Uso del conector Flink/Delta
Importante
Azure HDInsight en AKS se retiró el 31 de enero de 2025. Obtenga más información con este anuncio.
Debe migrar las cargas de trabajo a microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo.
Importante
Esta característica está actualmente en versión preliminar. Los Términos de uso complementarios para las versiones preliminares de Microsoft Azure incluyen más términos legales que se aplican a las características de Azure que se encuentran en versión beta, en versión preliminar o, de lo contrario, aún no se han publicado en disponibilidad general. Para obtener información sobre esta versión preliminar específica, consulte información de la versión preliminar de Azure HDInsight en AKS. Para preguntas o sugerencias de características, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
Con Apache Flink y Delta Lake juntos, puede crear una arquitectura confiable y escalable de data lakehouse. El conector Flink/Delta permite escribir datos en tablas Delta con transacciones ACID y un procesamiento de exactamente una vez. Esto significa que los flujos de datos son coherentes y libres de errores, incluso si reinicia la canalización de Flink desde un punto de control. El conector Flink/Delta garantiza que los datos no se pierdan ni se dupliquen y que coincidan con la semántica de Flink.
En este artículo, aprenderán a usar el conector Flink-Delta.
- Lea los datos de la tabla delta.
- Escriba los datos en una tabla delta.
- Consultarlo en Power BI.
¿Qué es el conector Flink/Delta?
Flink/Delta Connector es una biblioteca JVM para leer y escribir datos de aplicaciones de Apache Flink en tablas Delta que usan la biblioteca JVM independiente de Delta. El conector proporciona garantías de entrega exactamente una vez.
Flink/Delta Connector incluye:
DeltaSink para escribir datos de Apache Flink en una tabla Delta. DeltaSource para leer tablas delta mediante Apache Flink.
Apache Flink-Delta Connector incluye:
En función de la versión del conector, puede usarla con las siguientes versiones de Apache Flink:
Connector's version Flink's version
0.4.x (Sink Only) 1.12.0 <= X <= 1.14.5
0.5.0 1.13.0 <= X <= 1.13.6
0.6.0 X >= 1.15.3
0.7.0 X >= 1.16.1 --- We use this in Flink 1.17.0
Prerrequisitos
- Clúster de HDInsight Flink 1.17.0 en AKS
- Flink-Delta Connector 0.7.0
- Uso de MSI para acceder a ADLS Gen2
- IntelliJ para desarrollo
Leer datos de la tabla delta
Delta Source puede funcionar en uno de los dos modos descritos de la manera siguiente.
Modo enlazado: Adecuado para trabajos por lotes, donde queremos leer el contenido de la tabla Delta solo para una versión concreta de la tabla. Cree un origen de este modo mediante la API DeltaSource.forBoundedRowData.
Modo continuo Adecuado para trabajos de streaming, donde queremos comprobar continuamente la tabla Delta para ver los nuevos cambios y versiones. Cree un origen de este modo mediante la API DeltaSource.forContinuousRowData.
Ejemplo: Creación de origen para la tabla Delta, para leer todas las columnas en modo acotado. Adecuado para trabajos por lotes. En este ejemplo se carga la versión más reciente de la tabla.
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.data.RowData;
import org.apache.hadoop.conf.Configuration;
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
Escribir en el receptor delta
Delta Sink actualmente expone las siguientes métricas de Flink:

Creación de receptores para tablas no particionadas
En este ejemplo, se muestra cómo crear un DeltaSink y conectarlo a un org.apache.flink.streaming.api.datastream.DataStreamexistente.
import io.delta.flink.sink.DeltaSink;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
Código completo
Lee datos de una tabla delta y envíalos a otra tabla delta.
