Ejemplos de plegado de consultas
En este artículo se proporcionan algunos escenarios a modo de ejemplo para cada uno de los tres resultados posibles para el plegado de consultas. También se incluyen algunas sugerencias sobre cómo sacar el máximo partido del mecanismo de plegado de consultas y el efecto que puede tener dicho mecanismo en las consultas.
El escenario
Imagine un escenario en el que, con la base de datos Wide World Importers para SQL Database de Azure Synapse Analytics, se le asigna la tarea de crear una consulta en Power Query que se conecte a la tabla fact_Sale y que recupere las últimas 10 ventas con solo los siguientes campos:
- Clave de venta
- Clave de cliente
- Clave de fecha de factura
- Descripción
- Cantidad
Nota:
Para fines de demostración, en este artículo se usa la base de datos que se describe en el tutorial sobre cómo cargar la base de datos Wide World Importers en Azure Synapse Analytics. La principal diferencia de este artículo es que la tabla fact_Sale solo contiene datos para el año 2000, con un total de 3.644.356 filas.
Aunque es posible que los resultados no coincidan exactamente con los resultados que se obtienen al seguir el tutorial de la documentación de Azure Synapse Analytics, el objetivo de este artículo es mostrar los conceptos básicos y el impacto que el plegado de consultas puede tener en las consultas.
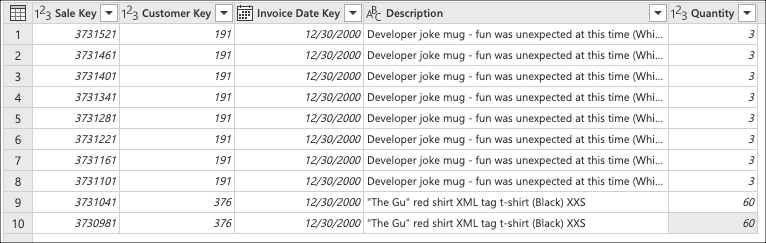
En este artículo se muestran tres formas de lograr el mismo resultado con distintos niveles de plegado de consultas:
- Sin plegado de consultas
- Plegado parcial de consultas
- Plegado completo de consultas
Ejemplo sin plegado de consultas
Importante
Las consultas que dependen únicamente de orígenes de datos no estructurados o que no tienen un motor de proceso, como los archivos CSV o Excel, no tienen funcionalidades de plegado de consultas. Esto significa que Power Query evalúa todas las transformaciones de datos necesarias mediante el motor de Power Query.
Después de conectarse a la base de datos y navegar a la tabla fact_Sale, seleccione la transformación Mantener filas inferiores que se encuentra dentro del grupo Reducir filas de la pestaña Inicio.
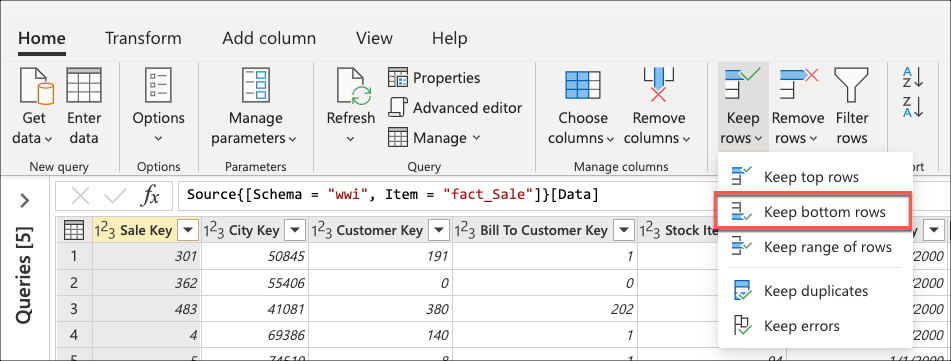
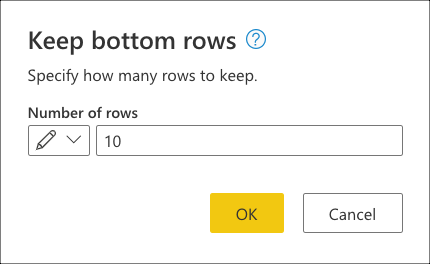
Después de seleccionar esta transformación, aparecerá un cuadro de diálogo nuevo. En este nuevo cuadro de diálogo, puede escribir el número de filas que desea mantener. En este caso, escriba el valor 10 y seleccione Aceptar.
Sugerencia
En este caso, esta operación producirá el resultado de las diez últimas ventas. En la mayoría de los escenarios, se recomienda proporcionar una lógica más explícita que defina las filas que se consideran en último lugar; para ello se debe aplicar una operación de ordenación en la tabla.
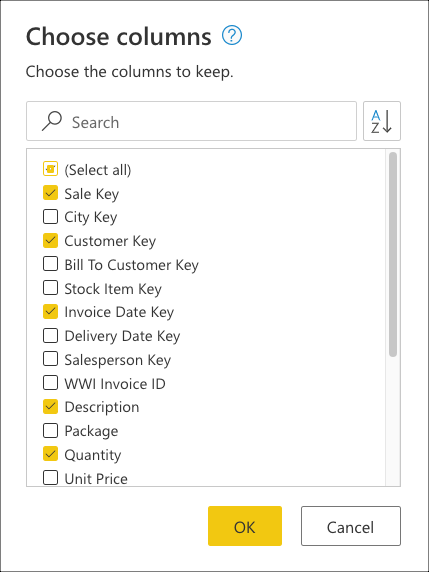
A continuación, seleccione la transformación Elegir columnas que se encuentra dentro del grupo Administrar columnas de la pestaña Inicio. A continuación, puede seleccionar las columnas que desea mantener de la tabla y quitar el resto.
