Orquestación de trabajos de Apache Flink® mediante Azure Data Factory Workflow Orchestration Manager (con tecnología de Apache Airflow)
Importante
Azure HDInsight en AKS se retiró el 31 de enero de 2025. Obtenga más información con este anuncio.
Debe migrar las cargas de trabajo a microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo.
Importante
Esta característica está actualmente en versión preliminar. Los Términos de uso complementarios para las versiones preliminares de Microsoft Azure incluyen más términos legales que se aplican a las características de Azure que se encuentran en versión beta, en versión preliminar o, de lo contrario, aún no se han publicado en disponibilidad general. Para obtener información sobre esta versión preliminar específica, consulte la información de la versión preliminar de Azure HDInsight en AKS. Para preguntas o sugerencias de características, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
En este artículo se describe la administración de un trabajo de Flink mediante API REST de Azure y la canalización de datos de orquestación con Azure Data Factory Workflow Orchestration Manager. servicio de orquestación de flujos de trabajo de Azure Data Factory es una manera sencilla y eficaz de crear y administrar entornos de de Apache Airflow, lo que le permite ejecutar canalizaciones de datos a escala fácilmente.
Apache Airflow es una plataforma de código abierto que crea, programa y supervisa flujos de trabajo de datos complejos mediante programación. Permite definir un conjunto de tareas, denominados operadores que se pueden combinar en grafos acíclicos dirigidos (DAG) para representar canalizaciones de datos.
En el diagrama siguiente se muestra la ubicación de Airflow, Key Vault y HDInsight en AKS en Azure.

Se crean varias entidades de servicio de Azure en función del ámbito para limitar el acceso que necesita y administrar el ciclo de vida de credenciales de cliente de forma independiente.
Se recomienda rotar las claves de acceso o los secretos periódicamente.
Pasos de configuración
Cargue el archivo jar de trabajo de Flink en la cuenta de almacenamiento. Puede ser la cuenta de almacenamiento principal asociada al clúster de Flink o a cualquier otra cuenta de almacenamiento, donde debe asignar el rol "Propietario de datos de blobs de almacenamiento" al MSI asignado por el usuario que se usa para el clúster en esta cuenta de almacenamiento.
Azure Key Vault, puede seguir este tutorial para crear un Azure Key Vault nuevo si no tiene uno.
Cree una entidad de servicio de Microsoft Entra para acceder a Key Vault: conceda permisos para acceder a Azure Key Vault con el rol de "Responsable de secretos de Key Vault" y anote "appId", "password" y "tenant" de la respuesta. Es necesario usar lo mismo para que Airflow use el almacenamiento de Key Vault como backend para almacenar información confidencial.
az ad sp create-for-rbac -n <sp name> --role “Key Vault Secrets Officer” --scopes <key vault Resource ID>Habilite Azure Key Vault para que el Administrador de orquestaciones de flujos de trabajo pueda almacenar y administrar su información confidencial de forma segura y centralizada. Al hacerlo, puede usar variables y conexiones, y se almacenarán automáticamente en Azure Key Vault. Los nombres de las conexiones y variables deben tener el prefijo variables_prefix definido en AIRFLOW__SECRETS__BACKEND_KWARGS. Por ejemplo, si variables_prefix tiene un valor como hdinsight-aks-variables, para una clave de variable de hello, querrá almacenar la variable en hdinsight-aks-variable -hello.
Agregue la siguiente configuración para las sobrescrituras de configuración de Airflow en las propiedades del entorno de ejecución integrado.
AIRFLOW__SECRETS__BACKEND:
"airflow.providers.microsoft.azure.secrets.key_vault.AzureKeyVaultBackend"AIRFLOW__SECRETS__BACKEND_KWARGS:
"{"connections_prefix": "airflow-connections", "variables_prefix": "hdinsight-aks-variables", "vault_url": <your keyvault uri>}”
Agregue la siguiente configuración para la configuración de variables de entorno en las propiedades del entorno de ejecución integrado airflow:
AZURE_CLIENT_ID =
<App Id from Create Azure AD Service Principal>AZURE_TENANT_ID =
<Tenant from Create Azure AD Service Principal>AZURE_CLIENT_SECRET =
<Password from Create Azure AD Service Principal>
Agregar requisitos de Airflow: apache-airflow-providers-microsoft-azure

Cree principal de servicio de Microsoft Entra para acceder a Azure: conceda permiso para acceder al clúster AKS de HDInsight con el rol de Colaborador, y anote el appId, la contraseña y el inquilino de la respuesta.
az ad sp create-for-rbac -n <sp name> --role Contributor --scopes <Flink Cluster Resource ID>Cree los siguientes secretos en el almacén de claves con el valor de appId, contraseña e inquilino de la entidad de servicio de AD anterior, con el prefijo de propiedad variables_prefix definido en AIRFLOW__SECRETS__BACKEND_KWARGS. El código DAG puede acceder a cualquiera de estas variables sin variables_prefix.
hdinsight-aks-variables-api-client-id=
<App ID from previous step>hdinsight-aks-variables-api-secret=
<Password from previous step>hdinsight-aks-variables-tenant-id=
<Tenant from previous step>
from airflow.models import Variable def retrieve_variable_from_akv(): variable_value = Variable.get("client-id") print(variable_value)

