Database Capacity Planning and Tuning for Microsoft HPC Pack
The Windows HPC cluster management features in Microsoft HPC Pack rely on several Microsoft SQL Server databases to support management, job scheduling, diagnostic, reporting, and monitoring functionality. When you install HPC Pack on a server to create a head node, the default setup installs the Express edition of Microsoft SQL Server (if no other edition of SQL Server is detected) and creates the necessary databases on the head node. The Express edition has no additional licensing fees, and is included to provide an out-of-box experience for proof-of-concept or development clusters, and for small production clusters. Depending on the size, throughput, and requirements of your cluster, you can install a different edition of SQL Server on the head node or install the databases on remote servers. The information in this document is intended to help you determine the database configuration and additional tuning options that are appropriate for your cluster.
In this topic:
Applicable versions of Microsoft HPC Pack and Microsoft SQL Server
The guidance in this topic applies to the versions of HPC Pack and SQL Server listed in the following table.
| Version of Microsoft HPC Pack | Cluster databases | Supported versions of Microsoft SQL Server | Notes |
|---|---|---|---|
| HPC Pack 2019 | - HPCManagement - HPCScheduler - HPCReporting - HPCDiagnostics - HPCMonitoring - HPCHAStorage - HPCHAWitness |
- SQL Server 2014 and above - Azure SQL Database |
- SQL Server Express version limits each database to 10 GB. - The HPCHAStorage and HPCHAWitness are required only when you choose Single head node mode or Built-in high availability architecture as high availability option. |
| HPC Pack 2016 | - HPCManagement - HPCScheduler - HPCReporting - HPCDiagnostics - HPCMonitoring |
- SQL Server 2014 and above - Azure SQL Database |
- SQL Server Express version limits each database to 10 GB. |
| HPC Pack 2012 R2 and HPC Pack 2012 | - HPCManagement - HPCScheduler - HPCReporting - HPCDiagnostics - HPCMonitoring |
- SQL Server 2008 R2 and above - Azure SQL Database |
- SQL Server Express version limits each database to 10 GB. - Azure SQL Database is supported only for HPC Pack 2012 R2 Update 3 build 4.5.5194 or above |
The basic options for database setup in Microsoft HPC Pack
This section provides background information on three basic options for database setup with HPC Pack. For guidance on choosing a suitable option for your deployment, see Choosing the right edition of SQL Server for your cluster in this topic.
SQL Server Express on the head node
This is the out-of-box experience. This is typically used for proof-of-concept or development clusters, or for small production clusters. As shown in the table in the previous section, if supported by your version of HPC Pack, SQL Server 2016 Express, SQL Server 2014 Express, or SQL Server 2012 Express allows database sizes up to 10 GB. The basic steps for this setup are as follows:
Install HPC Pack on a server to create a head node.
Optionally, specify database and log file locations in the installation wizard (or accept defaults).
SQL Server Express is installed automatically, and the HPC databases are created automatically.
Deploy nodes.
SQL Server Standard on the head node
This is a basic configuration for medium size clusters. SQL Server Standard edition (or another full edition, not Compact) allows larger databases and additional management abilities to support more nodes and higher job throughput. The basic steps for this setup are as follows:
Install a version of SQL Server Standard edition supported by your version of HPC Pack on the server that will act as the head node.
Install HPC Pack on the server to create a head node.
Optionally, specify database and log file locations in the installation wizard (or accept defaults).
The HPC databases are created automatically.
Optionally, tune databases as required by using SQL Server Management Studio.
Deploy nodes.
Remote databases (SQL Server Standard or SQL Server Express)
Installing one or more of the HPC databases on a remote server is a recommended configuration for larger clusters or for clusters that are configured for high availability of the head node. For more information, see Deploying an HPC Pack Cluster with Remote Databases Step-by-Step Guide. For high availability head nodes, you would typically use the Standard edition of SQL Server to support high availability of the databases (which is different than high availability of the HPC management services). For more information, see the Get Started Guide for HPC Pack 2016. The basic steps for this setup are as follows:
Install a version of SQL Server Standard edition supported by your version of HPC Pack on a remote server.
Create the remote HPC databases manually and tune as required using SQL Server Management Studio.
Perform other configuration steps on the remote server running SQL Server as required by your version of HPC Pack.
Install HPC Pack on a server to create a head node.
In the installation wizard, specify the connection information for the remote databases.
Deploy nodes.
Choosing the right edition of SQL Server for your cluster
The following general guidelines can help you determine which edition of SQL Server to use for your cluster. The node and job throughput numbers are meant as general guidelines only, as performance will vary according to the hardware and topology that you select for the cluster, and the workload that your cluster supports.