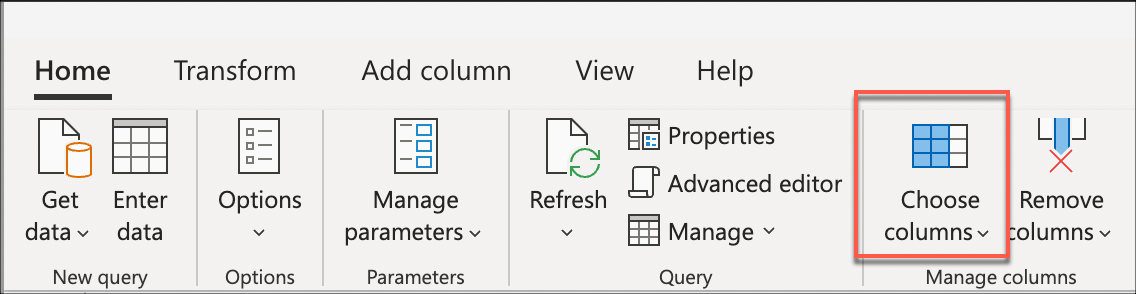
Por último, dentro del cuadro de diálogo Elegir columnas, seleccione las columnas Sale Key, Customer Key, Invoice Date Key, Description y Quantity, y a continuación, seleccione Aceptar.
El ejemplo de código siguiente es el script M completo para la consulta que creó:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(#"Kept bottom rows", {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"})
in
#"Choose columns""
Sin plegado de consultas: descripción de la evaluación de consultas
En Pasos aplicados en el editor de Power Query, observará que los indicadores de plegado de consulta para Filas inferiores mantenidas y Elegir columnas se marcan como pasos que se evaluarán fuera del origen de datos o, en otras palabras, mediante el motor de Power Query.
Puede hacer clic con el botón derecho en el último paso de la consulta, el que se denomina Elegir columnas, y, a continuación, seleccionar la opción en la que se lee Ver plan de consulta. El objetivo del plan de consulta es proporcionarle una vista detallada de cómo se ejecuta la consulta. Para obtener más información sobre esta característica, diríjase a Plan de consulta.
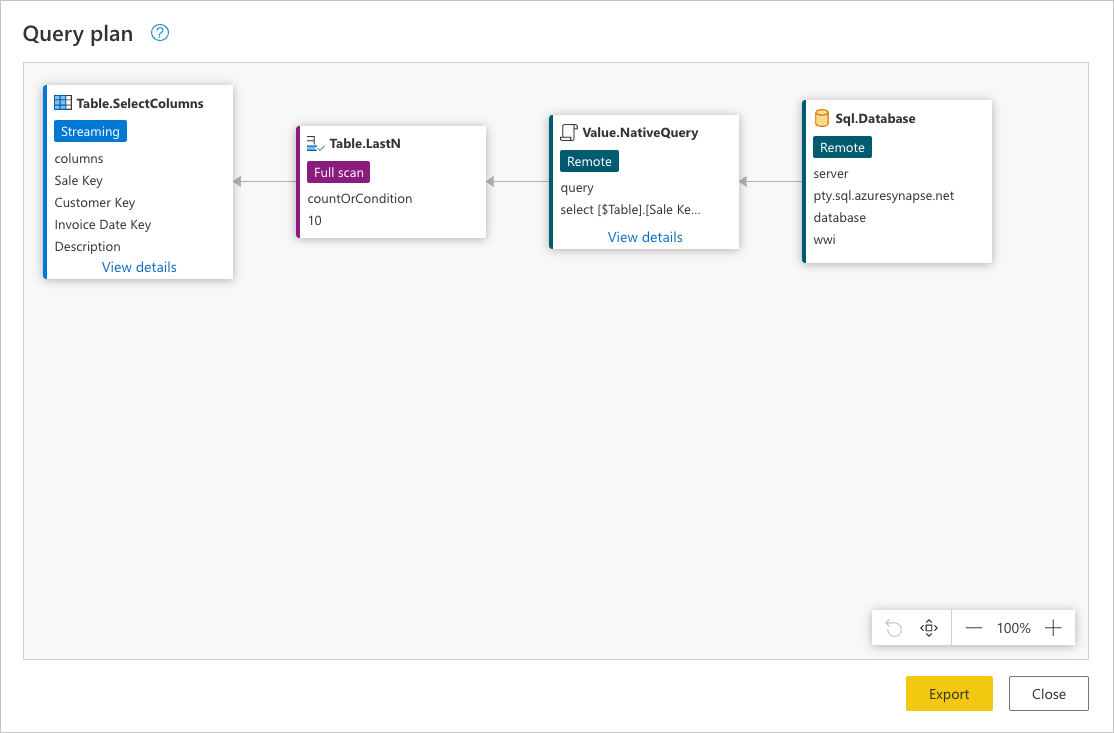
Cada cuadro de la imagen anterior se denomina nodo. Un nodo representa el desglose de la operación para completar esta consulta. Los nodos que representan orígenes de datos, como SQL Server en el ejemplo anterior y el nodo Value.NativeQuery, representan qué parte de la consulta se descarga en el origen de datos. El resto de los nodos, en este caso Table.LastN y Table.SelectColumns resaltados en el rectángulo de la imagen anterior, se evalúan mediante el motor de Power Query. Estos dos nodos representan las dos transformaciones que usted agregó, Filas inferiores mantenidas y Elegir columnas. El resto de los nodos representan las operaciones que se producen en el nivel de origen de datos.
Para ver la solicitud exacta que se envía al origen de datos, seleccione Ver detalles en el nodo Value.NativeQuery.
