Conexión de Apache Flink® en HDInsight en AKS con Azure Event Hubs para Apache Kafka®
Importante
Azure HDInsight en AKS se retiró el 31 de enero de 2025. Obtenga más información con este anuncio.
Debe migrar las cargas de trabajo a microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo.
Importante
Esta característica está actualmente en versión preliminar. Los Términos de uso complementarios para las versiones preliminares de Microsoft Azure incluyen más términos legales que se aplican a las características de Azure que se encuentran en versión beta, en versión preliminar o, de lo contrario, aún no se han publicado en disponibilidad general. Para obtener información sobre esta versión preliminar específica, consulte información de la versión preliminar de Azure HDInsight en AKS. Para preguntas o sugerencias de funciones, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre la Comunidad de Azure HDInsight.
Un caso de uso conocido para Apache Flink es stream analytics. La opción popular de muchos usuarios para usar los flujos de datos, que se ingieren mediante Apache Kafka. Las instalaciones típicas de Flink y Kafka comienzan con flujos de eventos que se envían a Kafka y que pueden ser consumidos por trabajos de Flink. Azure Event Hubs proporciona un punto de conexión de Apache Kafka en un centro de eventos, que permite a los usuarios conectarse al centro de eventos mediante el protocolo Kafka.
En este artículo, exploraremos cómo conectar de Azure Event Hubs con Apache Flink en HDInsight en AKS y trataremos lo siguiente:
- Crear un espacio de nombres de Event Hubs
- Creación de un clúster de HDInsight en AKS con Apache Flink
- Ejecutar el productor de Flink
- Paquete de archivos Jar para Apache Flink
- Validación de envío de trabajo &
Creación de un espacio de nombres de Event Hubs y Event Hubs
Para crear un espacio de nombres de Event Hubs y los propios Event Hubs, consulte aquí.

Configurar el clúster de Flink en HDInsight en AKS
Con HDInsight existente en el grupo de clústeres de AKS, puede crear un clúster de Flink
Ejecute el productor de Flink agregando los bootstrap.servers de y la información de y
producer.config.bootstrap.servers={YOUR.EVENTHUBS.FQDN}:9093 client.id=FlinkExampleProducer sasl.mechanism=PLAIN security.protocol=SASL_SSL sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="$ConnectionString" \ password="{YOUR.EVENTHUBS.CONNECTION.STRING}";Reemplace
{YOUR.EVENTHUBS.CONNECTION.STRING}con la cadena de conexión para su espacio de nombres de Event Hubs. Para obtener instrucciones sobre cómo obtener la cadena de conexión, consulte detalles sobre cómo obtener una cadena de conexión de Event Hubs.Por ejemplo
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="Endpoint=sb://mynamespace.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=XXXXXXXXXXXXXXXX";
Empaquetado del archivo JAR para Flink
Package com.example.app;
package contoso.example; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.io.FileReader; import java.util.Properties; public class AzureEventHubDemo { public static void main(String[] args) throws Exception { // 1. get stream execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); ParameterTool parameters = ParameterTool.fromArgs(args); String input = parameters.get("input"); Properties properties = new Properties(); properties.load(new FileReader(input)); // 2. generate stream input DataStream<String> stream = createStream(env); // 3. sink to eventhub KafkaSink<String> sink = KafkaSink.<String>builder().setKafkaProducerConfig(properties) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("topic1") .setValueSerializationSchema(new SimpleStringSchema()) .build()) .build(); stream.sinkTo(sink); // 4. execute the stream env.execute("Produce message to Azure event hub"); } public static DataStream<String> createStream(StreamExecutionEnvironment env){ return env.generateSequence(0, 200) .map(new MapFunction<Long, String>() { @Override public String map(Long in) { return "FLINK PRODUCE " + in; } }); } }Agregue el fragmento de código para ejecutar el productor de Flink.

