TripPin, parte 5: paginación
En este tutorial de varias partes se describe la creación de una nueva extensión de origen de datos para Power Query. El tutorial está diseñado para seguirse secuencialmente: cada lección se basa en el conector creado en las lecciones anteriores, agregando incrementalmente nuevas funcionalidades al conector.
En esta lección, aprenderá lo siguiente:
- Adición de compatibilidad con la paginación al conector
Muchas API Rest devuelven datos en "páginas", lo que requiere que los clientes realicen varias solicitudes para unir los resultados. Aunque hay algunas convenciones comunes para la paginación (como RFC 5988), suele variar según cada API. Afortunadamente, TripPin es un servicio de OData y el estándar OData define una manera de llevar a cabo la paginación mediante los valores de odata.nextLink devueltos en el cuerpo de la respuesta.
Para simplificar las iteraciones anteriores del conector, la función TripPin.Feed no tenía en cuenta las páginas. Simplemente analizaba el código JSON que se devolvía de la solicitud y lo formatea en forma de tabla. Las personas familiarizadas con el protocolo OData podrían haber observado que se realizaron varias suposiciones incorrectas sobre el formato de la respuesta (por ejemplo, suponer que hay un campo value que contiene una matriz de registros).
En esta lección, mejorará la lógica de control de respuestas haciendo que tenga en cuenta las páginas. En tutoriales futuros se hace que la lógica de control de páginas sea más sólida y capaz de controlar varios formatos de respuesta (incluidos errores del servicio).
Nota:
No es necesario implementar su propia lógica de paginación con conectores basados en OData.Feed, ya que lo controla todo automáticamente.
Lista de comprobación de paginación
Al implementar la compatibilidad con la paginación, deberá saber lo siguiente sobre la API:
- ¿Cómo se solicita la siguiente página de datos?
- ¿El mecanismo de paginación implica el cálculo de valores o se extrae la dirección URL de la página siguiente a partir de la respuesta?
- ¿Cómo se determina el momento en que se debe detener la paginación?
- ¿Hay parámetros relacionados con la paginación que se deban tener en cuenta? (por ejemplo, "tamaño de página")
La respuesta a estas preguntas afecta a la forma en que implemente la lógica de paginación. Aunque se reutiliza cierta cantidad de código entre implementaciones de paginación (como el uso de Table.GenerateByPage), la mayoría de los conectores terminarán necesitando lógica personalizada.
Nota:
Esta lección contiene lógica de paginación para un servicio OData, que sigue un formato específico. Consulte la documentación de la API para determinar los cambios que deberá realizar en el conector para que sea compatible con su formato de paginación.
Información general sobre la paginación de OData
La paginación de OData se basa en anotaciones nextLink contenidas en la carga de respuesta. El valor nextLink contiene la dirección URL de la siguiente página de datos. Sabrá si hay otra página de datos buscando un campo odata.nextLink en el objeto más externo de la respuesta. Si no hay ningún campo odata.nextLink, significa que ya ha leído todos los datos.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
Algunos servicios de OData permiten a los clientes proporcionar una preferencia de tamaño máximo de página, pero depende del servicio si se debe respetar o no. Power Query debe ser capaz de controlar respuestas de cualquier tamaño, por lo que no es necesario preocuparse por especificar una preferencia de tamaño de página; puede admitir lo que el servicio produzca.
Encontrará más información sobre Paginación controlada por servidor en la especificación de OData.
Prueba de TripPin
Antes de corregir la implementación de la paginación, confirme el comportamiento actual de la extensión del tutorial anterior. La siguiente consulta de prueba recupera la tabla People y agrega una columna de índice para mostrar el recuento de filas actual.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Active Fiddler y ejecute la consulta en el SDK de Power Query. Observe que la consulta devuelve una tabla con ocho filas (índice 0 a 7).