Consider using the Standard edition (or another full edition, not Compact) of SQL Server if any of the following conditions apply:
The cluster has many nodes. Information such as node properties, configurations, metrics, and performance history are stored in the databases. Larger clusters require more room in the databases. As a general guideline, the Express edition is sufficient for up to 64 nodes with SQL Server Express 2012, or up to 128 nodes with a later version of SQL Server Express.
The cluster supports a very high rate of job throughput - for example, greater than 10,000 tasks or subtasks per day. Every job, task, and subtask has entries in the database to store properties and allocation information and history. The default retention period for this data is 5 days. You can adjust the retention period to reduce your capacity requirements. See HPC data retention settings in this topic.
The cluster is configured for high availability of the head node and you also want to configure high availability for SQL Server.
You need to store job and task data in the HPCScheduler database for an extended period of time and will exceed the database limit imposed by your version of SQL Server Express.
You use the HPCReporting database heavily, and possibly use the data extensibility features for custom reporting. For information about disabling the reporting extensibility and reducing the size requirements for the reporting database, see HPC data retention settings in this topic.
You require the additional reliability, performance, and flexibility provided by the SQL Server Management Studio tools (including support for maintenance plans). For example, SQL Server Standard edition provides the following features (among others) that can be helpful to HPC cluster administrators:
Unlimited database size
Support for high-availability configurations
Unlimited RAM usage for database caching
Note
SQL Server Management Studio is not automatically included with the Express edition of SQL Server. You can download it separately if you want to change settings for your HPC databases.
You are planning a large deployment of Windows Azure nodes – for example, several hundred Windows Azure role instances or more. For more information about large Windows Azure node deployments, see Best Practices for Large Deployments of Windows Azure Nodes with Microsoft HPC Pack.
Configuration and tuning best practices
This section includes some guidelines and best practices for performance tuning the HPC databases. Sample configuration settings for a larger scale cluster are outlined in the list below. These settings in some cases differ considerably from those configured by default by HPC Pack. More information about these options is provided in the sections that follow.
On a server with three platters (physical disks) configure:
The operating system on a dedicated platter.
The cluster databases on a dedicated platter.
The cluster database log files on a dedicated platter.
In SQL Server Management Studio configure:
HPCManagement database: Initial size 20 GB, grow rate 100%
HPCManagement database logs: Initial size 2 GB
HPCScheduler database: Initial size 30 GB, grow rate 0%
Note
In a large cluster, to prevent unexpected shutdown of the HPC job scheduler due to the HPCScheduler database approaching its size limits, we recommend that you do not configure autogrowth settings for this database.
HPCScheduler database logs: Initial size 2 GB
HPCReporting database: Initial size 30 GB, grow rate 100%
HPCReporting database logs: Initial size 2 GB
HPCDiagnostics database and logs: Use defaults
HPCMonitoring database: 1 GB, grow rate 10%
HPCMonitoring database logs: Use defaults
HPCHAStorage database: Use defaults
HPCHAStorage database logs: Use defaults
HPCHAWitness database: Use defaults
Important
If you choose to enable built-in high availability architecture, make sure the HPCHAWitness database is created in a highly available SQL server instance.
HPCHAWitness database logs: Use defaults
For databases that are hosted on the head node, in SQL Server Management Studio, configure the memory for the database to be approximately one-half the physical memory on the node. For example, for a head node with 16 GB of physical memory, configure database sizes of 8-10 GB.
For databases that are hosted on the head node, in SQL Server Management Studio, set the parallelization flag to 1 (0 is the default).
SQL Server recovery model and disk space requirements
By default in SQL Server Standard edition, the SQL Server recovery model for each database is set to Full. This model can cause the log files to grow very large because of the manual maintenance that is required. To reclaim log space and keep the disk space requirements small, you can change the recovery model for each database to Simple. The recovery model that you select depends on your recovery requirements. If you use the Full model, ensure that you plan enough space for the log files, and be aware of the regular maintenance requirements. For more information, see Recovery Model Overview.
Note
If you choose the Full model, because the HPC databases must remain logically consistent, you may have to implement special procedures to ensure the recoverability of these databases. For more information, see Recovery of Related Databases That Contain Marked Transactions.
Initial sizing and autogrowth for databases and log files
Autogrowth means that when a database or log file runs out of space, it will automatically increase its size by a predefined percentage (as defined by the autogrowth parameter). During the autogrowth process, the database is locked. This impacts cluster operations and performance, and can cause operation deadlocks and timeouts. Pre-sizing your databases helps you avoid these performance issues, and by configuring a larger autogrowth percentage, you reduce the frequency of the autogrowth operations. However, a large initial file sized coupled with an autogrowth setting that approaches 100% can require a significant amount of time to grow the database. It is important to understand the performance of your disk subsystem in order to determine values that do not block access to the database for an extended period.
Each database has an associated log file. You can also tune the initial size and autogrowth settings of the log files.
