Resolución de problemas de asimetría de datos en Azure Data Lake Analytics mediante Herramientas de Azure Data Lake para Visual Studio
Importante
Azure Data Lake Analytics retiró el 29 de febrero de 2024. Más información sobre este anuncio.
Para el análisis de datos, su organización puede usar Azure Synapse Analytics o Microsoft Fabric.
¿Qué es la asimetría de datos?
En pocas palabras, una asimetría de datos es un valor sobrerrepresentado. Imagine que ha asignado 50 examinadores fiscales para auditar las declaraciones fiscales, un examinador para cada estado de EE. UU. El examinador deCupo, porque la población es pequeña, tiene poco que hacer. En California, sin embargo, el inspector está ocupado porque ese estado está densamente poblado.

En nuestro escenario, los datos se distribuyen de forma desigual entre los inspectores de impuestos, lo que significa que algunos inspectores deben trabajar más que otros. Seguro que en su propio trabajo experimenta con frecuencia situaciones como el ejemplo del inspector de impuestos. En términos más técnicos, un vértice recibe mucho más datos que otros elementos de su mismo nivel, por lo que debe trabajar más que los demás y puede llegar a ralentizar un trabajo completo. Y, lo que es peor, el trabajo puede producir un error, porque los vértices podrían tener, por ejemplo, una limitación de tiempo de ejecución de 5 horas y una limitación de 6 GB de memoria.
Resolución de problemas de asimetría de datos
Herramientas de Azure Data Lake para Visual Studio y Visual Studio Code pueden ayudar a detectar si el trabajo tiene un problema de asimetría de datos.
- Instalación de Herramientas de Azure Data Lake para Visual Studio
- Instalación de código de Herramientas de Azure Data Lake para Visual Studio
Si es así, puede resolverlo probando las soluciones de esta sección.
Solución 1: Mejorar la creación de particiones de tabla
Opción 1: Filtrar el valor de clave desfasada por anticipado
Si no afecta a la lógica de negocios, puede filtrar los valores de mayor frecuencia de antemano. Por ejemplo, si hay muchos 000-000-000 en el GUID de columna, es posible que no desee agregar ese valor. Antes de agregarlo, puede escribir "WHERE GUID != “000-000-000”” para filtrar el valor de alta frecuencia.
Opción 2: Seleccionar otra clave de partición o distribución
En el ejemplo anterior, si solo quiere comprobar la carga de trabajo de auditoría fiscal de todo el país o región, puede mejorar la distribución de datos si selecciona el número de identificación como clave. A veces, si elige una clave de partición o distribución diferente, puede distribuir los datos de manera más uniforme, aunque debe asegurarse de que esta elección no afecta a su lógica de negocios. Por ejemplo, para calcular la suma de impuestos para cada estado, puede designar Estado como la clave de partición. Si sigue apareciendo el problema, pruebe a utilizar la opción 3.
Opción 3: Agregar más claves de partición o distribución
En lugar de usar solo Estado como clave de partición, puede usar más de una clave para las particiones. Por ejemplo, considere la posibilidad de agregar código postal como otra clave de partición para reducir los tamaños de partición de datos y distribuir los datos de forma más uniforme.
Opción 4: Usar la distribución round robin
Si no encuentra una clave adecuada para la partición y la distribución, puede intentar usar la distribución round robin. La distribución round robin trata por igual cada fila y la coloca de forma aleatoria en el depósito correspondiente. En este caso, los datos se distribuyen de manera uniforme, pero pierden información de localidad, un inconveniente que puede reducir el rendimiento de trabajo en algunas operaciones. Además, si va a realizar agregaciones para la clave sesgada de todos modos, el problema de asimetría de datos se conservará. Para obtener más información sobre la distribución round robin, consulte la sección Distribuciones de tabla de U-SQL en CREATE TABLE (U-SQL): Creación de una tabla con esquema.
Solución 2: Mejorar el plan de consulta
Opción 1: Usar la instrucción CREATE STATISTICS
U-SQL proporciona la instrucción CREATE STATISTICS en las tablas. Esta instrucción proporciona más información al optimizador de consultas sobre las características de datos (por ejemplo, la distribución de valores) que se almacenan en una tabla. Para la mayoría de las consultas, el optimizador de consultas genera ya las estadísticas necesarias para un plan de consulta de alta calidad. En ocasiones, es posible que tenga que mejorar el rendimiento de las consultas mediante la creación de más estadísticas con CREATE STATISTICS o modificando el diseño de la consulta. Para obtener más información, consulte la página CREATE STATISTICS (U-SQL).
