Uso del explorador de trabajos y la vista de trabajos para Azure Data Lake Analytics
Importante
Azure Data Lake Analytics se retiró el 29 de febrero de 2024. Obtenga más información con este anuncio.
Para el análisis de datos, su organización puede usar azure Synapse Analytics o Microsoft Fabric.
El servicio Azure Data Lake Analytics archiva los trabajos enviados en un almacén de consultas. En este artículo, aprenderá a usar el Explorador de trabajos y la vista de trabajos en Herramientas de Azure Data Lake para Visual Studio para encontrar la información histórica del trabajo.
De forma predeterminada, el servicio Data Lake Analytics archiva los trabajos durante 30 días. El período de expiración se puede configurar desde Azure Portal mediante la configuración de la directiva de expiración personalizada. No podrá acceder a la información del trabajo después de la expiración.
Prerrequisitos
Consulte Herramientas de Data Lake para Visual Studio: requisitos previos.
Abrir el explorador de trabajos
Acceda al explorador de trabajos mediante Explorador de servidores>Azure>Data Lake Analytics>Trabajos en Visual Studio. Con el Explorador de trabajos, puede acceder al almacén de consultas de una cuenta de Data Lake Analytics. Explorador de trabajos muestra el Almacén de consultas a la izquierda, que muestra información básica del trabajo y Vista de trabajo a la derecha que muestra información detallada del trabajo.
Vista de empleo
Vista de trabajo muestra la información detallada de un trabajo. Para abrir un trabajo, puede hacer doble clic en un trabajo en el Explorador de trabajos o abrirlo desde el menú de Data Lake haciendo clic en Vista de trabajo. Debería ver un cuadro de diálogo rellenado con la dirección URL del trabajo.
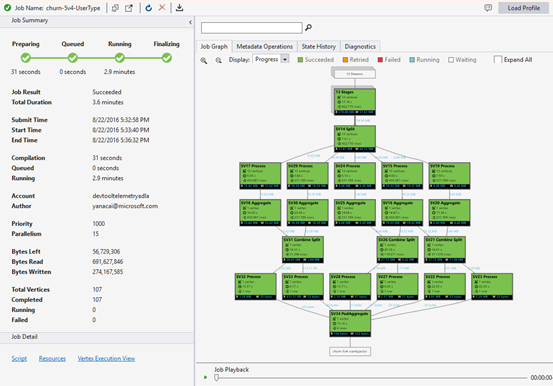
La vista de trabajo contiene:
Resumen del trabajo
Actualice la vista de trabajo para ver la información más reciente sobre la ejecución de trabajos.
Estado del trabajo (gráfico):
Estado del trabajo describe las fases de trabajo:
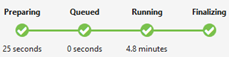
Preparación: cargue el script en la nube, compile y optimice el script mediante el servicio de compilación.
En cola: los trabajos se ponen en cola cuando están esperando suficientes recursos o los trabajos superan el límite máximo de trabajos simultáneos permitidos por cuenta. La configuración de prioridad determina la secuencia de trabajos en cola: cuanto menor sea el número, mayor será la prioridad.
En ejecución: el trabajo se está realmente ejecutando en tu cuenta de Data Lake Analytics.
Finalización: el trabajo se está completando (por ejemplo, finalizando el archivo).
El trabajo puede fallar en cada fase. Por ejemplo, errores de compilación en la fase de preparación, errores de tiempo de espera en la fase en cola y errores de ejecución en la fase en ejecución, etc.
Información básica
La información básica del trabajo se muestra en la parte inferior del panel Resumen del trabajo.
