Entrenamiento de modelos de IA distribuida en HPC Pack
Fondo
En la actualidad, los modelos de inteligencia artificial evolucionan para llegar a ser más sustanciales, lo que necesita una creciente demanda de hardware avanzado y un clúster de equipos para un entrenamiento eficaz del modelo. HPC Pack puede simplificar el trabajo de entrenamiento del modelo de forma eficaz.
PyTorch Distributed Data Parallel (también conocido como DDP)
Para implementar el entrenamiento de modelos distribuidos, es necesario usar un marco de entrenamiento distribuido. La elección del marco depende de la que se usa para compilar el modelo. En este artículo, le guiaré sobre cómo continuar con PyTorch en HPC Pack.
PyTorch ofrece varios métodos para el entrenamiento distribuido. Entre ellos, se prefiere ampliamente Distributed Data Parallel (DDP) debido a su simplicidad y modificaciones mínimas de código necesarias en el modelo de entrenamiento de una sola máquina actual.
Configuración de un clúster de HPC Pack para el entrenamiento del modelo de IA
Puede configurar un clúster de HPC Pack mediante los equipos locales o máquinas virtuales (VM) en Azure. Solo tiene que asegurarse de que estos equipos están equipados con GPU (en este artículo, usaremos GPU nvidia).
Normalmente, una GPU puede tener un proceso para un trabajo de entrenamiento distribuido. Por lo tanto, si tiene dos equipos (también conocidos como nodos en un clúster de equipos), cada uno equipado con cuatro GPU, puede lograr 2 * 4, lo que equivale a 8 procesos paralelos para un entrenamiento de modelo único. Esta configuración puede reducir potencialmente el tiempo de entrenamiento a aproximadamente el 1/8 en comparación con el entrenamiento de un solo proceso, omitiendo algunas sobrecargas de sincronización de datos entre los procesos.
Creación de un clúster de HPC Pack en una plantilla de ARM
Para simplificar, puede iniciar un nuevo clúster de HPC Pack en Azure, en plantillas de ARM en GitHub.
Seleccione la plantilla "Clúster de nodo principal único para cargas de trabajo de Linux" y haga clic en "Implementar en Azure".
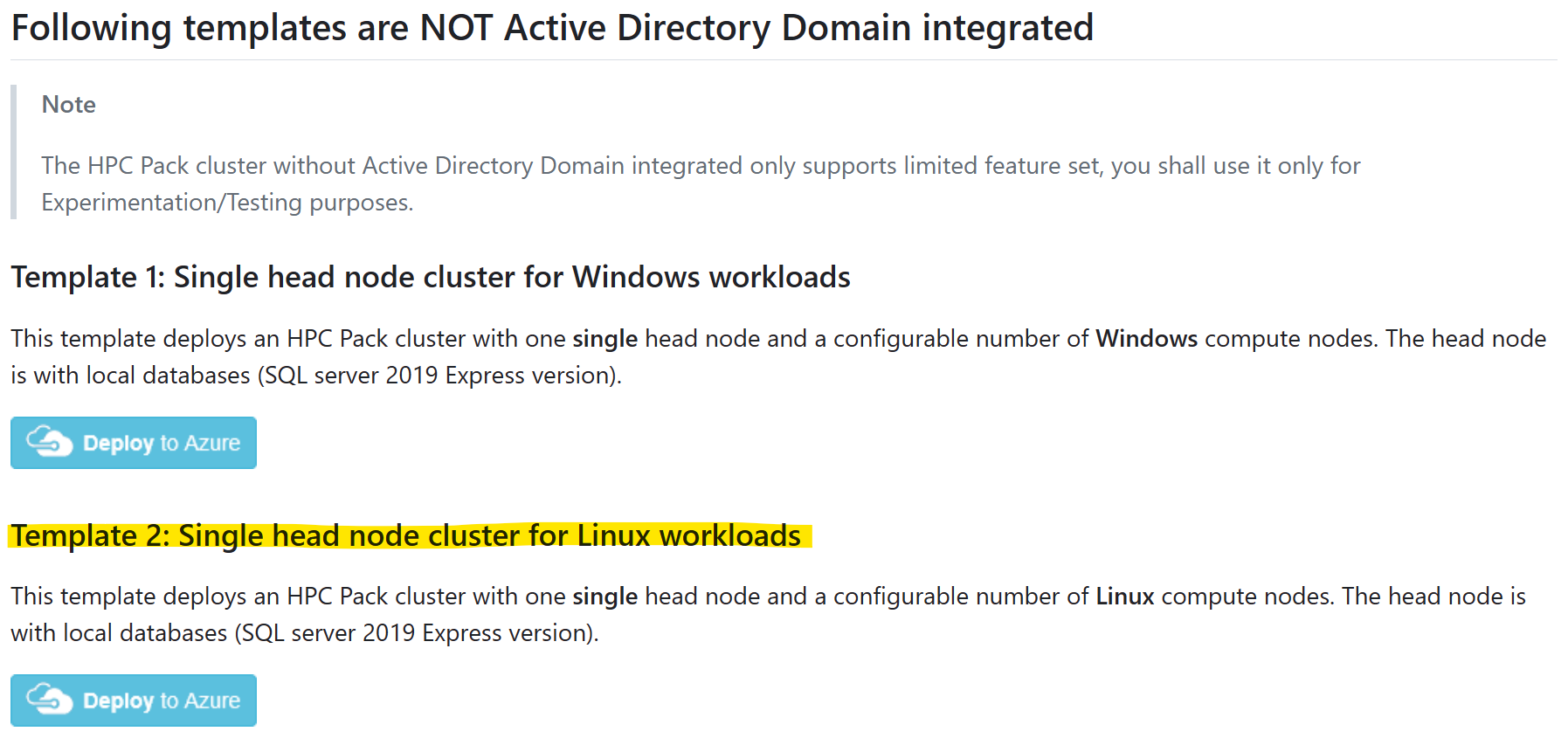
Y consulte el de requisitos previos de
Tenga en cuenta lo siguiente:
Debe seleccionar una imagen de nodo de proceso marcada con "HPC". Esto indica que los controladores de GPU están preinstalados en la imagen. Si no lo hace, se necesitaría la instalación manual del controlador de GPU en un nodo de proceso en una fase posterior, lo que podría resultar una tarea complicada debido a la complejidad de la instalación del controlador de GPU. Puede encontrar más información sobre las imágenes de HPC aquí.
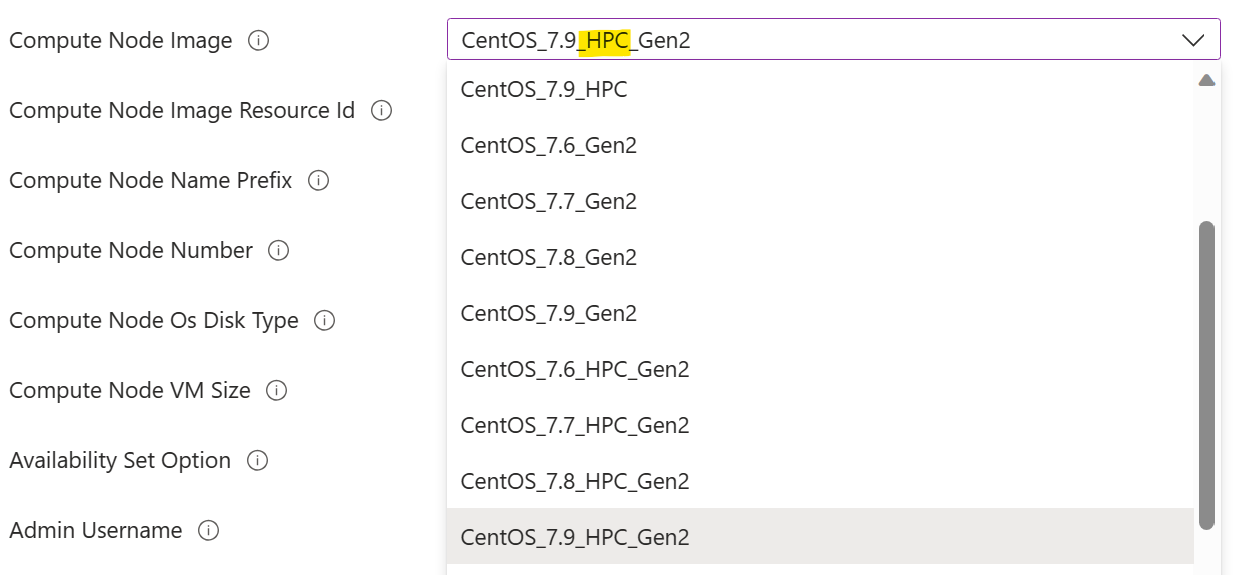
Debe seleccionar un tamaño de máquina virtual de nodo de proceso con GPU. Es tamaño de máquina virtual de la serie N.