The default configurations for the databases and log files (regardless of SQL Server edition) are shown in the following table:
| HPC database and log | Initial size (MB) | Autogrowth |
|---|---|---|
| HPCManagement | Database: 1024 Log: 128 |
Database: 50% Log: 50% |
| HPCScheduler | Database: 256 Log: 64 |
Database: 10% Log: 10% |
| HPCReporting | Database: 128 Log: 64 |
Database: 10% Log: 10% |
| HPCDiagnostics | Database: 256 Log: 64 |
Database: 10% Log: 10% |
| HPCMonitoring | Database: 256 Log: 138 |
Database: 10% Log: 10% |
| HPCHAStorage | Database: 32 Log: 16 |
Database: 10% Log: 10% |
| HPCHAWitness | Database: 32 Log: 16 |
Database: 10% Log: 10% |
As an example, the following table lists initial size and autogrowth settings that might be appropriate for a cluster with several hundred or more nodes.
Note
The initial size in this table is expressed in gigabytes (GB), not megabytes (MB) as in the previous table.
| HPC database and log | Initial size (GB) | Autogrowth |
|---|---|---|
| HPCManagement | Database: 20 Log: 2 |
Database: 100% Log: 10% |
| HPCScheduler | Database: 30 Log: 2 |
Database: 0% Log: 10% |
| HPCReporting | Database: 30 Log: 2 |
Database: 100% Log: 10% |
| HPCDiagnostics | Database: default Log: default |
Database: default Log: default |
| HPCMonitoring | Database: 1 Log: default |
Database: default Log: default |
| HPCHAStorage | Database: default Log: default |
Database: default Log: default |
| HPCHAWitness | Database: default Log: default |
Database: default Log: default |
The following screen snip illustrates the HPC databases in the SQL Server Management Studio, and the database properties dialog box that you can use to configure initial size and autogrowth settings for the databases.
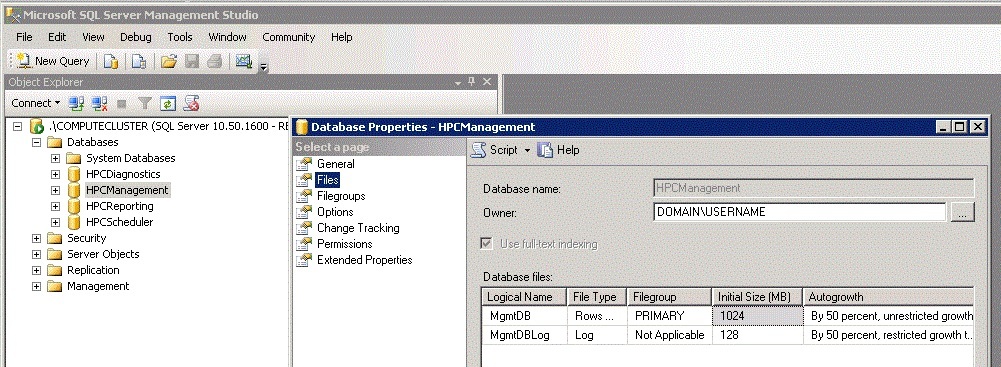
Database and log file location
You can improve performance by creating the databases on a separate platter (physical disk) than the log files. This applies to databases that are on the head node and to remote databases. For databases on the head node, you can specify the database and log file locations during setup (in the installation wizard). Ideally, place the system partition, data, and logs on separate platters.
If reporting is heavily used, consider moving the HPCReporting database to a separate platter.
For information about moving a database, see Move a Database Using Detach and Attach (Transact-SQL).
SQL Server instance settings
To minimize memory paging, ensure that your SQL Server instance has a sufficient allocation of memory. You can set the memory for your SQL Server instance through SQL Server Management Studio, in the Server Properties for the instance. For example, if your databases are on a head node that has 16 GB of memory, you might want to allocate 8-10 GB for SQL Server.
To minimize core contention on the head node between SQL Server processes and HPC processes, set the parallelization flag for the SQL Server instance to 1. By default, the flag is set to 0, which means that there are no limits to how many cores SQL will use. By setting it to 1, you limit SQL Server processes to 1 core.
HPC data retention settings
HPCManagement database
Starting with HPC Pack 2012 R2 Update 1, the cluster admin is able to specify the number of days before the service starts to archive operation log data in the HPCManagement database and the number of days that the archived operation log data is retained. For example, to set the operation log archive every 7 days and to be deleted after retention for 180 days, run HPC Powershell as an administrator and type the following cmdlet:
Set-HpcClusterProperty –OperationArchive 7
Set-HpcClusterProperty –OperationRetention 180
HPCScheduler database
Job properties, allocation, and history are stored in the HPCScheduler database. By default, data about completed jobs is kept for five days. The job record retention period (TtlCompletedJobs) determines how long to store data for the following records:
Data about completed jobs (Finished, Failed, or Canceled) in the HPCScheduler database.