package contoso.example;
import io.delta.flink.sink.DeltaSink;
import io.delta.flink.source.DeltaSource;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.types.logical.RowType;
import org.apache.hadoop.conf.Configuration;
public class DeltaSourceExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Define the sink Delta table path
String deltaTablePath_sink = "abfss://container@account_name.dfs.core.windows.net/data/testdelta_output";
// Define the source Delta table path
String deltaTablePath_source = "abfss://container@account_name.dfs.core.windows.net/data/testdelta";
// Define the source Delta table path
RowType rowType = RowType.of(
DataTypes.STRING().getLogicalType(), // Date
DataTypes.STRING().getLogicalType(), // Time
DataTypes.STRING().getLogicalType(), // TargetTemp
DataTypes.STRING().getLogicalType(), // ActualTemp
DataTypes.STRING().getLogicalType(), // System
DataTypes.STRING().getLogicalType(), // SystemAge
DataTypes.STRING().getLogicalType() // BuildingID
);
// Create a bounded Delta source for all columns
DataStream<RowData> deltaStream = createBoundedDeltaSourceAllColumns(env, deltaTablePath_source);
createDeltaSink(deltaStream, deltaTablePath_sink, rowType);
// Execute the Flink job
env.execute("Delta datasource and sink Example");
}
public static DataStream<RowData> createBoundedDeltaSourceAllColumns(
StreamExecutionEnvironment env,
String deltaTablePath) {
DeltaSource<RowData> deltaSource = DeltaSource
.forBoundedRowData(
new Path(deltaTablePath),
new Configuration())
.build();
return env.fromSource(deltaSource, WatermarkStrategy.noWatermarks(), "delta-source");
}
public static DataStream<RowData> createDeltaSink(
DataStream<RowData> stream,
String deltaTablePath,
RowType rowType) {
DeltaSink<RowData> deltaSink = DeltaSink
.forRowData(
new Path(deltaTablePath),
new Configuration(),
rowType)
.build();
stream.sinkTo(deltaSink);
return stream;
}
}
Maven Pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>contoso.example</groupId>
<artifactId>FlinkDeltaDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<hadoop-version>3.3.4</hadoop-version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-standalone_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>io.delta</groupId>
<artifactId>delta-flink</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