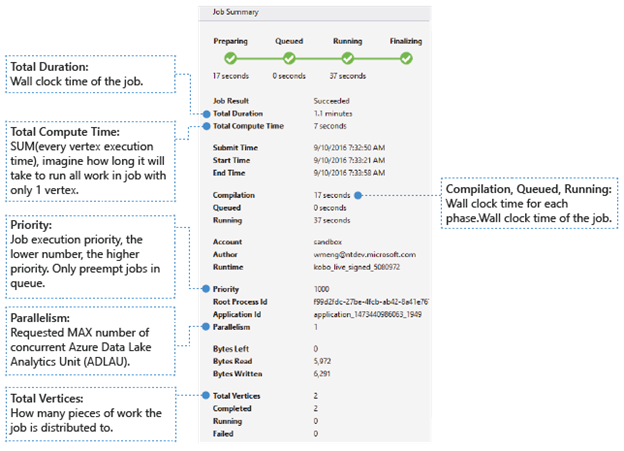
- Resultado del trabajo: exitoso o fallido. El trabajo podría fallar en cada fase.
- Duración total: tiempo de reloj (duración) entre la hora de envío y la hora de finalización.
- Tiempo total de proceso: la suma de cada tiempo de ejecución de vértices, puede considerarla como la hora en que el trabajo se ejecuta en un solo vértice. Consulte Vértices Totales para obtener más información sobre los vértices.
- Hora de envío, inicio y finalización: la hora en que el servicio Data Lake Analytics recibe el envío del trabajo o comienza a ejecutar el trabajo o finaliza el trabajo correctamente o no.
- Compilación, puesta en cola o en ejecución: tiempo de reloj invertido durante la fase de preparación, puesta en cola o en ejecución.
- Cuenta: la cuenta de Data Lake Analytics que se usa para ejecutar el trabajo.
- Autor: el usuario que envió el trabajo, puede ser la cuenta de una persona real o una cuenta del sistema.
- Prioridad: la prioridad del trabajo. Cuanto menor sea el número, mayor será la prioridad. Solo afecta la secuencia de los trabajos en la cola. Establecer una prioridad más alta no interrumpe los trabajos en ejecución.
- Paralelismo: número máximo solicitado de unidades simultáneas de Azure Data Lake Analytics (ADLAUs), también conocido como vértices. Actualmente, un vértice es igual a una máquina virtual con dos núcleos virtuales y ram de seis GB, aunque esto podría actualizarse en futuras actualizaciones de Data Lake Analytics.
- Bytes restantes: bytes que deben procesarse hasta que se complete el trabajo.
- Bytes leídos y escritos: bytes que se han leído y escrito desde que el trabajo comenzó a ejecutarse.
- Vértices totales: el trabajo se divide en muchas partes de trabajo, cada pieza de trabajo se denomina vértice. Este valor describe cuántas tareas o unidades de trabajo de las que consta el trabajo. Puede considerar un vértice como una unidad de proceso básica, también conocida como unidad de análisis de Azure Data Lake (ADLAU) y los vértices se pueden ejecutar en paralelismo.
- Completado/En ejecución/Con errores: el recuento de vértices completados/en ejecución/con errores. Los vértices pueden fallar debido tanto a fallos de código de usuario como del sistema, pero el sistema reintenta automáticamente los vértices fallidos varias veces. Si el vértice sigue fallando después de reintentar, se producirá un error en todo el trabajo.
Gráfico de trabajos
Un script U-SQL representa la lógica de transformar los datos de entrada en los datos de salida. El script se compila y optimiza para un plan de ejecución físico en la fase de preparación. El gráfico de tareas (Job Graph) muestra el plan de ejecución físico. En el siguiente diagrama se ilustra este proceso:
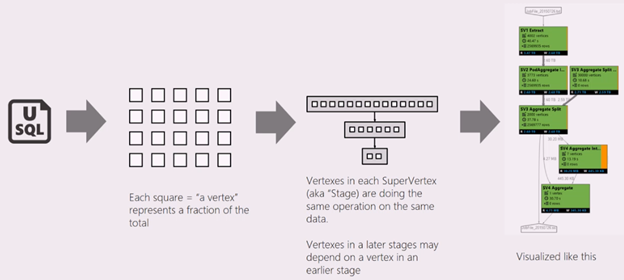
Un trabajo se divide en muchas tareas. Cada pieza de trabajo se denomina vértice. Los vértices se agrupan como Súper Vértice (también conocido como fase) y se representan como grafo de trabajos. Las etiquetas verdes de etapa en el gráfico de trabajos muestran las etapas.