 de GPU
de GPU
Instalación de PyTorch en nodos de proceso
En cada nodo de proceso, instale PyTorch con el comando .
pip3 install torch torchvision torchaudio
Sugerencias: puede aprovechar "Ejecutar comando" de HPC Pack para ejecutar un comando en un conjunto de nodos de clúster en paralelo.
Configuración de un directorio compartido
Para poder ejecutar un trabajo de entrenamiento, necesita un directorio compartido al que puedan acceder todos los nodos de proceso. El directorio se usa para el código de entrenamiento y los datos (tanto el conjunto de datos de entrada como el modelo entrenado de salida).
Puede configurar un directorio de recursos compartidos SMB en un nodo principal y, a continuación, montarlo en cada nodo de proceso con cifs, de la siguiente manera:
En un nodo principal, cree un directorio
appen%CCP_DATA%\SpoolDir, que ya está compartido comoCcpSpoolDirpor HPC Pack de forma predeterminada.En un nodo de proceso, monte el directorio
appcomosudo mkdir /app sudo mount -t cifs //<your head node name>/CcpSpoolDir/app /app -o vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777NOTA:
- La opción
passwordse puede omitir en un shell interactivo. Se le pedirá en ese caso. - El
dir_modeyfile_modese establece en 0777, de modo que cualquier usuario de Linux pueda leerlo y escribirlo. Un permiso restringido es posible, pero es más complicado configurarlo.
- La opción
Opcionalmente, haga que el montaje sea permanente mediante la adición de una línea en
/etc/fstabcomo//<your head node name>/CcpSpoolDir/app cifs vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777 0 2Aquí se requiere el
password.
Ejecución de un trabajo de entrenamiento
Supongamos que ahora tenemos dos nodos de proceso de Linux, cada uno con cuatro GPU de NVidia v100. Y hemos instalado PyTorch en cada nodo. También hemos configurado un directorio compartido "app". Ahora podemos iniciar nuestro trabajo de entrenamiento.
Aquí uso un modelo de toy simple basado en PyTorch DDP. Puede obtener el código en GitHub.