Empaquetar el archivo jar y enviarlo al clúster de Flink para ejecutarlo
Cargue el archivo jar en ABFS.

Transmita la información del archivo jar relacionado con el trabajo en el cluster de AppMode.
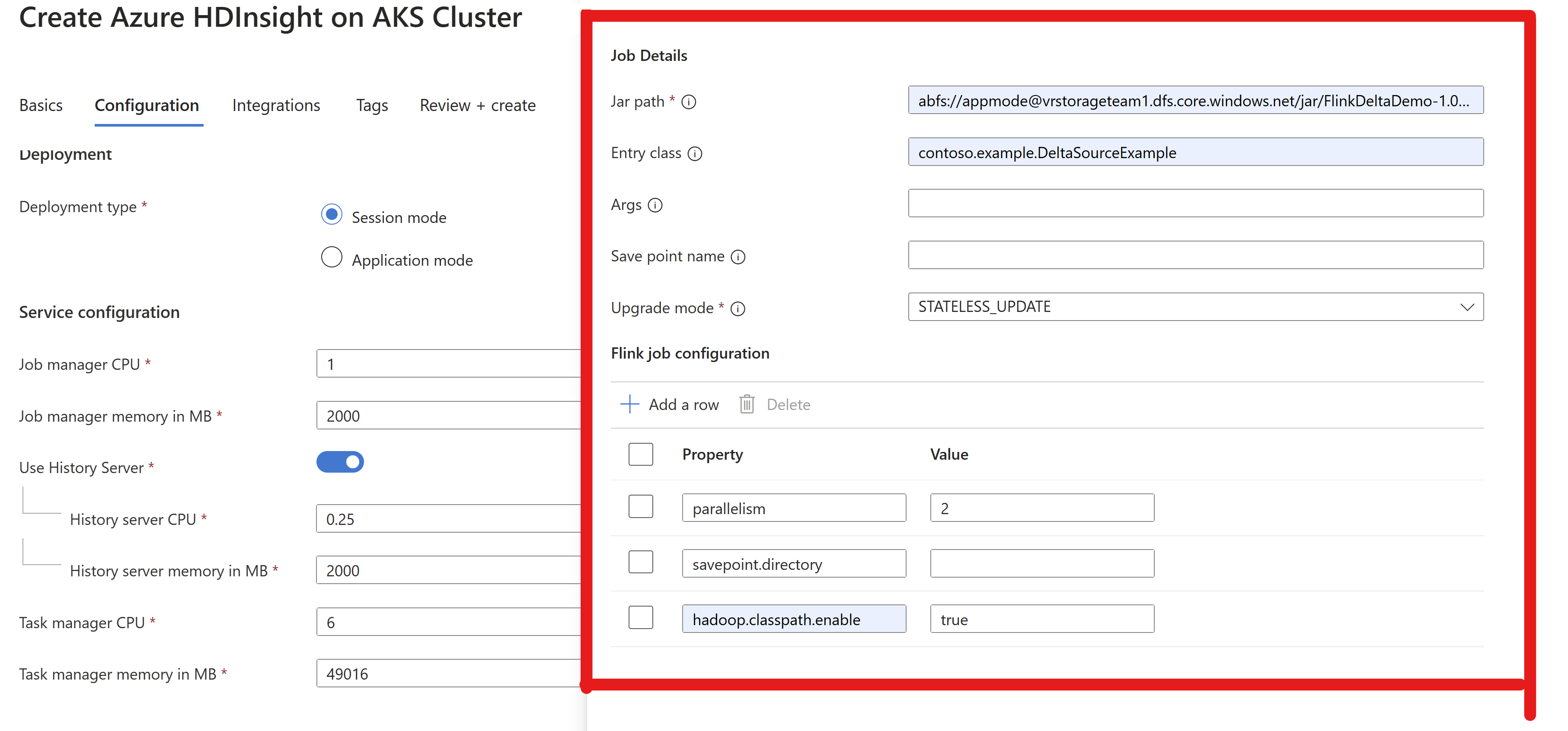
Nota
Habilite siempre
hadoop.classpath.enableal leer y escribir en ADLS.Envíe el clúster; debería poder ver la tarea en la interfaz de usuario de Flink.
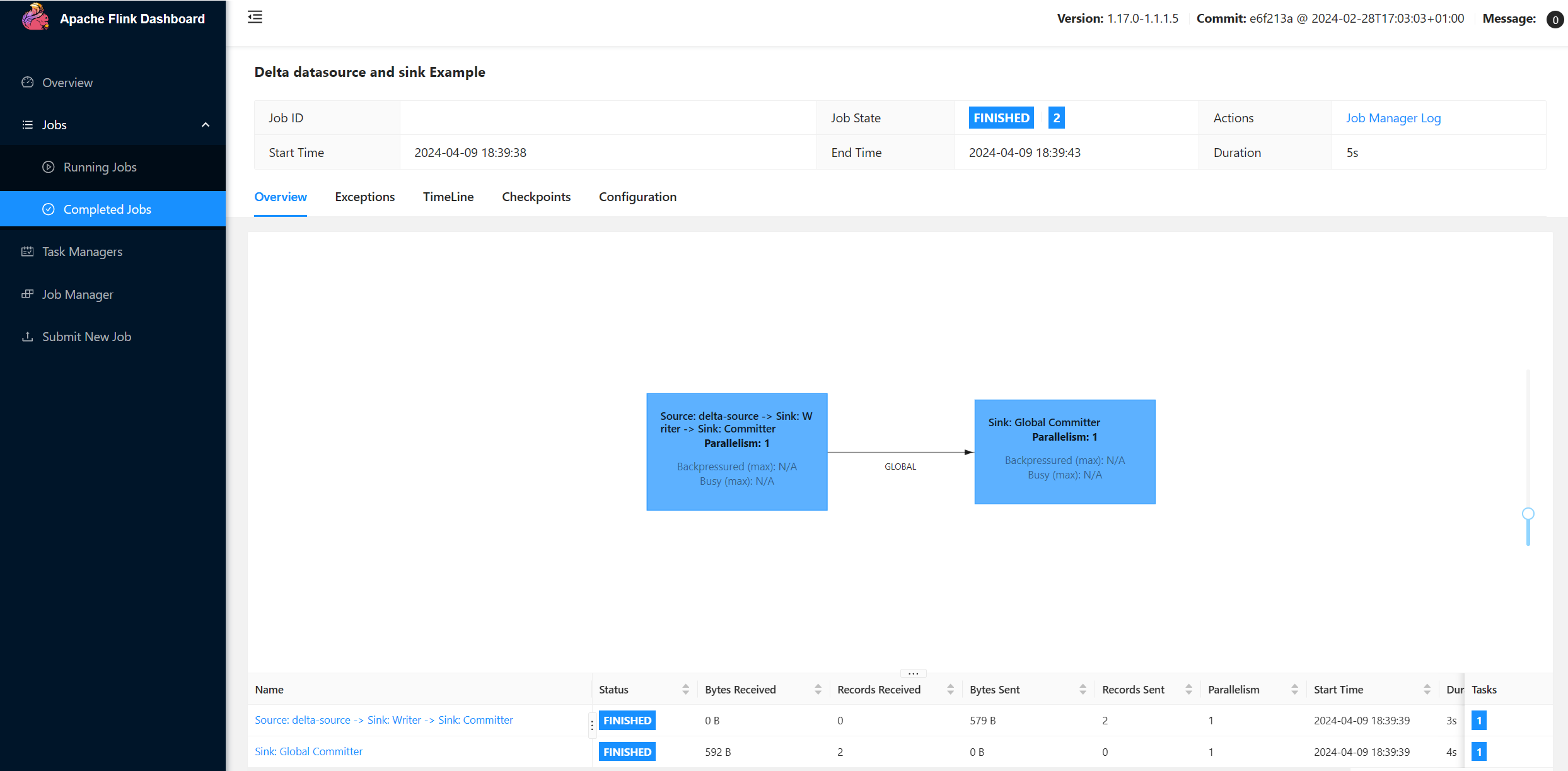
Buscar resultados en ADLS.





Integración de Power BI
Una vez que los datos están en el receptor delta, puede ejecutar la consulta en Power BI Desktop y crear un informe.
Abra Power BI Desktop para obtener los datos mediante el conector de ADLS Gen2.
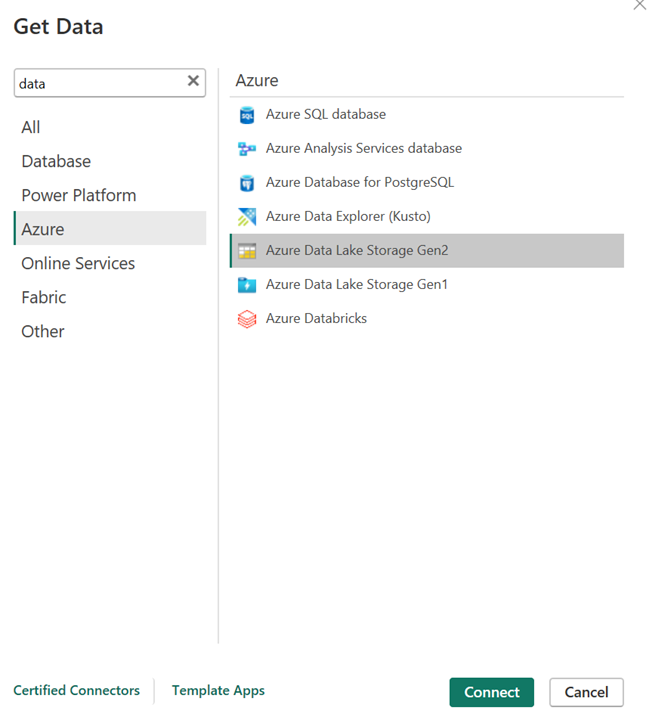
Dirección URL de la cuenta de almacenamiento.

Cree M-query para el origen e invoque la función, que consulta los datos de la cuenta de almacenamiento.
Una vez que los datos estén disponibles, puede crear informes.
Referencias
- Los nombres de Apache, Apache Flink, Flink y los proyectos de código abierto asociados son marcas comerciales de la Apache Software Foundation (ASF).