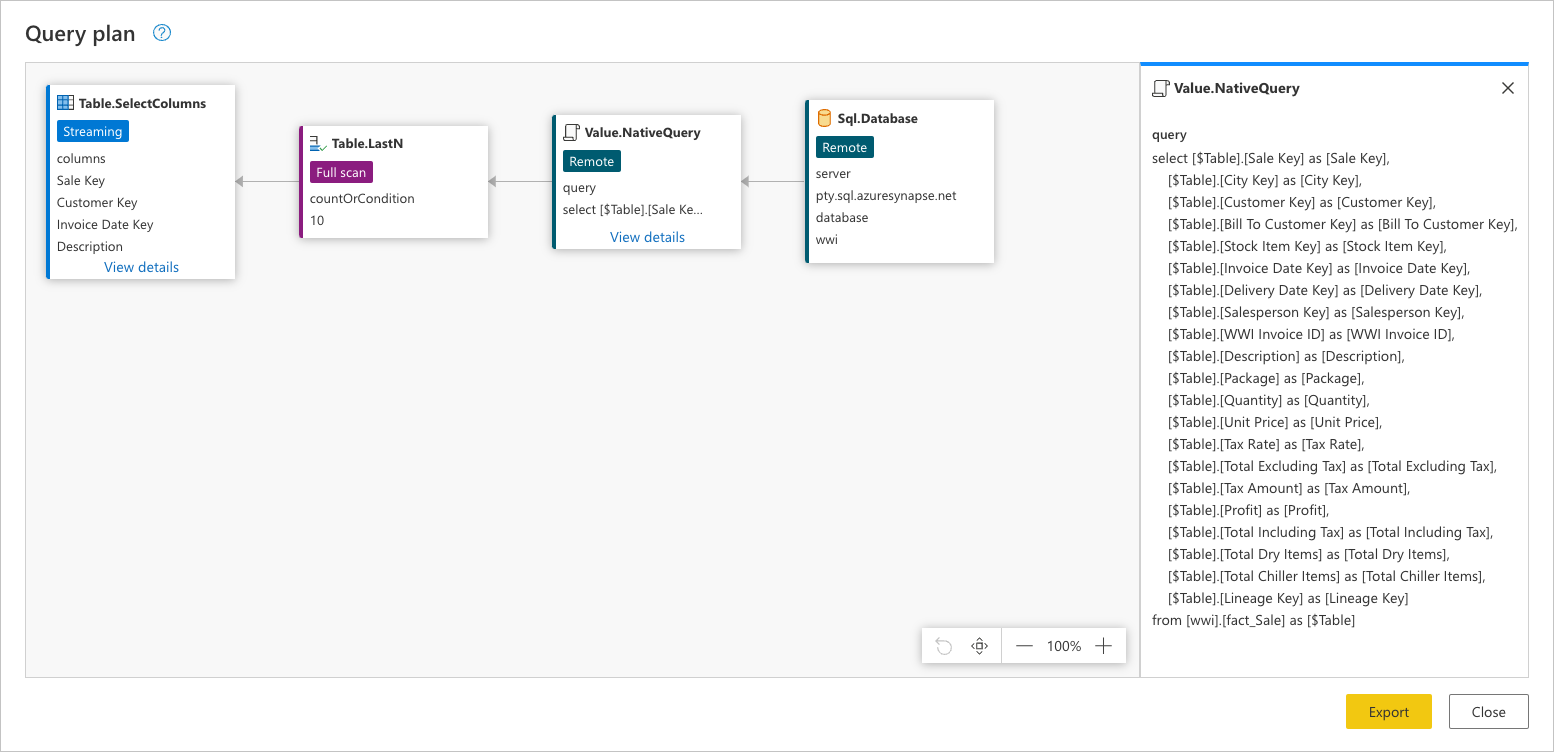
Esta solicitud de origen de datos está en el lenguaje nativo del origen de datos. En este caso, ese lenguaje es SQL y esta instrucción representa una solicitud para todas las filas y campos de la tabla fact_Sale.
Consultar esta solicitud de origen de datos puede ayudarle a comprender mejor el historial que el plan de consulta intenta transmitir:
Sql.Database: este nodo representa el acceso al origen de datos. Se conecta a la base de datos y envía solicitudes de metadatos para comprender sus funcionalidades.Value.NativeQuery: representa la solicitud generada por Power Query para completar la consulta. Power Query envía las solicitudes de datos al origen de datos en una instrucción SQL nativa. En este caso, representa todos los registros y campos (columnas) de la tablafact_Sale. En este escenario, este caso no es lo que buscamos, ya que la tabla contiene millones de filas y solo nos interesan las 10 últimas.Table.LastN: una vez que Power Query recibe todos los registros de la tablafact_Sale, usa el motor de Power Query para filtrar la tabla y mantener solo las últimas 10 filas.Table.SelectColumns: Power Query usará el resultado del nodoTable.LastNy aplicará una nueva transformación denominadaTable.SelectColumns, que selecciona las columnas específicas que desea mantener de una tabla.
Para su evaluación, esta consulta tenía que descargar todas las filas y campos de la tabla fact_Sale. Esta consulta tardó un promedio de 6 minutos y 1 segundo en procesarse en una instancia estándar de flujos de datos de Power BI (que tiene en cuenta la evaluación y carga de datos en flujos de datos).
Ejemplo de plegado parcial de consultas
Después de conectarse a la base de datos y navegar a la tabla fact_Sale, empiece seleccionando las columnas que desea mantener de la tabla. Seleccione la transformación Elegir columnas que se encuentra dentro del grupo Administrar columnas de la pestaña Inicio. Esta transformación le ayuda a seleccionar de forma explícita las columnas que desea mantener de la tabla y quitar el resto.
Dentro del cuadro de diálogo Elegir columnas, seleccione las columnas Sale Key, Customer Key, Invoice Date Key, Description y Quantity, y a continuación, seleccione Aceptar.
Ahora creará la lógica que seguirá la tabla para ordenar las últimas ventas y colocarlas en la parte inferior de la tabla. Seleccione la columna Sale Key, que es la clave principal y la secuencia incremental o el índice de la tabla. Para ordenar la tabla, utilice solo este campo en orden ascendente desde el menú contextual de la columna.
