quedarse sin capacidad local antes de que Robocopy finalice. Se agregó específicamente para su uso con un destino habilitado de nube por niveles de Azure File Sync. Se puede usar con independencia de Azure File Sync. En este modo, Robocopy se pondrá en pausa siempre que una copia de archivo haga que el espacio disponible del volumen de destino se sitúe por debajo de un valor de "suelo". El formato /LFSM:n de la marca puede especificar este valor. El parámetro n se especifica en la base 2: nKB, nMB o nGB. Si /LFSM se especifica sin ningún valor floor explícito, floor se establece en el 10 por ciento del tamaño del volumen de destino. El modo de espacio libre bajo no es compatible con /MT, /EFSRAW ni /ZB. Se agregó compatibilidad con /B en Windows Server 2022. Consulte la sección Windows Server 2022 y RoboCopy LFSM a continuación para obtener más información, incluidos detalles sobre un error y una solución alternativa relacionados. |
/Z |
Usar con precaución Copia los archivos en modo de reinicio. Este conmutador solo se recomienda en un entorno de red inestable. Reduce significativamente el rendimiento de la copia debido al registro adicional. |
/ZB |
Usar con precaución Usa el modo de reinicio. Si se deniega el acceso, esta opción utiliza el modo de copia de seguridad. Esta opción reduce significativamente el rendimiento de la copia debido a los puntos de control. |
Importante
Se recomienda usar Windows Server 2022. Cuando use Windows Server 2019, asegúrese de que está instalado con el nivel de revisión más reciente o, al menos, la actualización KB5005103 del sistema operativo. Contiene correcciones importantes para determinados escenarios de Robocopy.
Al ejecutar el comando de RoboCopy por primera vez, los usuarios y las aplicaciones siguen accediendo a los archivos y las carpetas de StorSimple, y pueden realizar cambios. Es posible que RoboCopy haya procesado un directorio, pasado al siguiente y, después, un usuario de la ubicación de origen (StorSimple) agregue, cambie o elimine un archivo que ya no se procesará en esta ejecución de RoboCopy actual. Esto es correcto,
La primera ejecución consiste en mover la mayor parte de los datos de nuevo al entorno local, a través de Windows Server, y realizar una copia de seguridad en la nube mediante Azure File Sync. Esta operación puede tardar mucho tiempo, dependiendo de lo siguiente:
- El ancho de banda de descarga.
- La velocidad de recuperación del servicio en la nube de StorSimple.
- El ancho de banda de carga.
- El número de elementos (archivos y carpetas) que debe procesar cada servicio.
Una vez completada la ejecución inicial, vuelva a ejecutar el comando.
La segunda vez se completará más rápido, ya que solo necesita transportar los cambios posteriores a la última ejecución. Es probable que estos cambios ya sean locales para StorSimple, porque son recientes. Esto reduce aún más el tiempo, ya que se reduce la necesidad de la recuperación de la nube. Durante esta segunda ejecución, todavía se pueden acumular nuevos cambios.
Repite este proceso hasta que consideres que la cantidad de tiempo que tarda en completarse es un tiempo de inactividad aceptable.
Cuando consideres el tiempo de inactividad aceptable y estés preparado para dejar sin conexión la ubicación de StorSimple, hazlo. Por ejemplo, quita el recurso compartido de SMB para que ningún usuario pueda acceder a la carpeta o realiza cualquier otro paso adecuado que impida que el contenido cambie en esta carpeta en StorSimple.
Ejecute una última ronda de RoboCopy. Recuperarás todos los cambios que puedan haberse omitido. El tiempo necesario para hacer este último paso depende de la velocidad del análisis de RoboCopy. Para realizar un cálculo estimado del tiempo (que equivale al tiempo de inactividad) averigüe cuánto tardó en realizarse la ejecución anterior.
Cree un recurso compartido en la carpeta de Windows Server y, eventualmente, ajuste esta carpeta como destino de la implementación de DFS-N. Asegúrese de establecer los mismos permisos de nivel de recurso compartido que en el recurso compartido de SMB de StorSimple.
Ya has completado la migración de un recurso compartido o un grupo de recursos compartidos a una raíz o un volumen común, en función de la asignación que has hecho previamente.
Puede intentar ejecutar algunas de estas copias en paralelo. Se recomienda procesar el ámbito de un recurso compartido de archivos de Azure a la vez.
Advertencia
Cuando hayas movido todos los datos de tu ubicación de StorSimple a Windows Server y se haya completado la migración: vuelve a todos los grupos de sincronización de Azure Portal y ajusta el valor porcentual de espacio libre en el volumen de la nube por niveles a un valor más adecuado para el uso de la memoria caché, por ejemplo, un 20 %.