Descargue los archivos siguientes en el directorio compartido %CCP_DATA%\SpoolDir\app en el nodo principal
- neural_network.py
- operations.py
- run_ddp.py
A continuación, cree un trabajo con Node como unidad de recursos y dos nodos para el trabajo, como
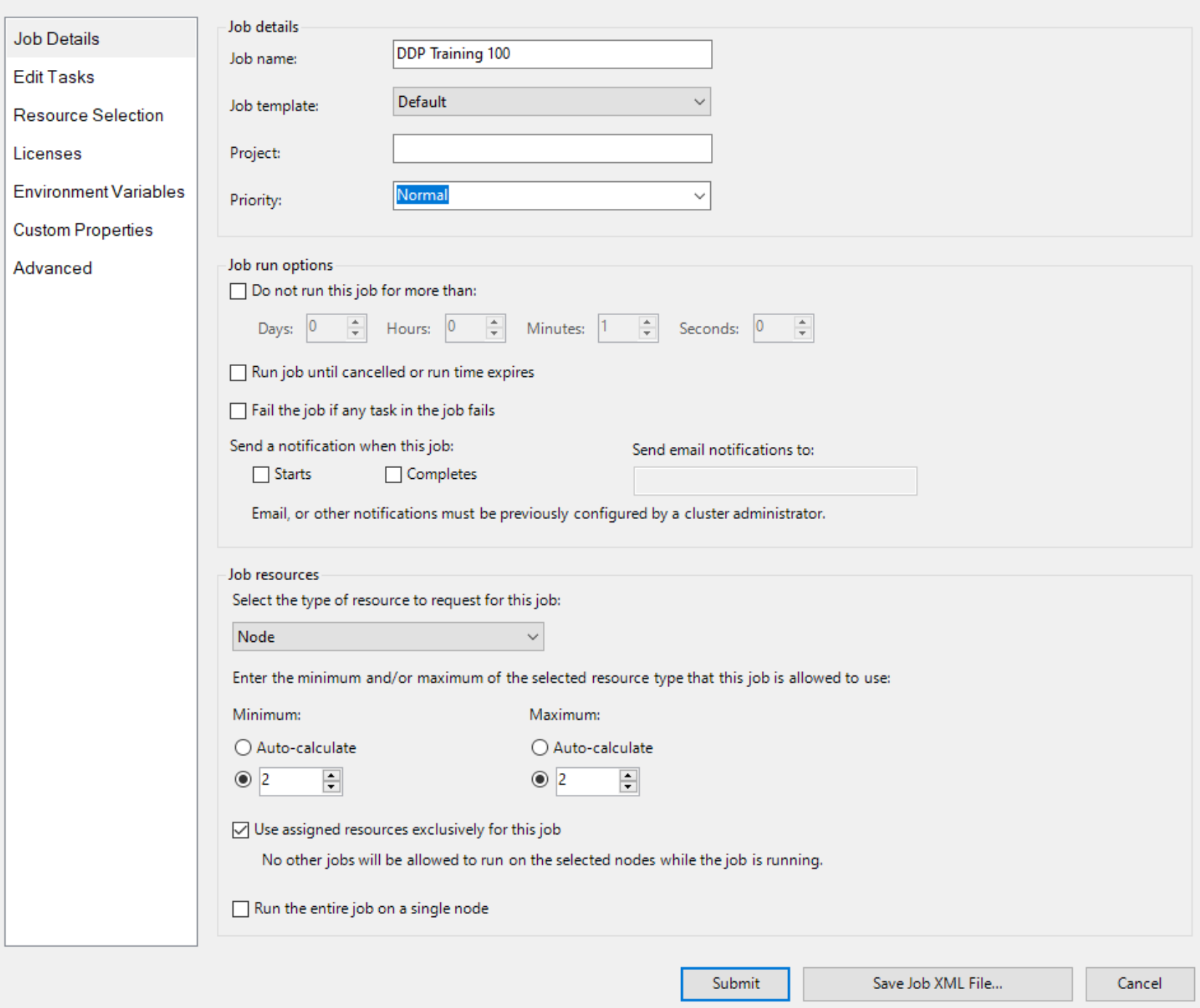
Y especifique dos nodos con GPU explícitamente, como
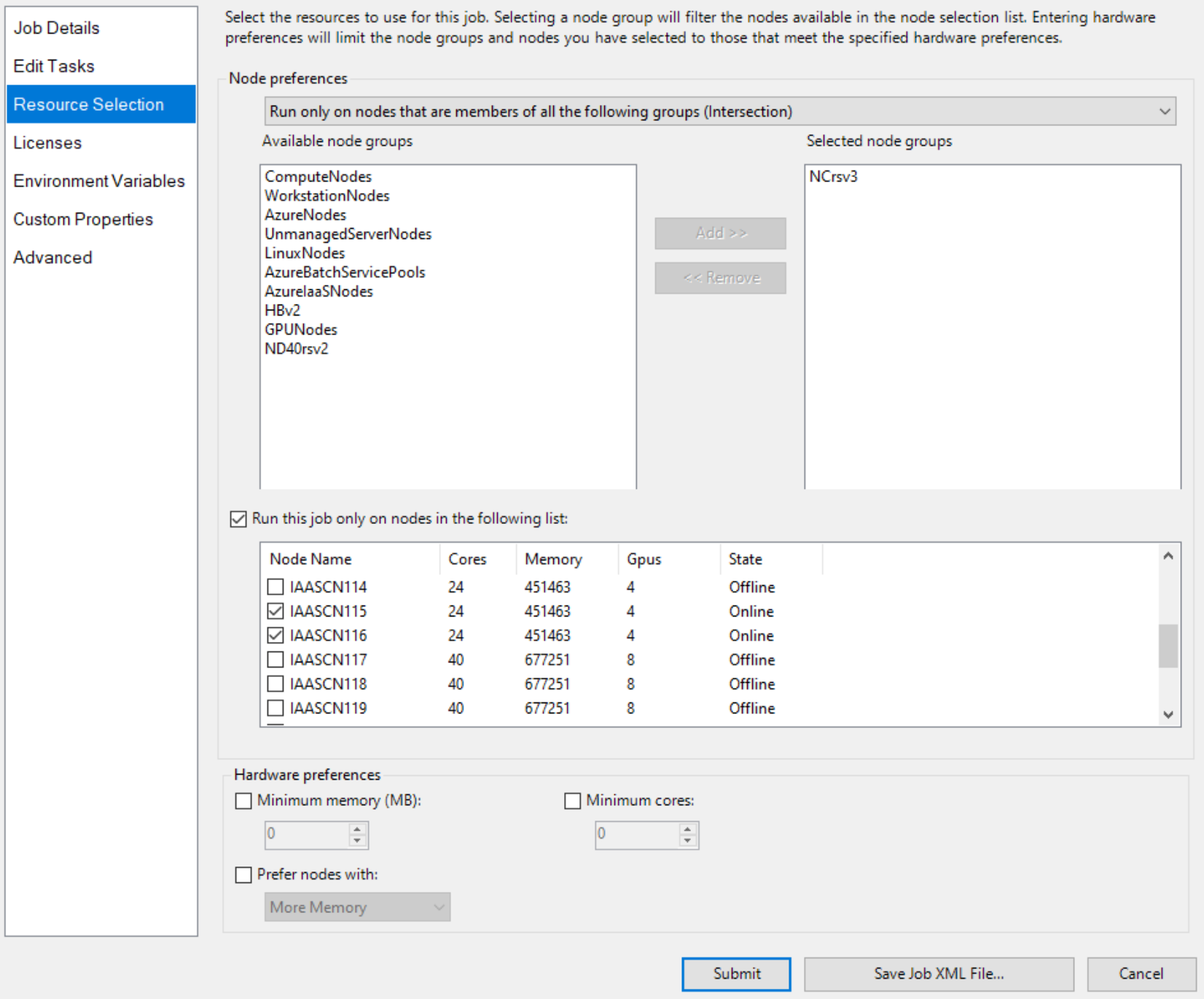 de selección de recursos de trabajo
de selección de recursos de trabajo