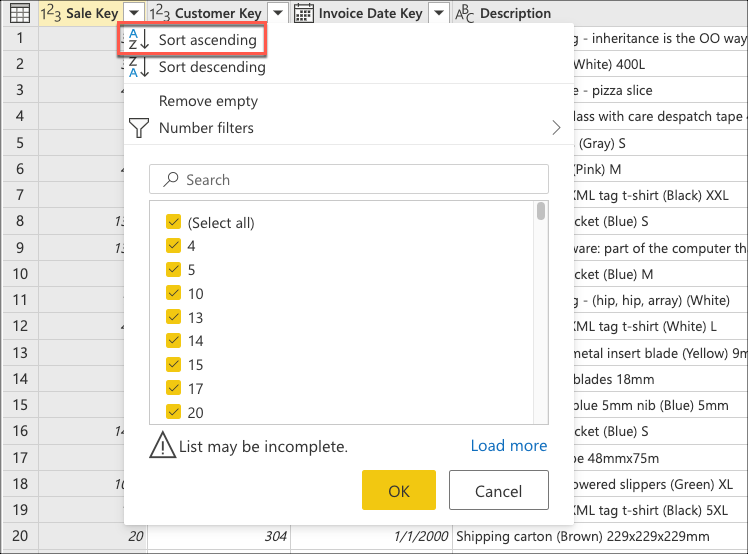
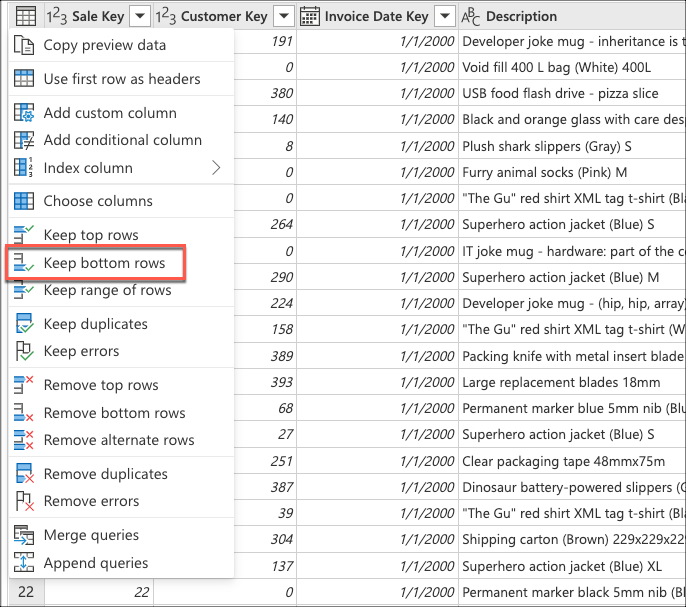
A continuación, seleccione el menú contextual de la tabla y elija la transformación Mantener filas inferiores.
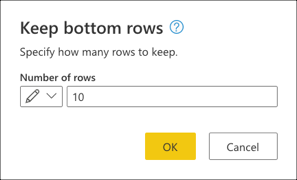
En Mantener filas inferiores, escriba el valor 10 y, a continuación, seleccione Aceptar.
El ejemplo de código siguiente es el script M completo para la consulta que creó:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
Ejemplo de plegado parcial de consultas: Descripción de la evaluación de consultas
Al comprobar el panel de pasos aplicados, verá que los indicadores de plegado de consultas muestran que la última transformación que usted agregó, Kept bottom rows, se marca como un paso que se evaluará fuera del origen de datos o, en otras palabras, mediante el motor de Power Query.
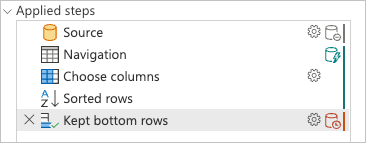
Puede hacer clic con el botón derecho en el último paso de la consulta, el denominado Kept bottom rows, y seleccionar la opción Plan de consulta para comprender mejor cómo se puede evaluar la consulta.
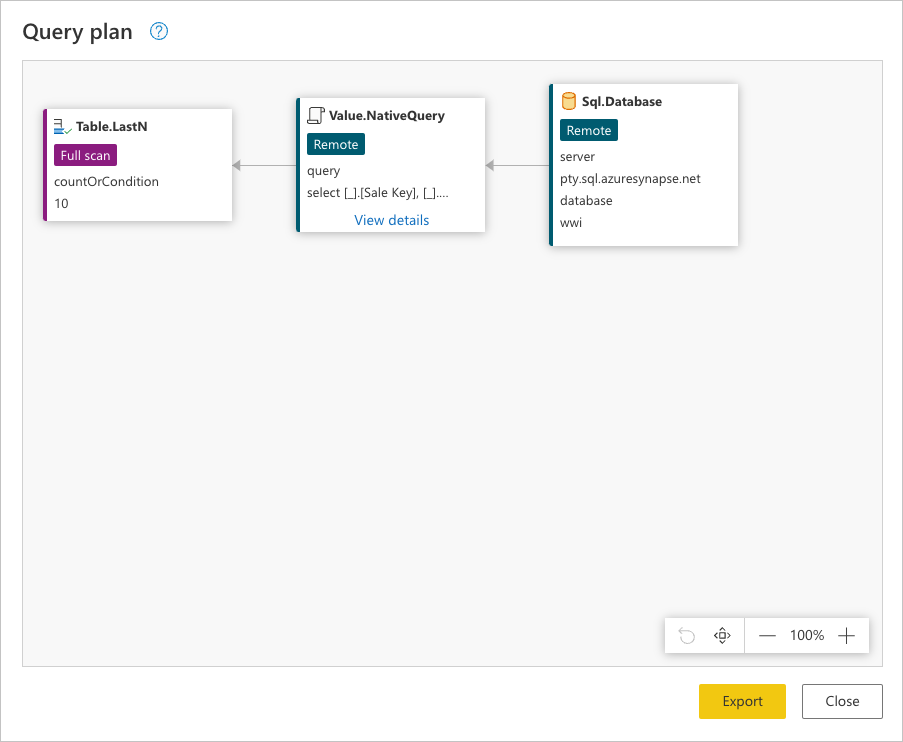
Cada cuadro de la imagen anterior se denomina nodo. Un nodo representa todos los procesos que deben producirse (de izquierda a derecha) para que se evalúe la consulta. Algunos de estos nodos se pueden evaluar en el origen de datos, mientras que otros, como el nodo de Table.LastN, representado por el paso Mantener filas inferiores, se evalúan mediante el motor de Power Query.