Ejemplo de código:
CREATE STATISTICS IF NOT EXISTS stats_SampleTable_date ON SampleDB.dbo.SampleTable(date) WITH FULLSCAN;
Nota
La información de estadísticas no se actualiza automáticamente. Si actualiza los datos de una tabla sin volver a crear las estadísticas, el rendimiento de las consultas puede verse reducido.
Opción 2: Usar SKEWFACTOR
Si desea sumar el impuesto de cada estado, debe usar GROUP BY estado, un método que no evita el problema de asimetría de datos. Sin embargo, puede proporcionar una sugerencia de datos en la consulta para identificar asimetrías de datos en las claves, de modo que el optimizador pueda optimizar el plan de ejecución.
Normalmente, puede establecer el parámetro como 0,5 y 1, con 0,5, lo que significa que no hay mucha asimetría y un significado de asimetría pesada. Dado que la sugerencia afecta a la optimización de plan de ejecución de la instrucción actual y todas las instrucciones de nivel inferiores, no olvide agregar la sugerencia antes de la agregación con posible asimetría en la clave.
SKEWFACTOR (columns) = x
Proporciona una sugerencia de que las columnas especificadas tienen un factor de asimetría x de 0 (sin asimetría) a 1 (sesgo pesado).
Ejemplo de código:
//Add a SKEWFACTOR hint.
@Impressions =
SELECT * FROM
searchDM.SML.PageView(@start, @end) AS PageView
OPTION(SKEWFACTOR(Query)=0.5)
;
//Query 1 for key: Query, ClientId
@Sessions =
SELECT
ClientId,
Query,
SUM(PageClicks) AS Clicks
FROM
@Impressions
GROUP BY
Query, ClientId
;
//Query 2 for Key: Query
@Display =
SELECT * FROM @Sessions
INNER JOIN @Campaigns
ON @Sessions.Query == @Campaigns.Query
;
Opción 3: Usar ROWCOUNT
Además de SKEWFACTOR, en casos concretos de combinación de clave asimétrica, si sabe que el otro conjunto de filas combinadas es pequeño, puede indicárselo al optimizador agregando la sugerencia ROWCOUNT en la instrucción U-SQL antes de JOIN. De esta manera, el optimizador puede elegir una estrategia de combinación de difusión para ayudar a mejorar el rendimiento. Tenga en cuenta que ROWCOUNT no resuelve el problema de asimetría de datos, pero puede ofrecer ayuda adicional.
OPTION(ROWCOUNT = n)
Identifique un conjunto de filas pequeño antes de JOIN; para ello, proporcione un recuento estimado de filas de enteros.
Ejemplo de código:
//Unstructured (24-hour daily log impressions)
@Huge = EXTRACT ClientId int, ...
FROM @"wasb://ads@wcentralus/2015/10/30/{*}.nif"
;
//Small subset (that is, ForgetMe opt out)
@Small = SELECT * FROM @Huge
WHERE Bing.ForgetMe(x,y,z)
OPTION(ROWCOUNT=500)
;
//Result (not enough information to determine simple broadcast JOIN)
@Remove = SELECT * FROM Bing.Sessions
INNER JOIN @Small ON Sessions.Client == @Small.Client
;
Solución 3: Mejorar el combinador y el reductor definidos por el usuario
Es habitual que escriba un operador definido por el usuario para tratar con una lógica de procesos complicada, y un combinador y un reductor bien escritos pueden mitigar el problema de asimetría de datos en algunos casos.
Opción 1: Usar un reductor recursivo si es posible
De forma predeterminada, un reductor definido por el usuario se ejecuta en modo no recursivo, lo que significa que el trabajo de reducción de una clave se distribuye en un solo vértice. Pero si hay asimetría de datos, los conjuntos de datos muy grandes pueden procesarse en un solo vértice y tener un tiempo de ejecución muy largo.
Para mejorar el rendimiento, puede agregar un atributo a su código para definir que el reductor se ejecute en modo recursivo. A continuación, los conjuntos de datos muy grandes se puede distribuir a varios vértices y ejecutarse en paralelo, lo que acelera el trabajo.