A continuación, agregue tareas de trabajo, como
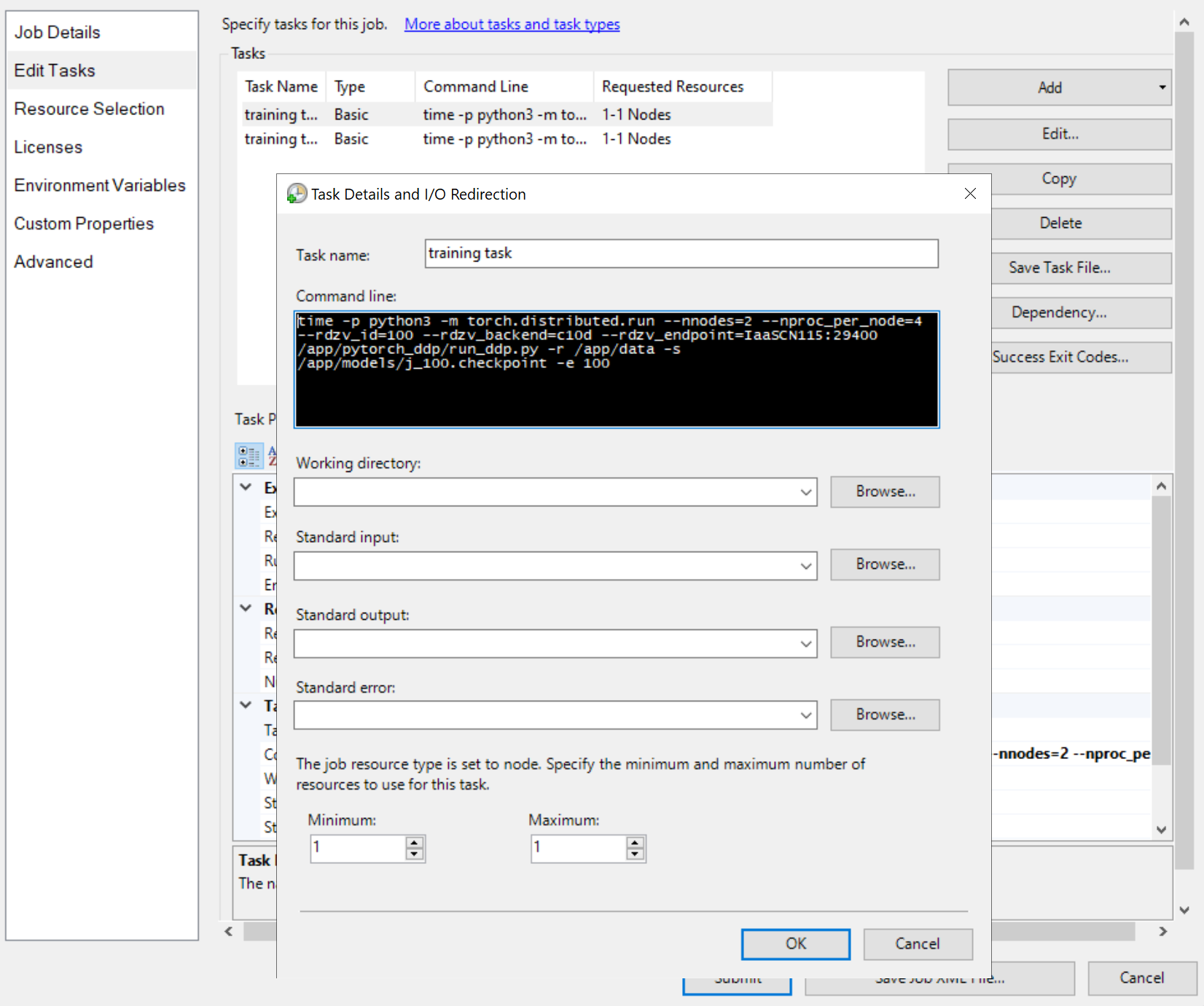
Las líneas de comandos de las tareas son iguales, como
python3 -m torch.distributed.run --nnodes=<the number of compute nodes> --nproc_per_node=<the processes on each node> --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=<a node name>:29400 /app/run_ddp.py
-
nnodesespecifica el número de nodos de proceso para el trabajo de entrenamiento. -
nproc_per_nodeespecifica el número de procesos en cada nodo de proceso. No puede superar el número de GPU en un nodo. Es decir, una GPU puede tener un proceso como máximo. -
rdzv_endpointespecifica un nombre y un puerto de un nodo que actúa como un rendezvous. Cualquier nodo del trabajo de entrenamiento puede funcionar. - "/app/run_ddp.py" es la ruta de acceso al archivo de código de entrenamiento. Recuerde que
/appes un directorio compartido en el nodo principal.