Para ver la solicitud exacta que se envía al origen de datos, seleccione Ver detalles en el nodo Value.NativeQuery.
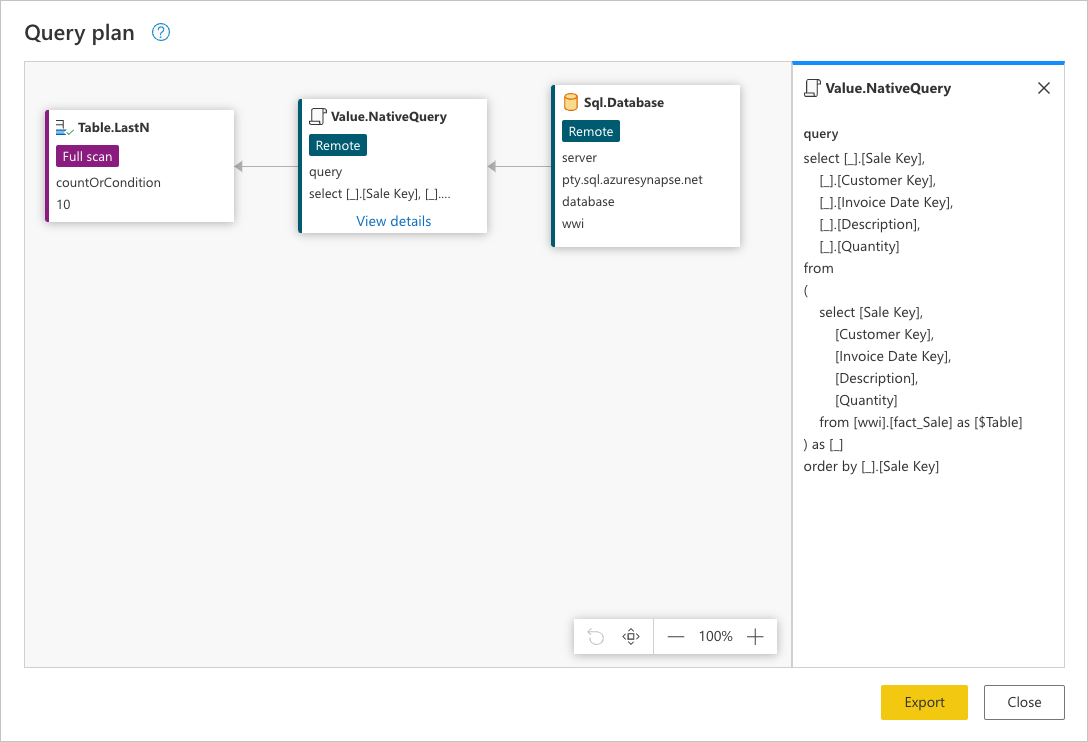
Esta solicitud está en el lenguaje nativo del origen de datos. En este caso, ese lenguaje es SQL y esta instrucción representa una solicitud para todas las filas, con solo los campos solicitados de la tabla fact_Sale ordenadas por el campo Sale Key.
Consultar esta solicitud de origen de datos puede ayudarle a comprender mejor el historial que el plan de consulta completo intenta transmitir. El orden de los nodos es un proceso secuencial que comienza con la solicitud de los datos del origen de datos:
Sql.Database: se conecta a la base de datos y envía solicitudes de metadatos para comprender sus funcionalidades.Value.NativeQuery: representa la solicitud generada por Power Query para completar la consulta. Power Query envía las solicitudes de datos al origen de datos en una instrucción SQL nativa. En este caso, representa todos los registros, con solo los campos solicitados de la tablafact_Salede la base de datos ordenadas en orden ascendente por el campoSales Key.Table.LastN: una vez que Power Query recibe todos los registros de la tablafact_Sale, usa el motor de Power Query para filtrar la tabla y mantener solo las últimas 10 filas.
Para su evaluación, esta consulta tenía que descargar todas las filas y solo los campos necesarios de la tabla fact_Sale. Tardó un promedio de 3 minutos y 4 segundos en procesarse en una instancia estándar de flujos de datos de Power BI (que tiene en cuenta la evaluación y carga de datos en flujos de datos).
Ejemplo de plegado completo de consultas
Después de conectarse a la base de datos y navegar a la tabla fact_Sale, usted debe empezar seleccionando las columnas que desea mantener de la tabla. Seleccione la transformación Elegir columnas que se encuentra dentro del grupo Administrar columnas de la pestaña Inicio. Esta transformación le ayuda a seleccionar de forma explícita las columnas que desea mantener de la tabla y quitar el resto.
En Elegir columnas, seleccione las columnas Sale Key, Customer Key, Invoice Date Key, Description y Quantity, y, a continuación, seleccione Aceptar.
Ahora creará la lógica que seguirá la tabla para ordenar las últimas ventas y colocarlas en la parte superior de la tabla. Seleccione la columna Sale Key, que es la clave principal y la secuencia incremental o el índice de la tabla. Para ordenar la tabla, utilice solo este campo en orden descendente desde el menú contextual de la columna.
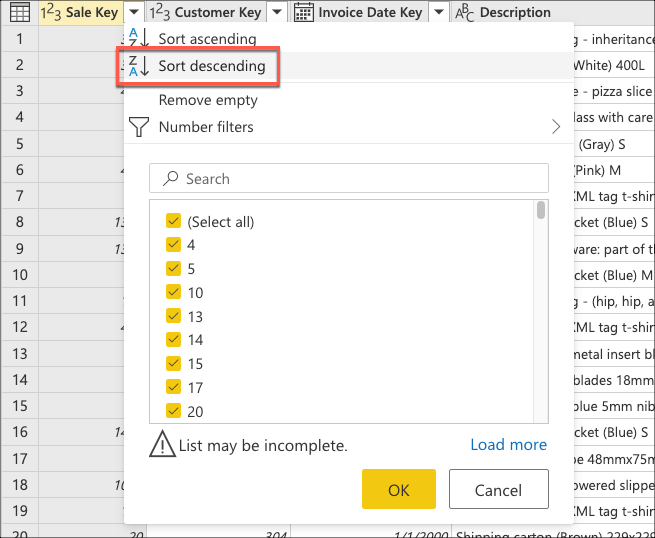
A continuación, seleccione el menú contextual de la tabla y elija la transformación Mantener filas superiores.
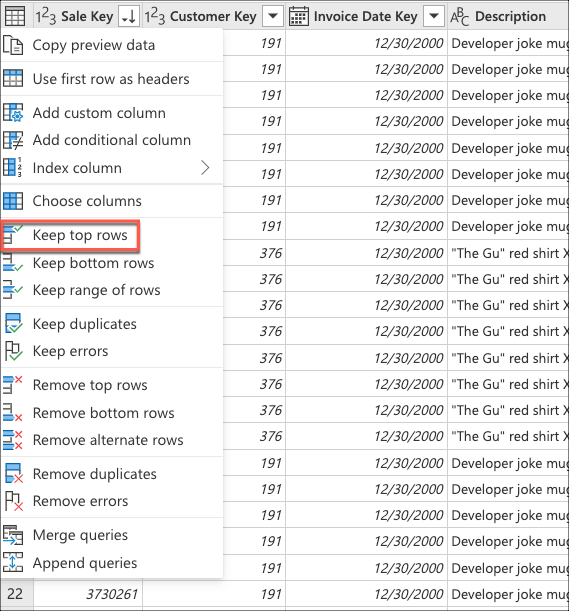
En Mantener filas superiores, escriba el valor 10 y, a continuación, seleccione Aceptar.
El ejemplo de código siguiente es el script M completo para la consulta que creó:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(Navigation, {"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
Ejemplo de plegado completo de consultas: Descripción de la evaluación de consultas
Al comprobar el panel de pasos aplicados, observará que los indicadores de plegado de consultas muestran que las transformaciones que usted agregó, Elegir columnas, Filas ordenadas y Mantener filas superiores se marcan como pasos que se evaluarán en el origen de datos.

Puede hacer clic con el botón derecho en el último paso de la consulta, el que se denomina Mantener filas superiores, y, a continuación, seleccionar la opción en la que se lee Plan de consulta.
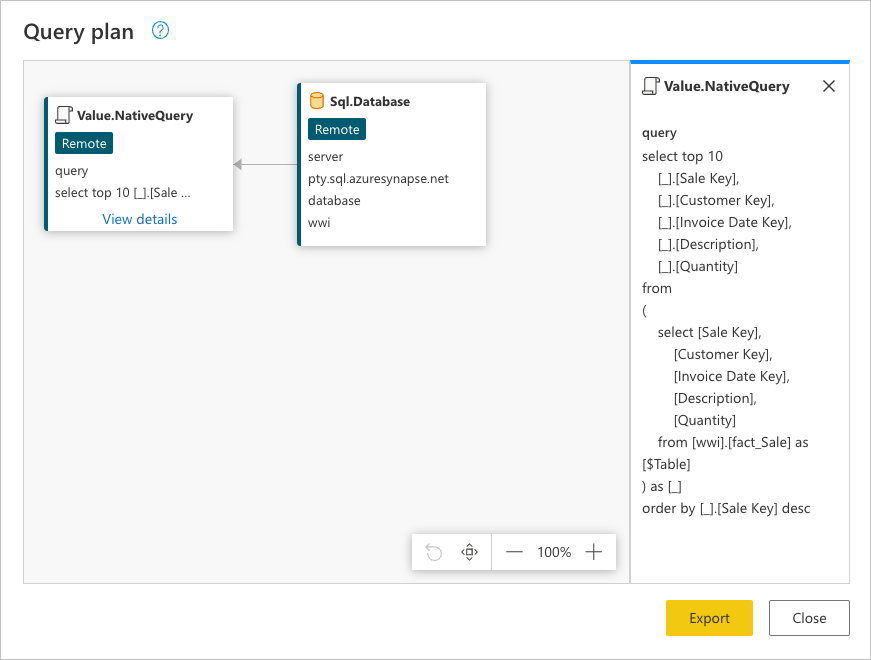
Esta solicitud está en el lenguaje nativo del origen de datos. En este caso, ese lenguaje es SQL y esta instrucción representa una solicitud para todas las filas y campos de la tabla fact_Sale.
Realizar esta consulta de origen de datos puede ayudarle a comprender mejor el historial que el plan de consulta completo intenta transmitir:
Sql.Database: se conecta a la base de datos y envía solicitudes de metadatos para comprender sus funcionalidades.Value.NativeQuery: representa la solicitud generada por Power Query para completar la consulta. Power Query envía las solicitudes de datos al origen de datos en una instrucción SQL nativa. En este caso, representa una solicitud únicamente para los 10 registros superiores de la tablafact_Sale, con solo los campos necesarios después de ordenarse en orden descendente mediante el campoSale Key.
Nota:
Aunque no hay ninguna cláusula que se pueda usar para SELECT (Seleccionar) las filas inferiores de una tabla en el lenguaje T-SQL, hay una cláusula TOP que recupera las filas superiores de una tabla.
Para su evaluación, esta consulta solo descarga 10 filas, con solo los campos que solicitó de la tabla fact_Sale. Esta consulta tardó un promedio de 31 segundos en procesarse en una instancia estándar de flujos de datos de Power BI (que tiene en cuenta la evaluación y carga de datos en flujos de datos).
Comparación del rendimiento
Para comprender mejor el efecto que tiene el plegado de consultas en estas consultas, puede actualizar las consultas, registrar el tiempo necesario para actualizar completamente cada consulta y compararlas. Para simplificar, en este artículo se proporcionan los tiempos de actualización promedio capturados mediante el mecanismo de actualización de flujos de datos de Power BI al conectarse a un entorno dedicado de Azure Synapse Analytics con DW2000c como nivel de servicio.
El tiempo de actualización de cada consulta fue el siguiente:
| Ejemplo | Etiqueta | Tiempo en segundos |
|---|---|---|
| Sin plegado de consultas | None | 361 |
| Plegado parcial de consultas | Parcial | 184 |
| Plegado completo de consultas | Completo | 31 |

A menudo, una consulta se vuelve a plegar completamente al origen de datos y supera a otras consultas similares que, por el contrario, no vuelven a plegarse completamente al origen de datos. Esto puede deberse a muchas razones. Estas razones van desde la complejidad de las transformaciones que realiza la consulta hasta las optimizaciones de consulta implementadas en el origen de datos, como índices y recursos informáticos o de red dedicados. Aun así, hay dos procesos clave específicos que el plegado de consultas intenta utilizar que minimiza el efecto que tienen ambos procesos en Power Query:
- Datos en tránsito
- Transformaciones que ejecuta el motor de Power Query
En las secciones siguientes se explica el efecto que tienen estos dos procesos en las consultas mencionadas anteriormente.
Datos en tránsito
Cuando se ejecuta una consulta, esta intenta capturar los datos del origen de datos como uno de sus primeros pasos. El mecanismo de plegado de consultas define los datos que se capturan del origen de datos. Este mecanismo identifica los pasos de la consulta que se pueden descargar en el origen de datos.
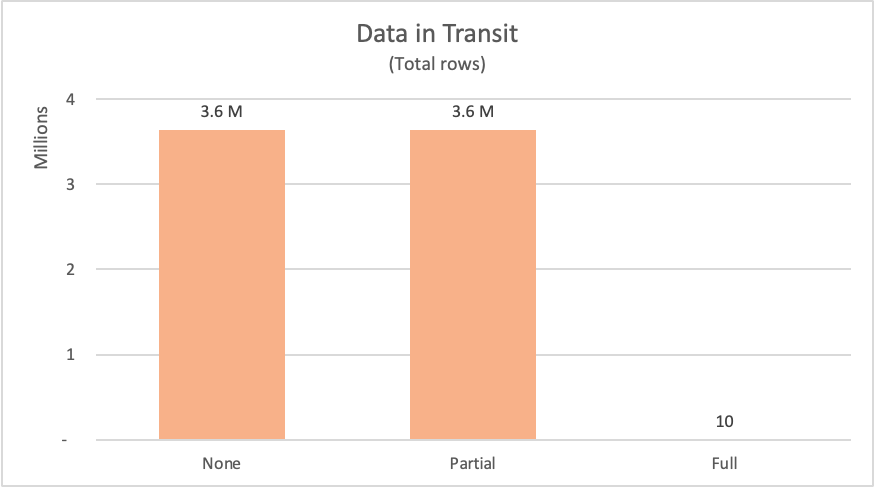
En la siguiente tabla se muestra el número de filas solicitadas desde la tabla fact_Sale de la base de datos. La tabla también incluye una breve descripción de la instrucción SQL enviada para solicitar dichos datos desde el origen de datos.
| Ejemplo | Etiqueta | Filas solicitadas | Descripción |
|---|---|---|---|
| Sin plegado de consultas | None | 3644356 | Solicitud de todos los campos y todos los registros de la tabla fact_Sale. |
| Plegado parcial de consultas | Parcial | 3644356 | Solicitud de todos los registros, pero solo los campos obligatorios de la tabla fact_Sale después de ordenarla por el campo Sale Key. |
| Plegado completo de consultas | Completo | 10 | Solicitud de solo los campos necesarios y los 10 registros TOP (superiores) de la tabla fact_Sale después de ordenarse en orden descendente por el campo Sale Key. |
Al solicitar datos desde un origen de datos, el origen de datos debe procesar los resultados de la solicitud y, a continuación, enviar los datos al solicitante. Aunque ya se han mencionado los recursos informáticos, los recursos de red para mover los datos del origen de datos a Power Query y, a continuación, hacer que Power Query pueda recibir eficazmente los datos y prepararlos para las transformaciones que se producirán de forma local, pueden tardar algún tiempo en función del tamaño de los datos.
Para los ejemplos que se han mostrado en este artículos, Power Query tenía que solicitar más de 3,6 millones de filas del origen de datos para los ejemplos de plegado parcial de consultas y sin plegado de consultas. En el ejemplo de plegado completo de consultas, solo solicitó 10 filas. Para los campos solicitados, el ejemplo sin plegado de consultas solicitó todos los campos disponibles de la tabla. En los ejemplos, tanto el plegado parcial de consultas como el plegado completo de consultas solo enviaron una solicitud para exactamente los campos que necesitaban.
Precaución
Se recomienda implementar soluciones de actualización incremental que saquen partido del plegado de consultas para tablas o consultas con grandes cantidades de datos. Diferentes integraciones de productos de Power Query implementan tiempos de expiración para finalizar consultas de larga duración. Algunos orígenes de datos también implementan tiempos de expiración en sesiones de larga duración al intentar ejecutar consultas costosas en sus servidores. Más información: Uso de la actualización incremental con flujos de datos y Actualización incremental para modelos semánticos
Transformaciones que ejecuta el motor de Power Query
En este artículo se muestra cómo puede usar el Plan de consulta para comprender mejor cómo se puede evaluar la consulta. Dentro del plan de consulta, puede ver los nodos exactos de las operaciones de transformación que realizará el motor de Power Query.
En la siguiente tabla se muestran los nodos de los planes de consulta de las consultas anteriores que el motor de Power Query habría evaluado.
| Ejemplo | Etiqueta | Nodos de transformación del motor de Power Query |
|---|---|---|
| Sin plegado de consultas | None | Table.LastN, Table.SelectColumns |
| Plegado parcial de consultas | Parcial | Table.LastN |
| Plegado completo de consultas | Completo | — |
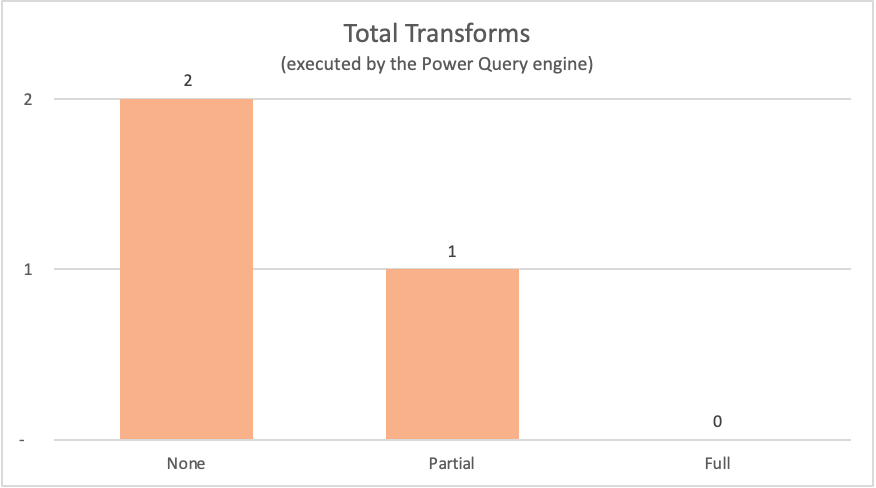
Para los ejemplos que se mostraron anteriormente en este artículo, el ejemplo de plegado completo de consultas no requiere que se produzcan transformaciones dentro del motor de Power Query, ya que la tabla de salida necesaria procede directamente del origen de datos. Por el contrario, las otras dos consultas requerían que se realizara algún cálculo en el motor de Power Query. Debido a la gran cantidad de datos que deben procesar estas dos consultas, el proceso de estos ejemplos tarda más tiempo que el ejemplo de plegado completo de consultas.
Las transformaciones se pueden agrupar en las siguientes categorías:
| Tipo de operador | Descripción |
|---|---|
| Remoto | Operadores que son nodos del origen de datos. La evaluación de estos operadores se produce fuera de Power Query. |
| Streaming | Los operadores son operadores de tránsito. Por ejemplo, Table.SelectRows con un filtro simple puede, por lo general, filtrar los resultados a medida que pasan a través del operador y no es necesario recopilar todas las filas antes de mover los datos. Table.SelectColumns y Table.ReorderColumns son otros ejemplos de este tipo de operadores. |
| Recorrido completo | Operadores que necesitan recopilar todas las filas antes de que los datos puedan pasar al siguiente operador de la cadena. Por ejemplo, para ordenar los datos, Power Query debe recopilar todos los datos. Otros ejemplos de operadores de examen completo son Table.Group, Table.NestedJoin y Table.Pivot. |
Sugerencia
Aunque no todas las transformaciones son las mismas desde el punto de vista del rendimiento, en la mayoría de los casos, tener menos transformaciones suele ser mejor.
Consideraciones y sugerencias
- Siga los procedimientos recomendados al crear una nueva consulta, como se indica en Procedimientos recomendados en Power Query.
- Use los indicadores de plegado de consultas para comprobar qué pasos impiden el plegado de la consulta. Reordénelos si es necesario para aumentar el plegado.
- Utilice el plan de consulta para determinar qué transformaciones se producen en el motor de Power Query para un paso determinado. Considere la posibilidad de modificar la consulta existente mediante la reorganización de los pasos. A continuación, vuelva a comprobar el plan de consulta del último paso de la consulta y compruebe si el plan de consulta parece mejor que el anterior. Por ejemplo, el nuevo plan de consulta tiene menos nodos que el anterior, y la mayoría de los nodos son del tipo "Streaming" y no "Examen completo". En el caso de los orígenes de datos que admiten el plegado, los nodos del plan de consulta que no sean
Value.NativeQueryy los nodos de acceso al origen de datos representan transformaciones que no se plegaron. - Cuando esté disponible, puede usar la opción Ver consulta nativa (o Ver consulta de origen de datos) para asegurarse de que la consulta se puede volver a plegar al origen de datos. Si esta opción está deshabilitada para el paso y usted utiliza un origen que normalmente lo habilita, es posible que haya creado un paso que impida el plegado de consultas. Si utiliza un origen que no admite esta opción, puede confiar en los indicadores de plegado de consultas y el plan de consulta.
- Utilice las herramientas de diagnóstico de consultas para comprender mejor las solicitudes que se envían al origen de datos cuando las funcionalidades de plegado de consultas están disponibles para el conector.
- Al combinar datos procedentes del uso de varios conectores, Power Query intentará insertar tanto trabajo como sea posible a ambos orígenes de datos y, al mismo tiempo, intentará cumplir con los niveles de privacidad definidos para cada origen de datos.
- Lea el artículo sobre los niveles de privacidad para proteger las consultas frente a un error de Firewall de privacidad de datos.
- Use otras herramientas para comprobar el plegado de consultas desde la perspectiva de la solicitud que recibe el origen de datos. En función de los ejemplos de este artículo, puede utilizar Microsoft SQL Server Profiler para comprobar las solicitudes que envía Power Query y que recibe Microsoft SQL Server.
- Si agrega un nuevo paso a una consulta totalmente plegada y el nuevo paso también se pliega, Power Query podría enviar una nueva solicitud al origen de datos en lugar de usar una versión almacenada en caché del resultado anterior. En la práctica, este proceso puede dar lugar a operaciones aparentemente sencillas en una pequeña cantidad de datos que tardan más tiempo de lo esperado en actualizarse en la vista previa. Esta actualización más larga se debe a que Power Query vuelve a consultar el origen de datos en lugar de trabajar con una copia local de los datos.