Para cambiar un reductor no recursivo a recursivo, debe asegurarse de que el algoritmo es asociativo. Por ejemplo, la suma es asociativa y la mediana no. Además, debe asegurarse de que la entrada y la salida del reductor mantengan el mismo esquema.
Atributo del reductor recursivo:
[SqlUserDefinedReducer(IsRecursive = true)]
Ejemplo de código:
[SqlUserDefinedReducer(IsRecursive = true)]
public class TopNReducer : IReducer
{
public override IEnumerable<IRow>
Reduce(IRowset input, IUpdatableRow output)
{
//Your reducer code goes here.
}
}
Opción 2: Usar el modo de combinador de nivel de fila si es posible
De forma similar a la sugerencia ROWCOUNT para casos específicos de combinación de claves asimétricas, el modo de combinador intenta distribuir el enorme conjunto de valores de claves asimétricas en varios vértices para que el trabajo se puede ejecutar simultáneamente. El modo de combinador no puede resolver problemas de asimetría de datos, pero puede ofrecer ayuda adicional para grandes conjuntos de valores de clave sesgada.
De forma predeterminada, el modo de combinador es Completo, lo que significa que el conjunto de filas izquierdo y el conjunto de filas derecho no se pueden separar. Establecer el modo como izquierda o derecha/interior permite la combinación de nivel de fila. El sistema separa los conjuntos de filas correspondientes y los distribuye en varios vértices que se ejecutan en paralelo. Sin embargo, antes de configurar el modo de combinador, debe tener cuidado y asegurarse de que se puede dividir el conjunto de filas correspondiente.
El ejemplo siguiente muestra un conjunto de filas izquierdo separado. Cada fila de salida depende de una sola fila de entrada de la izquierda y, potencialmente, de todas las filas de la derecha con el mismo valor de clave. Si establece el modo de combinador como izquierdo, el sistema dividirá el enorme conjunto de filas izquierdo en otros más pequeños y los asignará a varios vértices.
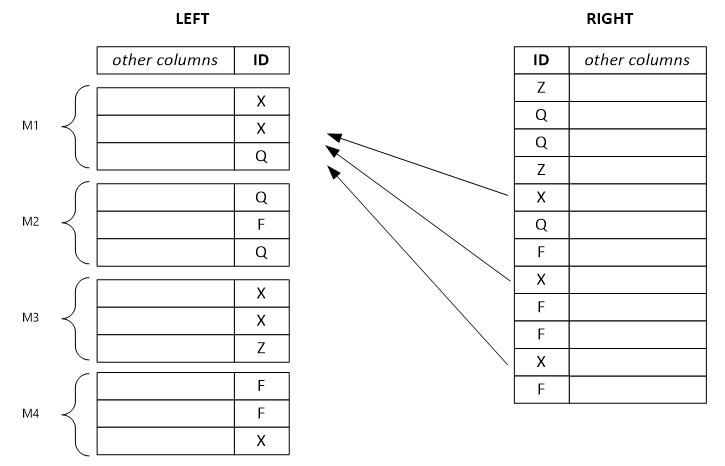
Nota
Si establece un modo de combinador incorrecto, la combinación es menos eficaz y los resultados podrían ser incorrectos.
Atributos del modo de combinador:
SqlUserDefinedCombiner(Mode=CombinerMode.Full): Cada fila de salida puede depender de todas las filas de entrada de la izquierda y la derecha con el mismo valor de clave.
SqlUserDefinedCombiner(Mode=CombinerMode.Left): Cada fila de salida depende de una sola fila de entrada de la izquierda (y potencialmente todas las filas de la derecha con el mismo valor de clave).
qlUserDefinedCombiner(Mode=CombinerMode.Right): Cada fila de salida depende de una sola fila de entrada de la derecha (y potencialmente todas las filas de la izquierda con el mismo valor de clave).
SqlUserDefinedCombiner(Mode=CombinerMode.Inner): Cada fila de salida depende de una sola fila de entrada de la izquierda y la derecha con el mismo valor.
Ejemplo de código:
[SqlUserDefinedCombiner(Mode = CombinerMode.Right)]
public class WatsonDedupCombiner : ICombiner
{
public override IEnumerable<IRow>
Combine(IRowset left, IRowset right, IUpdatableRow output)
{
//Your combiner code goes here.
}
}