La directiva de espacio libre en el volumen de la nube por niveles actúa en un nivel de volumen desde el que se pueden sincronizar varios puntos de conexión de servidor. Si olvidas ajustar el espacio disponible en un punto de conexión del servidor, la sincronización seguirá aplicando la regla más restrictiva e intentará mantener un 99 % de espacio libre en disco, y esto hará que la memoria caché local no funcione según lo previsto. A menos que tu objetivo sea tener solo el espacio de nombres de un volumen que solo contenga datos de archivo a los que se accede con poca frecuencia, deberás ajustar la directiva de espacio libre en cada punto de conexión de servidor.
Solución de problemas
El problema que puede experimentar más probablemente es que el comando de RoboCopy produzca el error "Volumen lleno" en el lado de Windows Server. Si eso ocurre, es probable que la velocidad de descarga sea mejor que la de carga. La nube por niveles actúa una vez cada hora para evacuar el contenido del disco local de Windows Server, que se ha sincronizado.
Permita que el progreso de la sincronización y la nube por niveles liberen espacio en disco. Puede observarlo en el Explorador de archivos en Windows Server.
Cuando Windows Server tenga capacidad suficiente disponible, el problema se resolverá al volver a ejecutar el comando. Si se da esta situación, no se interrumpe nada y puede avanzar con confianza. La única consecuencia es el inconveniente de tener que volver a ejecutar el comando.
También puede experimentar otros problemas de Azure File Sync. Si esto sucede, consulte Guía de solución de problemas de Azure File Sync.
La velocidad y la tasa de éxito de una ejecución determinada de RoboCopy dependerán de varios factores:
- El número de IOPS en el almacenamiento de origen y de destino.
- El ancho de banda de red disponible entre el origen y el destino.
- La capacidad de procesar rápidamente archivos y carpetas en un espacio de nombres.
- El número de cambios entre ejecuciones de RoboCopy.
- el tamaño y el número de archivos que debe copiar
Consideraciones sobre el ancho de banda y el número de IOPS.
En esta categoría, debe tener en cuenta la capacidad del almacenamiento de origen, el almacenamiento de destinoy la red que los conecta. El mayor rendimiento posible viene determinado por el más lento de estos tres componentes. Asegúrese de que la infraestructura de red se haya configurado para admitir las mejores velocidades de transferencia.
Precaución
Aunque es deseable copiar lo más rápido posible, tenga en cuenta el uso de la red local y el dispositivo NAS en otras tareas que suelen ser críticas para la empresa.
Copiar lo más rápido posible podría no ser deseable si existe el riesgo de que la migración acapare los recursos disponibles.
- Tenga en cuenta cuándo es mejor para su entorno hacer migraciones: durante el día, fuera del horario laboral o en los fines de semana.
- Considere también la calidad de servicio de redes en Windows Server para limitar la velocidad de RoboCopy.
- Evite trabajo innecesario a las herramientas de migración.
RoboCopy puede introducir retrasos entre paquetes al especificar el modificador /IPG:n, en donde el valor n se calcula en milisegundos entre los paquetes de RoboCopy. El uso de este modificador puede ayudar a evitar el acaparamiento de los recursos en dispositivos de E/S restringidos y vínculos de red saturados.
/IPG:n no se puede usar para limitar la red a un número exacto de megabits por segundo. En su lugar, use la calidad de servicio de red de Windows Server. RoboCopy se basa íntegramente en el protocolo SMB para todas las necesidades de red. El uso de SMB es el motivo por el que RoboCopy no puede influir en el propio rendimiento de la red, pero puede ralentizar su uso.
Un enfoque similar se aplica a las operaciones de IOPS observadas en el dispositivo NAS. El tamaño del clúster en el volumen de NAS y los tamaños de paquete, entre otros factores, influyen en las IOPS observadas. La introducción de retraso entre paquetes suele ser la manera más fácil de controlar la carga en el dispositivo NAS. Pruebe varios valores, por ejemplo, de 20 milisegundos (n = 20) a múltiplos de ese número. Una vez que introduzca un retraso, podrá valorar si las otras aplicaciones funcionan según lo esperado. Esta estrategia de optimización le permitirá encontrar la velocidad de RoboCopy óptima para su entorno.