Definición de DAG
Un DAG (Gráfico Acíclico dirigido) es el concepto principal de Airflow, la recopilación de tareas conjuntamente, organizadas con dependencias y relaciones para decir cómo se deben ejecutar.
Hay tres maneras de declarar un DAG:
Puede usar un administrador de contexto, que agrega el DAG a cualquier elemento dentro de él implícitamente.
Puede usar un constructor estándar, pasando el DAG a cualquier operador que use.
Puede usar el decorador de @dag para convertir una función en un generador DAG (desde airflow.decorators import dag).
Los DAGs no son nada sin tareas para ejecutar, y ellas vienen en forma de operadores, sensores o TaskFlow.
Puede leer más detalles sobre DAG, Flujo de control, SubDAG, TaskGroups, etc. directamente desde Apache Airflow.
Ejecución de DAG
El código de ejemplo está disponible en el git de ; descargue localmente el código en su equipo y cargue el archivo wordcount.py en un almacenamiento de tipo blob. Siga los pasos y para importar el DAG en el flujo de trabajo creado durante la instalación.
El wordcount.py es un ejemplo de orquestación de un envío de trabajo de Flink mediante Apache Airflow con HDInsight en AKS. El DAG tiene dos tareas:
obtener
OAuth TokenInvocación de la API REST de Azure de envío de trabajos de Flink de HDInsight para enviar un nuevo trabajo
El DAG espera tener configurado el Principal de Servicio, como se describe durante el proceso de configuración de la credencial del cliente OAuth, y pasar la siguiente configuración de entrada para la ejecución.
Pasos de ejecución
Ejecute el DAG desde la interfaz de usuario de Airflow, puede abrir la interfaz de usuario de Azure Data Factory Workflow Orchestration Manager haciendo clic en el icono Supervisar.

Seleccione el DAG "FlinkWordCountExample" en la página "DAGs".

Haga clic en el icono "ejecutar" de la esquina superior derecha y seleccione "Desencadenar DAG con configuración".
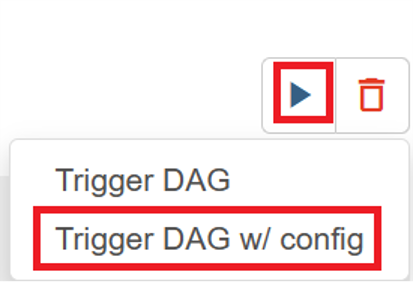
Paso de JSON de configuración necesario
{ "jarName":"WordCount.jar", "jarDirectory":"abfs://filesystem@<storageaccount>.dfs.core.windows.net", "subscription":"<cluster subscription id>", "rg":"<cluster resource group>", "poolNm":"<cluster pool name>", "clusterNm":"<cluster name>" }Al hacer clic en el botón "Desencadenar", se inicia la ejecución del DAG.
Puede visualizar el estado de las tareas de DAG desde la ejecución de DAG.

Validación de la ejecución del trabajo desde el portal
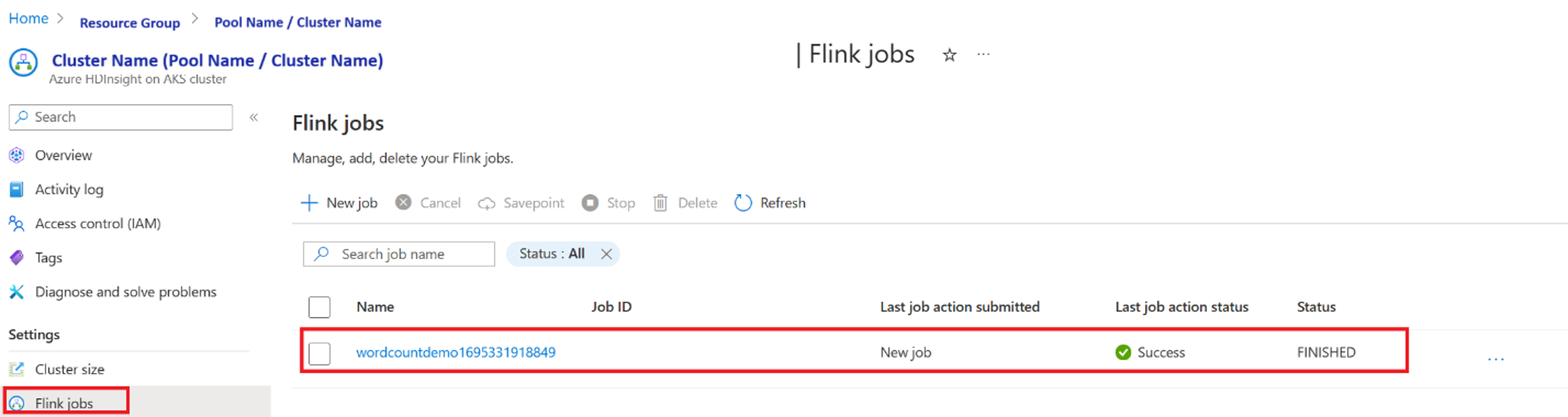
Validar el trabajo en "Apache Flink Dashboard"






Código de ejemplo
Este es un ejemplo de orquestación de la canalización de datos mediante Airflow con HDInsight en AKS.
El DAG espera tener la configuración para el Principal del Servicio para la credencial del Cliente OAuth y proporcionar la siguiente configuración de entrada para su ejecución.
{
'jarName':'WordCount.jar',
'jarDirectory':'abfs://filesystem@<storageaccount>.dfs.core.windows.net',
'subscription':'<cluster subscription id>',
'rg':'<cluster resource group>',
'poolNm':'<cluster pool name>',
'clusterNm':'<cluster name>'
}
Referencia
- Consulte el código de ejemplo .
- Sitio web de Apache Flink
- Apache, Apache Airflow, Airflow, Apache Flink, Flink y los nombres de proyecto de código abierto asociados son marcas comerciales de la Apache Software Foundation (ASF).