SOA common data stored in the Runtime$ share.
Diagnostic test results and data in the HPCDiagnostics database.
Messages for completed durable sessions that are stored by the broker node using MSMQ.
Jobs that are in the Configuring state are not deleted from the database. The jobs must be canceled by the job owner or a cluster administrator (or completed in some other way) and then they will be deleted according to the job history policy.
You can configure this property by using the Set-HpcClusterProperty cmdlet. For example, to set the job record retention period to three days, run HPC PowerShell as an administrator and type the following cmdlet:
Set-HpcClusterProperty –TtlCompletedJobs 3
This property can also be configured in the Job History settings of the HPC Job Scheduler configuration dialog box.
HPCReporting database
Historical data about the cluster such as cluster utilization, node availability, and job statistics is aggregated and stored in the HPCReporting database. The database also stores raw data about jobs that is available to support custom reporting when data extensibility is enabled (it is enabled by default). For example, you can create custom charge back reports that correspond to the charging methods that are used by your organization. For information about using the raw data for custom reporting, see the Reporting Extensibility Step-by-Step Guide.
The following table describes the cluster properties that control the data extensibility and retention periods for the raw data. These settings do not affect the aggregated data that is used for the built-in reports. You can view the values of the properties with the Get-HPCClusterProperty cmdlet and set the values with the Set-HpcClusterProperty cmdlet. For example, to disable data extensibility, run HPC PowerShell as an administrator and type the following cmdlet:
Set-HpcClusterProperty –DataExtensibilityEnabled $false
| Property | Description |
|---|---|
| DataExtensibilityEnabled | Specifies whether the cluster stores information for custom reporting about jobs, nodes, and the allocation of jobs to nodes. True indicates that the cluster stores information for custom reporting about jobs, nodes, and the allocation of jobs to nodes. False indicates that the cluster does not store this information. The default value is True. |
| DataExtensibilityTtl | Specifies the number of days that the HPCReporting database should store all of the information about jobs and nodes except for the allocation of jobs to nodes. This parameter has a default value of 365. |
| AllocationHistoryTtl | Specifies the number of days that the HPCReporting database should store information about the allocation of jobs to nodes. This parameter has a default value of 5. |
| ReportingDBSize | Contains the current size of the HPCReporting database. This value is a string that includes the units of measurement for the size. This parameter is read-only. To view this property, the computer that is running HPC PowerShell must be able to access the HPCReporting database. For more information about enabling remote database access, see Deploying a Cluster with Remote Databases Step-by-Step Guide. |
If you want to estimate the size needed for the HPCReporting database in your cluster, see Estimating the Size of the Reporting Database.
HPCDiagnostics database
Information and results from diagnostic test runs are stored in the HPCDiagnostics database. The job record retention period (TtlCompletedJobs) determines how long to store data about completed test runs.
HPCMonitoring database
Performance counter data collected and aggregated from cluster nodes by the HPC Monitoring Server Service and the HPC Monitoring Client Service is stored in the HPCMonitoring database.
Performance counter data is aggregated by minute, by hour, and by day. The data retention period for the node performance counter data is defined by the cluster properties in the following table. You can configure these properties by using the Set-HpcClusterProperty cmdlet.
| Property | Description |
|---|---|
| MinuteCounterRetention | Specifies the retention period in days for the minute performance counter data. The default value is 3 days. |
| HourCounterRetention | Specifies the retention period in days for the hour performance counter data. The default value is 30 days. |
| DayCounterRetention | Specifies the retention period in days for the day performance counter data. The default value is 180 days. |
You can estimate the size needed for the HpcMonitoring database based on the number of nodes, the number of performance counters, and the retention period. For example, using a default MinuteCounterRetention period of 3 days (4,320 minutes), and 27 performance counters with each performance value entry requiring approximately 40 bytes, each node would require:
4,320 x 27 x 40 = 4,665,600 bytes, or approximately 5 MB.
For a cluster with 1000 nodes, approximately 5 GB of storage would be required.
Maintenance guidelines
A typical SQL Server maintenance plan covers the following:
Database backup
Consistency checks
Index defragmentation
You can monitor index fragmentation by using the SQL Server Management Studio and defragment indexes when appropriate through a maintenance plan.
We generally recommend that you rebuild your indexes after 250,000 jobs or one month (whichever is shorter), if not more often. How often you do consistency checks and backups will depend on your business requirements. We recommend running maintenance only when there is little to no user activity, preferably during a scheduled downtime (especially for larger clusters), as it can severely impact job throughput and user experience.
For information about database maintenance best practices, see Top Tips for Effective Database Maintenance.
Note
For important information about backing up and restoring the HPC databases, see Back Up and Restore in Windows HPC Server.