Velocidad de procesamiento
RoboCopy recorrerá el espacio de nombres al que se apunta y evaluará cada archivo y carpeta con fines de copia. Los archivos se evaluarán durante una copia inicial y durante las copias de puesta al día. Por ejemplo, ejecuciones repetidas de RoboCopy/MIR en las mismas ubicaciones de almacenamiento de origen y de destino. Estas ejecuciones repetidas son útiles para minimizar el tiempo de inactividad de los usuarios y las aplicaciones, así como para mejorar la tasa de éxito general de los archivos migrados.
A menudo, el ancho de banda suele considerarse como el factor más restrictivo en una migración, algo que puede ser cierto. Pero la posibilidad de enumerar un espacio de nombres puede influir en el tiempo total de copia para espacios de nombres más largos con archivos más pequeños. Tenga en cuenta que copiar 1 TiB de archivos pequeños tardará mucho más que copiar 1 TiB de un número inferior de archivos de mayor tamaño, si se supone que todas las demás variables permanecen iguales. Por lo tanto, es posible que se experimente una transferencia lenta si va a migrar una gran cantidad de archivos pequeños. Este es un comportamiento esperado.
La razón de esta diferencia es la potencia de procesamiento necesaria para recorrer un espacio de nombres. RoboCopy admite copias multiproceso mediante el parámetro /MT:n, donde n indica el número de subprocesos que se van a usar. Por lo tanto, al aprovisionar una máquina específicamente para RoboCopy, tenga en cuenta el número de núcleos de procesador y su relación con el número de subprocesos que proporcionan. Lo más habitual son dos subprocesos por núcleo. El número de núcleos y subprocesos de una máquina es un punto de datos importante para determinar qué valores multiproceso /MT:n se deberían especificar. Tenga en cuenta también cuántos trabajos de RoboCopy tiene previsto ejecutar al mismo tiempo en una máquina determinada.
Un número mayor de subprocesos copiarán nuestro ejemplo de 1 TiB de archivos pequeños considerablemente más rápido que un número menor de subprocesos. Al mismo tiempo, la inversión adicional en recursos en 1 TiB de archivos de más grandes podría no aportar ventajas proporcionales. Un número mayor de subprocesos intentará copiar simultáneamente más archivos grandes a través de la red. Esta actividad de red adicional aumentará la probabilidad de sufrir restricciones asociadas al rendimiento o a las operaciones de IOPS de almacenamiento.
Durante una primera ejecución de RoboCopy en un destino vacío o una ejecución diferencial con una gran cantidad de archivos modificados, es probable que el rendimiento de la red plantee restricciones. Comience con un número elevado de subprocesos para una ejecución inicial. Un alto número de subprocesos, incluso más allá de los subprocesos disponibles actualmente en la máquina, ayuda a saturar el ancho de banda de red disponible. Las ejecuciones /MIR posteriores se verán afectadas progresivamente por el procesamiento de elementos. Menos cambios en una ejecución diferencial significa menos transporte de datos a través de la red. La velocidad ahora depende más de la capacidad de procesar elementos de espacio de nombres que de moverlos a través del vínculo de red. Para las ejecuciones posteriores, haga coincidir el valor del número de subprocesos con el número de núcleos del procesador y el número de subprocesos por núcleo. Considere si es necesario reservar los núcleos para otras tareas que quizá tenga un servidor de producción.
Sugerencia
Regla general: la primera ejecución de RoboCopy, que moverá una gran cantidad de datos de una red de mayor latencia, se beneficia del aprovisionamiento excesivo del número de subprocesos (/MT:n). Las ejecuciones posteriores copiarán menos diferencias y es más probable que se cambie de un rendimiento restringido de red a otro restringido por proceso. En estas circunstancias, a menudo es mejor que el número de subprocesos de robocopy coincida con los subprocesos disponibles realmente en la máquina. El aprovisionamiento excesivo en ese escenario puede generar más cambios de contexto en el procesador, lo que podría ralentizar la copia.
Evitar el trabajo innecesario
Evite cambios a gran escala en el espacio de nombres. Por ejemplo, mover archivos entre directorios, cambiar propiedades a gran escala o cambiar permisos (ACL de NTFS). Los cambios en la ACL en especial pueden tener una importante repercusión, ya que con frecuencia tienen un efecto de cambio en cascada en los archivos de nivel inferior en la jerarquía de carpetas. Entre las consecuencias, cabe destacar las siguientes:
- La ampliación del tiempo de ejecución del trabajo de RoboCopy, ya que será necesario actualizar cada archivo y carpeta a los que afecte un cambio de ACL.