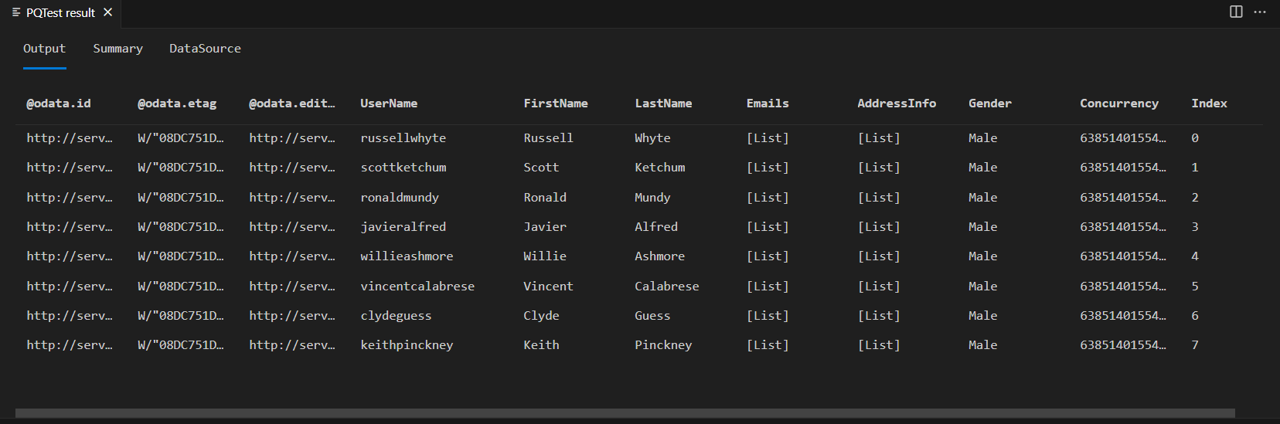
Si observa el cuerpo de la respuesta de Fiddler, verá que, de hecho, contiene un campo @odata.nextLink, lo que indica que hay más páginas de datos disponibles.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
Implementación de la paginación para TripPin
Ahora va a realizar los siguientes cambios en la extensión:
- Importación de la función común
Table.GenerateByPage - Adición de una función
GetAllPagesByNextLinkque usaTable.GenerateByPagepara unir todas las páginas - Adición de una función
GetPageque puede leer una sola página de datos - Adición de una función
GetNextLinkpara extraer la siguiente dirección URL de la respuesta - Actualización de
TripPin.Feedpara usar las nuevas funciones de lector de páginas
Nota:
Como se indicó anteriormente en este tutorial, la lógica de paginación variará según el origen de datos. Aquí la implementación intenta dividir la lógica en funciones que deben ser reutilizables para los orígenes que usan los vínculos siguientes devueltos en la respuesta.
Table.GenerateByPage
Para combinar (potencialmente) varias páginas devueltas por el origen en una sola tabla, usaremos Table.GenerateByPage. Esta función toma como argumento una función getNextPage que debe hacer exactamente lo que su nombre indica: capturar la siguiente página de datos. Table.GenerateByPage llamará repetidamente a la función getNextPage, pasándole cada vez los resultados producidos la última vez que llamó a dicha función, hasta que devuelva null para indicar que no hay más páginas disponibles.
Puesto que esta función no forma parte de la biblioteca estándar de Power Query, deberá copiar su código fuente en el archivo .pq.
Implementación de GetAllPagesByNextLink
El cuerpo de la función GetAllPagesByNextLink implementa el argumento de función getNextPage para Table.GenerateByPage. Llamará a la función GetPage y recuperará la dirección URL de la página siguiente de datos del campo NextLink del registro meta de la llamada anterior.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
Implementación de GetPage
La función GetPage usará Web.Contents para recuperar una sola página de datos del servicio TripPin y convertir la respuesta en una tabla. Pasa la respuesta de Web.Contents a la función GetNextLink para extraer la dirección URL de la página siguiente y la establece en el registro meta de la tabla devuelta (página de datos).
Esta implementación es una versión ligeramente modificada de la llamada TripPin.Feed de los tutoriales anteriores.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
Implementación de GetNextLink
La función GetNextLink simplemente comprueba el cuerpo de la respuesta de un campo @odata.nextLink y devuelve su valor.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
Resumen
El último paso para implementar la lógica de paginación es actualizar TripPin.Feed para usar las nuevas funciones. Por ahora, simplemente llama a GetAllPagesByNextLink, pero en tutoriales posteriores, agregará nuevas funcionalidades (como aplicar un esquema y lógica de parámetros de consulta).