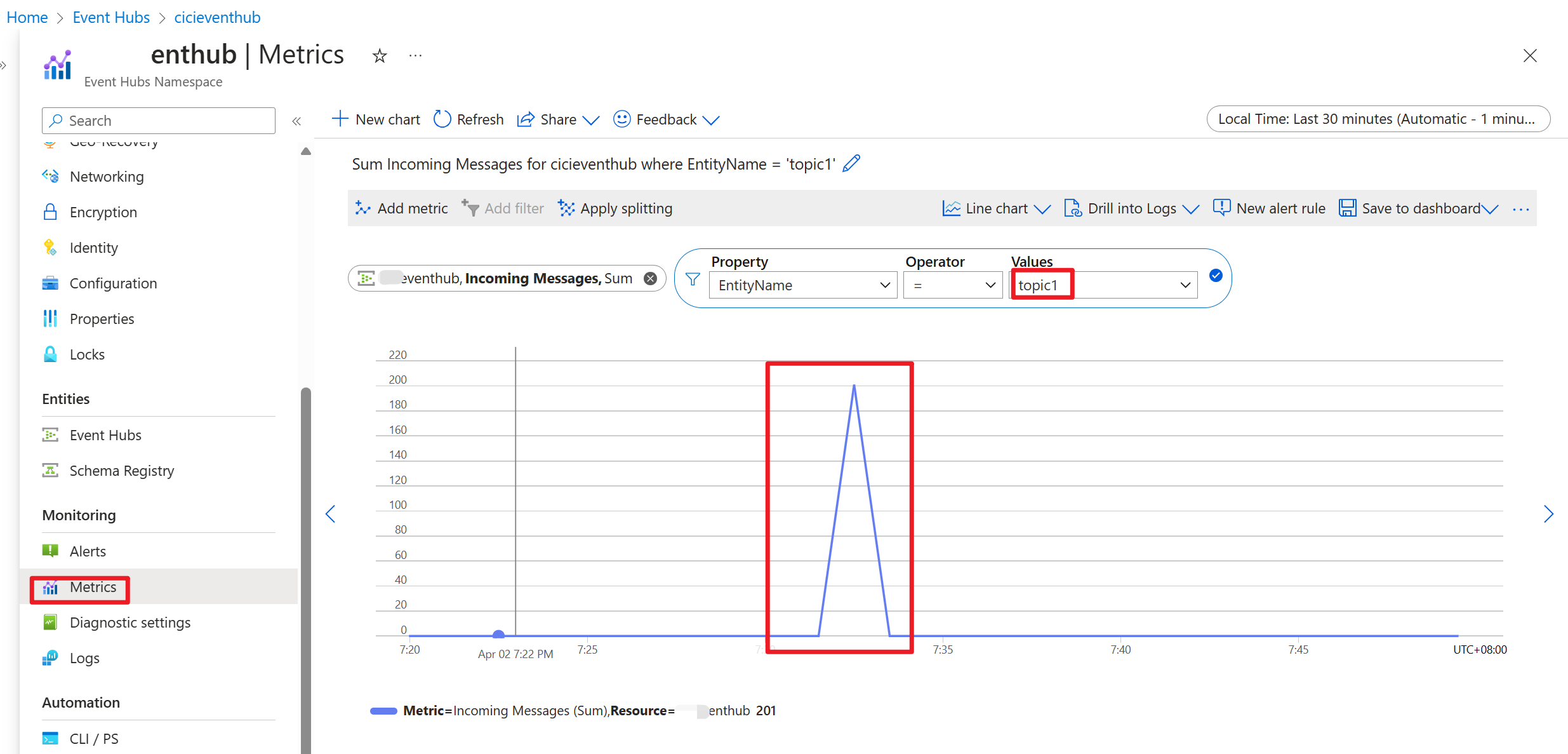
Una vez ejecutado el código, los eventos se almacenan en el tema "topic1"


Referencia
- Sitio web de Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink y los nombres de los proyectos de código abierto asociados son marcas comerciales de la Apache Software Foundation (ASF).