Cada vértice de una fase realiza el mismo tipo de trabajo con diferentes partes de los mismos datos. Por ejemplo, si tiene un archivo con un terabyte de datos y hay cientos de vértices que leen desde él, cada uno de ellos lee un fragmento. Esos vértices se agrupan en la misma fase y realizan el mismo trabajo en diferentes partes del mismo archivo de entrada.
-
En una fase determinada, algunos números se muestran en el placard.
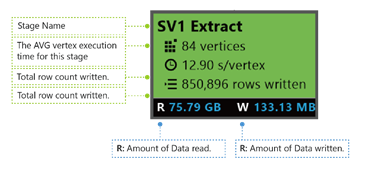
Extracción SV1: el nombre de una etapa, asignado por un número y el método de operación.
84 vértices: recuento total de vértices en esta fase. La ilustración indica cuántas partes de trabajo se dividen en esta fase.
12.90 s/vértice: tiempo medio de ejecución de vértices para esta fase. Esta figura se calcula mediante la SUMA (cada tiempo de ejecución de vértice) / (número total de vértices). Lo que significa que si pudiera ejecutar todos los vértices en paralelo, toda la fase se completa en 12,90 s. También significa que si todo el trabajo de esta fase se realiza en secuencia, el costo sería #vertices * tiempo promedio.
850 895 filas escritas: recuento total de filas escritas en esta fase.
R/W: cantidad de datos leídos y escritos en esta fase en bytes.
Colores: los colores se usan en la fase para indicar un estado de vértice diferente.
- Se indica en verde que el vértice se ha logrado.
- El color naranja indica que se está reintentando el vértice. Error en el vértice reintentado, pero el sistema lo reintenta automáticamente y correctamente, y la fase general se completa correctamente. Si el vértice se reintenta pero aún así falló, el color se vuelve rojo y todo el trabajo falló.
- El rojo indica que se produjo un error, lo que significa que el sistema ha reintentado un cierto vértice algunas veces, pero sigue fallando. Este escenario provoca que el trabajo falle por completo.
- Azul significa que se está ejecutando un determinado vértice.
- Blanco indica que el vértice está en espera. El vértice podría estar esperando ser programado una vez que un ADLAU esté disponible, o podría estar esperando datos de entrada, ya que estos podrían no estar listos.
Puede encontrar más detalles para la etapa si mantiene el cursor del ratón sobre un estado:
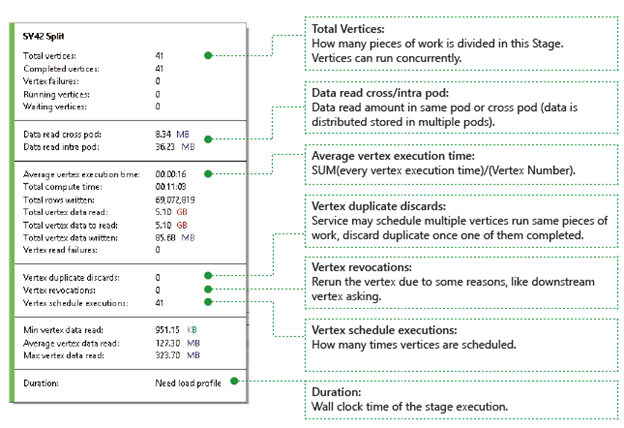
Vértices: describen los detalles de los vértices, por ejemplo, cuántos vértices en total, cuántos vértices se han completado, si están fallados o si siguen ejecutándose o esperando, etc.
Datos leídos entre y dentro de pods: Los archivos y los datos se almacenan en múltiples pods en un sistema de archivos distribuido. El valor aquí describe la cantidad de datos que se han leído en el mismo pod o entre diferentes pods.
Tiempo total de proceso: la suma del tiempo de ejecución de cada vértice en la etapa, puede considerarse como el tiempo que llevaría si todo el trabajo de la etapa se ejecutara en un solo vértice.