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
Si vuelve a ejecutar la misma consulta de prueba anterior en el tutorial, ahora debería ver el lector de páginas en acción. También debería ver que tiene 24 filas en la respuesta en lugar de ocho.
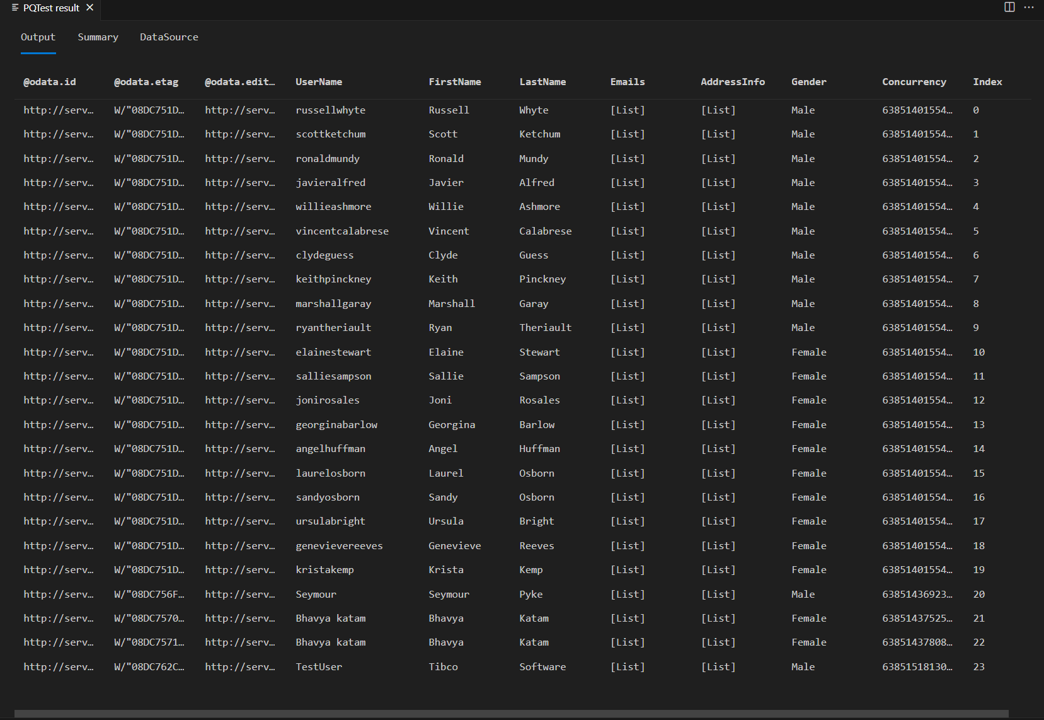
Si observa las solicitudes en Fiddler, ahora debería ver solicitudes independientes para cada página de datos.
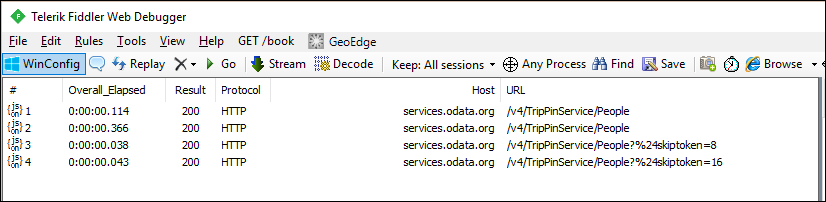
Nota:
Observará que hay solicitudes duplicadas para la primera página de datos del servicio, que no es lo ideal. La solicitud adicional es el resultado del comportamiento de comprobación de esquemas del motor M. Pase por alto este problema por ahora y resuélvalo en el siguiente tutorial, donde aplicará un esquema explícito.
Conclusión
En esta lección se ha visto cómo implementar la compatibilidad con la paginación para una API Rest. Aunque la lógica probablemente variará según la API, el patrón establecido aquí se debe poder reutilizar con pequeñas modificaciones.
En la siguiente lección, verá cómo aplicar un esquema explícito a los datos, yendo más allá de los tipos de datos simples text y number que obtiene de Json.Document.