Envíe el trabajo y espere el resultado. Puede ver las tareas en ejecución, como
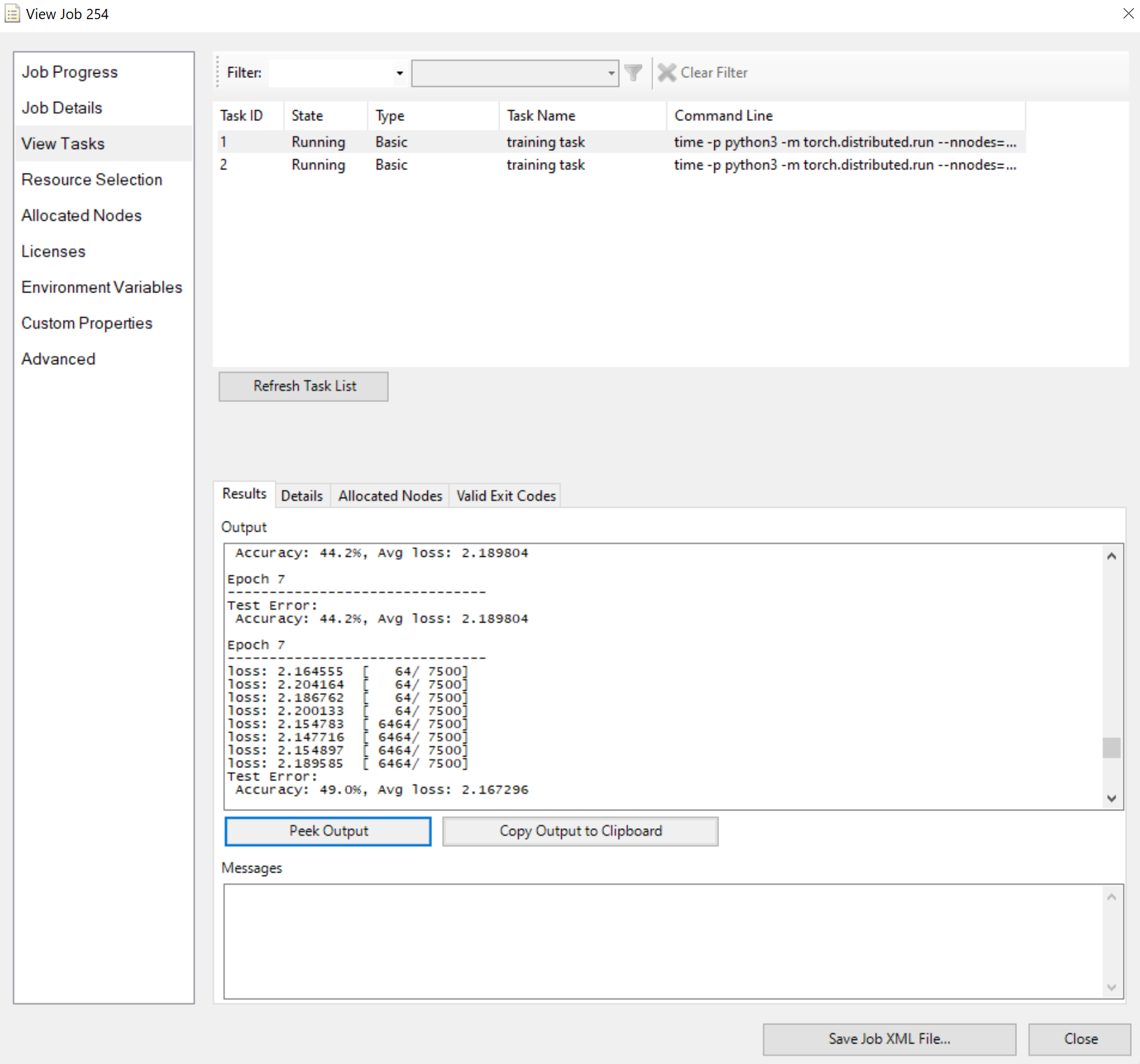
Tenga en cuenta que el panel Resultados muestra la salida truncada si es demasiado larga.
Eso es todo para eso. Espero que obtengas los puntos y HPC Pack puede acelerar tu trabajo de entrenamiento.