Datos y filas escritas o leídas: indica la cantidad de datos o filas que se han leído y escrito, o debe leerse.
Errores de lectura de vértices: Describe cuántos vértices fallan al leer los datos.
Descartes de vértices duplicados: si un vértice tiene una ejecución lenta, el sistema podría programar varios vértices para ejecutar el mismo trabajo. Los vértices redundantes se descartarán una vez que uno de los vértices se complete correctamente. El descarte de duplicados de vértices registra el número de vértices que se descartan como duplicados en la etapa.
Revocaciones de vértices: el vértice se realizó correctamente, pero se vuelve a ejecutar más adelante debido a algunas razones. Por ejemplo, si el vértice de bajada pierde datos de entrada intermedios, pedirá al vértice ascendente que vuelva a ejecutarse.
Ejecuciones programadas de vértices: El tiempo total durante el cual los vértices han sido programados.
Lectura de datos mínima/promedio/máxima de vértices: el mínimo, promedio y máximo de cada dato leído de los vértices.
Duración: el tiempo en tiempo real que tarda una etapa, necesitas cargar el perfil para ver este valor.
Reproducción de trabajos
Data Lake Analytics ejecuta trabajos y archiva la información de ejecución de los vértices de los trabajos, como cuándo se inician los vértices, se detienen, se producen errores y se reintentan, etc. Toda la información se registra automáticamente en el almacén de consultas y se almacena en su perfil de trabajo. Puede descargar el perfil de trabajo a través de "Cargar perfil" en la Vista de trabajo y puede ver la reproducción del trabajo después de descargarlo.
La reproducción de trabajos es una visualización epitome de lo que ha ocurrido en el clúster. Le ayuda a ver el progreso de la ejecución del trabajo y detectar visualmente anomalías de rendimiento y cuellos de botella en un tiempo muy corto (menos de 30s normalmente).
Visualización del mapa térmico del trabajo
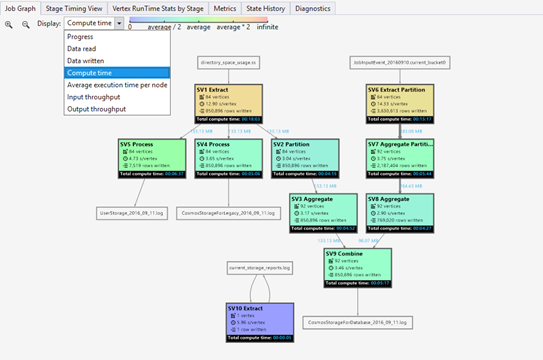
Mapa térmico del trabajo se puede seleccionar a través de la lista desplegable Mostrar en Gráfico de trabajos.
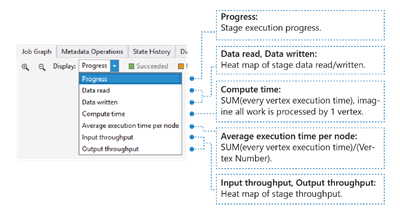
Muestra el mapa térmico de E/S, tiempo y rendimiento de un trabajo, mediante el cual puedes visualizar dónde se emplea la mayor parte del tiempo, o si tu actividad depende principalmente de las operaciones E/S, entre otros aspectos.
- Progreso: el progreso de la ejecución del trabajo, consulte la información en la etapa.
- Lectura y escritura de datos: mapa térmico de los datos totales leídos y escritos en cada fase.
- Tiempo de cálculo: el mapa térmico de la suma del tiempo de ejecución de cada vértice, puede considerarlo como cuánto tiempo tardaría si todo el trabajo de la fase se ejecutara con un solo vértice.
- Tiempo medio de ejecución por nodo: mapa térmico de SUMA (tiempo de ejecución de cada vértice) / (Número de vértices). Lo que significa que si pudiera asignar todos los vértices ejecutados en paralelo, toda la fase se completará en este período de tiempo.
- Rendimiento de entrada/salida: El mapa térmico del rendimiento de entrada y salida de cada etapa le permite confirmar si su tarea es dependiente de E/S.