- Es posible que haya que volver a copiar los datos que se migraron anteriormente. Por ejemplo, habrá que copiar más datos si cambian las estructuras de carpetas, aunque los archivos se hubieran copiado anteriormente. Un trabajo de RoboCopy no puede "reproducir" un cambio del espacio de nombres. El siguiente trabajo debe purgar los archivos transportados previamente en la estructura de carpetas antigua y volver a cargar los archivos en la nueva estructura de carpetas.
Otro aspecto importante es usar la herramienta RoboCopy de forma eficaz. Con el script de RoboCopy recomendado, se creará y guardará un archivo de registro de los errores. Es normal que puedan producirse errores de copia. Estos errores suelen hacer que sea necesario ejecutar varias rondas de una herramienta de copia como RoboCopy. Una ejecución inicial, por ejemplo, de un dispositivo NAS a DataBox o de un servidor a un recurso compartido de archivos de Azure. Y una o varias ejecuciones adicionales con el modificador /MIR para identificar los archivos que no se han copiado y volver a intentarlo.
Debe estar preparado para ejecutar varias rondas de RoboCopy en el ámbito de un espacio de nombres determinado. Las sucesivas ejecuciones finalizarán más rápido, ya que tienen menos que copiar, pero cada vez tendrán más restricciones debido a la velocidad de procesamiento del espacio de nombres. Cuando ejecute varias rondas, puede acelerar cada una de ellas si evita que RoboCopy intente copiarlo todo en una misma ejecución. Los siguientes modificadores RoboCopy pueden marcar una diferencia importante:
/R:nn = la frecuencia con la que se vuelve a intentar copiar un archivo con errores/W:nn = el número de segundos que hay que esperar entre reintentos
/R:5 /W:5 es un valor razonable que puede ajustar a su gusto. En este ejemplo, un archivo con errores se intentará volver a copiar cinco veces, con un tiempo de espera de cinco segundos entre un reintento y otro. Si el archivo sigue sin copiarse, el siguiente trabajo de RoboCopy lo volverá a intentar. A menudo, los archivos que generan errores por estar en uso o debido a problemas de tiempo de espera se pueden copiar correctamente de esta manera.
Windows Server 2022 y RoboCopy LFSM
El modificador RoboCopy /LFSM se puede usar para evitar que un trabajo de RoboCopy produzca un error tipo Volumen lleno. RoboCopy se pondrá en pausa siempre que una copia de archivo haga que el espacio disponible del volumen de destino se sitúe por debajo de un valor mínimo.
Use RoboCopy con Windows Server 2022. Solo esta versión de RoboCopy contiene correcciones de errores importantes y características que hacen que el conmutador sea compatible con marcas adicionales necesarias en la mayoría de las migraciones. Por ejemplo, compatibilidad con la marca /B.
/B ejecuta Robocopy en el mismo modo que usaría una aplicación de copia de seguridad. Este conmutador permite que Robocopy mueva los archivos para los que el usuario actual no tiene permisos.
Normalmente, RoboCopy se puede ejecutar en el origen, en el destino o en una tercera máquina.
Importante
Si tiene previsto usar /LFSM, RoboCopy debe ejecutarse en el servidor de Azure File Sync con Windows Server 2022 de destino.
Tenga en cuenta también que, con /LFSM, también debe usar una ruta de acceso local para el destino, no una UNC. Por ejemplo, como ruta de acceso de destino, debe usar E:\NombreDeLaCarpeta en lugar de una ruta de acceso UNC como \\ServerName\NombreDeLaCarpeta.
Precaución
La versión disponible actualmente de RoboCopy en Windows Server 2022 tiene un error que hace que las pausas se incluyan en el recuento de errores por archivo. Aplique la siguiente solución alternativa.
Las marcas recomendadas /R:2 /W:1 aumentan la probabilidad de que se produzca un error en un archivo debido a una pausa /LFSM inducida. En este ejemplo, un archivo que no se copió después de tres pausas porque /LFSM provocó la pausa, hará que RoboCopy produzca un error incorrecto en el archivo. La solución alternativa para esto es usar valores mayores para /R:n y /W:n. Un buen ejemplo es /R:10 /W:1800 (10 reintentos de 30 minutos cada uno). Esto debe dar tiempo al algoritmo de niveles de Azure File Sync para crear espacio en el volumen de destino.
Este error se ha corregido, pero la corrección aún no está disponible públicamente. Compruebe este párrafo en busca de actualizaciones de disponibilidad de la corrección y cómo implementarla.
Nota:
¿Todavía tiene preguntas o ha detectado algún problema?
Estamos aquí para ayudar:
Vínculos pertinentes
Contenido de migración:
Contenido de Azure File Sync: