Consideraciones de asignación de campos para flujos de datos estándar
Al cargar datos en tablas de Dataverse, asigna las columnas de la consulta de origen de la experiencia de edición del flujo de datos a las columnas de tabla de Dataverse de destino. Además de la asignación de datos, hay otras consideraciones y procedimientos recomendados que se deben tener en cuenta. En este artículo se tratan las distintas configuraciones de flujo de datos que controlan el comportamiento de la actualización del flujo de datos y, como resultado, los datos de la tabla de destino.
Control de si los flujos de datos crean o actualizan/insertan registros cada vez que se actualizan
Cada vez que actualice un flujo de datos, recupera los registros del origen y los carga en Dataverse. Si ejecuta el flujo de datos más de una vez (en función de cómo configure el flujo de datos), puede:
- Crear registros nuevos para cada actualización del flujo de datos, incluso si estos registros ya existen en la tabla de destino.
- Crear nuevos registros si aún no existen en la tabla o actualizar los registros existentes si ya existen en la tabla. Este comportamiento se denomina actualizar/insertar.
El uso de una columna clave indica al flujo de datos que actualice/inserte registros en la tabla de destino, mientras que la no selección de una clave indica el flujo de datos para crear nuevos registros en la tabla de destino.
Una columna de clave es una columna que es única y determinista de una fila de datos en la tabla. Por ejemplo, en una tabla de Pedidos, si Id. de pedido es una columna de clave, no debe tener dos filas con el mismo identificador de pedido. Además, un identificador de pedido (supongamos que un pedido con el identificador 345) solo debe representar una fila de la tabla. Para elegir la columna de clave de la tabla de Dataverse del flujo de datos debe establecer el campo de clave en la experiencia de asignación de tablas.
Elección de un nombre principal y un campo de clave al crear una nueva tabla
En la imagen siguiente se muestra cómo puede elegir la columna de clave que se va a rellenar desde el origen al crear una nueva tabla en el flujo de datos.
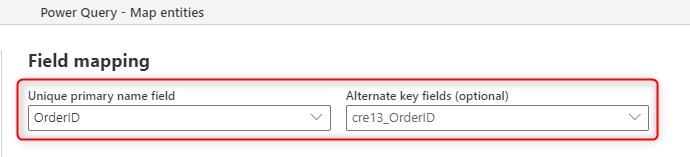
El campo de nombre principal que ve en la asignación de campos es para un campo de etiqueta; este campo no necesita ser único. El campo que se usa en la tabla para comprobar la duplicación es el campo que establezca en el campo Clave alternativa.
Tener una clave principal en la tabla garantiza que, incluso si tiene datos duplicadas en el campo asignado a la clave principal, las entradas duplicadas no se cargarán en la tabla. Este comportamiento mantiene una alta calidad de los datos de la tabla. Una alta calidad de datos es esencial para crear soluciones de informes basadas en la tabla.
El campo de nombre principal
El campo de nombre principal es un campo de visualización que se usa en Dataverse. Este campo se usa en vistas predeterminadas para mostrar el contenido de la tabla en otras aplicaciones. Este campo no es el campo de clave principal y no debe considerarse así. Este campo tiene valores duplicados, ya que es un campo de visualización. Sin embargo, el procedimiento recomendado es usar un campo concatenado para asignarlo al campo de nombre principal, por lo que el nombre es totalmente explicativo.
El campo de clave alternativa es lo que se usa como clave principal.
Elección de un campo de clave al cargar en una tabla existente
Al asignar una consulta de flujo de datos a una tabla de Dataverse existente, puede elegir si se debe utilizar una clave y cuál al cargar los datos en la tabla de destino.
En la imagen siguiente se muestra cómo puede elegir la columna de clave que se va a usar al actualizar/insertar los registros en una tabla de Dataverse existente:

Establecimiento de la columna Id. único de una tabla y su uso como campo clave para la actualizar/insertar registros en tablas existentes de Dataverse
Todas las filas de tablas Microsoft Dataverse tienen identificadores únicos definidos como GUID. Estos GUID son la clave principal de cada tabla. De forma predeterminada, los flujos de datos no pueden establecer una clave principal de tablas y Dataverse la genera automáticamente cuando se crea un registro. Hay casos de uso avanzados en los que es conveniente aprovechar la clave principal de una tabla, por ejemplo, integrar datos con orígenes externos y mantener los mismos valores de clave principal en la tabla externa y en la tabla de Dataverse.
Nota:
- Esta funcionalidad solo está disponible al cargar datos en tablas existentes.
- El campo de identificador único solo acepta una cadena que contenga valores GUID, cualquier otro tipo de datos o valor hace que se produzca un error en la creación de registros.
Para aprovechar el campo identificador único de una tabla, seleccione Cargar en tabla existente en la página Asignar tablas al crear un flujo de datos. En el ejemplo que se muestra en la imagen siguiente, carga datos en la tabla CustomerTransactions y usa la columna TransactionID del origen de datos como identificador único de la tabla.
Observe que, en la lista desplegable Seleccionar clave, se puede seleccionar el identificador único (que siempre se denomina "nombre de tabla + Id.") de la tabla. Dado que el nombre de la tabla es "CustomerTransactions", el campo de identificador único se denomina "CustomerTransactionId".

Una vez seleccionado, la sección de asignación de columnas se actualiza para incluir el identificador único como una columna de destino. A continuación, puede asignar la columna de origen que representa el identificador único de cada registro.

Candidatos óptimos para el campo de clave
El campo de clave es un valor único que representa una fila única en la tabla. Es importante tener este campo, ya que ayuda a evitar tener registros duplicados en la tabla. Este campo puede provenir de tres orígenes:
Clave principal del sistema de origen (por ejemplo, OrderID en el ejemplo anterior). Un campo concatenado creado mediante transformaciones de Power Query en el flujo de datos.
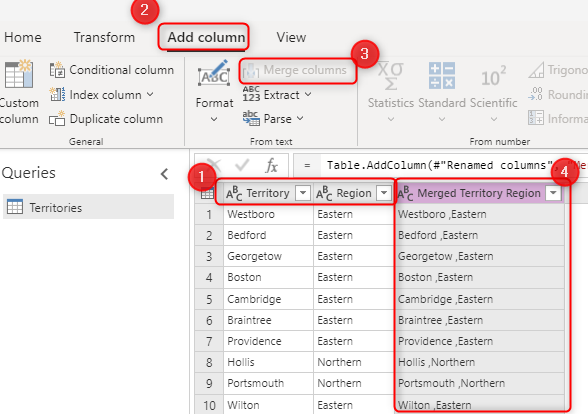
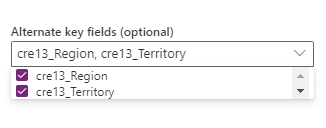
Combinación de campos que se van a seleccionar en la opción Clave alternativa. Una combinación de campos usados como campo de clave también se denomina clave compuesta.
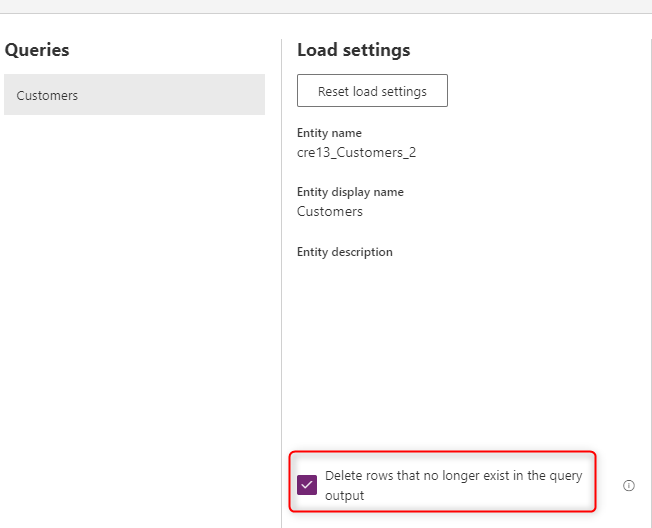
Eliminación de filas que ya no existen
Si desea tener los datos de la tabla siempre sincronizados con los datos del sistema de origen, elija la opción Eliminar las filas que ya no existen en la salida de la consulta. Sin embargo, esta opción ralentiza el flujo de datos porque es necesario realizar una comparación de filas basada en la clave principal (clave alternativa en la asignación de campos del flujo de datos) para que se produzca esta acción.
Esta opción significa que si hay una fila de datos en la tabla que no existe en la siguiente salida de consulta de la actualización del flujo de datos, esa fila se quitará de la tabla.
Nota:
Los flujos de datos V2 estándar se basan en los campos createdon y modifiedon para quitar de la tabla de destino las filas que no existen en la salida de los flujos de datos. Si esas columnas no existen en la tabla de destino, no se eliminarán los registros.
Restricciones conocidas
- Actualmente no se admite la asignación a campos de búsqueda polimórfica.
- Actualmente no se admite la asignación a un campo de búsqueda de varios niveles, una búsqueda que apunta al campo de búsqueda de otra tabla.
- Actualmente no se admite la asignación a los campos Estado y Razón para el estado.
- No se admite la asignación de datos en texto de varias líneas que incluya caracteres de salto de línea y se quitan los saltos de línea. En su lugar, puede usar la etiqueta de salto de línea
<br>para cargar y conservar el texto de varias líneas. - La asignación a campos de Opción configurados con la opción de selección múltiple habilitada solo se admite en determinadas condiciones. El flujo de datos solo carga datos en campos de Opción con la opción de selección múltiple habilitada y se usa una lista separada por comas de valores (enteros) de las etiquetas. Por ejemplo, si las etiquetas son "Choice1, Choice2, Choice3" con los valores de enteros correspondientes de "1, 2, 3", los valores de columna deben ser "1,3" para seleccionar la primera y última opción.
- Los flujos de datos V2 estándar se basan en los campos
createdonymodifiedonpara quitar de la tabla de destino las filas que no existen en la salida de los flujos de datos. Si esas columnas no existen en la tabla de destino, no se eliminarán los registros. - La asignación a campos cuya propiedad IsValidForCreate está establecida en
falseno se admite (por ejemplo, el campo Cuenta de la entidad Contacto).