-
Operaciones de metadatos
Puede realizar algunas operaciones de metadatos en el script U-SQL, como crear una base de datos, quitar una tabla, etc. Estas operaciones se muestran en Operación de metadatos después de la compilación. Puede encontrar aserciones, crear entidades, quitar entidades aquí.

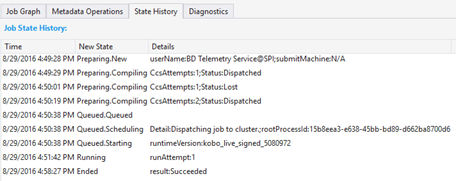
Historial de estado
El historial de estado también se visualiza en Resumen del trabajo, pero puede obtener más detalles aquí. Puede encontrar información detallada, como cuándo el trabajo está preparado, en cola, en ejecución, finalizado. También puede encontrar cuántas veces se ha compilado el trabajo (CcsAttempts: 1), cuándo se envía el trabajo al clúster realmente (Detail: enviando el trabajo al clúster), etc.
Diagnósticos
La herramienta diagnostica automáticamente la ejecución del trabajo. Recibirá alertas cuando haya algunos errores o problemas de rendimiento en los trabajos. Tenga en cuenta que debe descargar Profile para obtener información completa aquí.
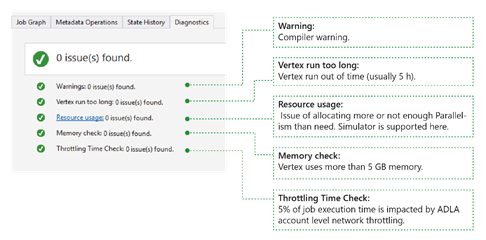
- Advertencias: una alerta se muestra aquí con la advertencia del compilador. Puede seleccionar el enlace "x problema(s)" para obtener más detalles cuando aparezca la alerta.
- Un vértice se ejecuta demasiado tiempo: si algún vértice se queda sin tiempo (por ejemplo, 5 horas), se identificarán problemas aquí.
- Uso de recursos: si asignó más paralelismo del necesario o no asignó suficiente, los problemas se encontrarán aquí. También puede seleccionar Uso de recursos para ver más detalles y realizar escenarios hipotéticos para encontrar una mejor asignación de recursos (para obtener más detalles, consulte esta guía).
- Comprobación de memoria: si algún vértice usa más de 5 GB de memoria, se encontrarán problemas aquí. La ejecución del trabajo podría ser interrumpida por el sistema si usa más memoria que el límite de memoria del sistema.
Detalles del trabajo
Detalles del trabajo muestra la información detallada del trabajo, incluidos script, recursos y vista de ejecución de vértices.
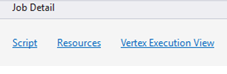
Script
El script U-SQL del trabajo se almacena en el repositorio de consultas. Puede ver el script U-SQL original y volver a enviarlo si es necesario.
Recursos
Puede encontrar los resultados de la compilación de trabajos almacenados en el query store mediante los Recursos. Por ejemplo, puede encontrar "algebra.xml" que se usa para mostrar el gráfico de trabajos, los ensamblados registrados, etc. aquí.
Vista de ejecución de vértices
Muestra los detalles de ejecución de vértices. El perfil de trabajo archiva todos los registros de ejecución de vértices, como el total de datos leídos y escritos, el tiempo de ejecución, el estado, etc. A través de esta vista, puede obtener más detalles sobre cómo se ejecutó un trabajo. Para obtener más información, vea Usar la vista de ejecución de vértices en Data Lake Tools para Visual Studio.
Pasos siguientes
- Para registrar información de diagnóstico, consulte Acceso a los registros de diagnóstico de Azure Data Lake Analytics
- Para ver una consulta más compleja, consulte Análisis de registros de sitios web mediante Azure Data Lake Analytics.
- Para usar la Vista de Ejecución de Vértice, consulte Utilizar la Vista de Ejecución de Vértice en las Herramientas de Data Lake para Visual Studio