Referencia de las consultas de Power Query
Este artículo está dirigido a modeladores de datos como usted que trabajan con Power BI Desktop. Proporciona instrucciones al definir las consultas de Power Query que hacen referencia a otras consultas.
Aclaremos lo que esto significa: Cuando una consulta hace referencia a una segunda consulta, es como si los pasos de la segunda consulte se combinaran con los pasos de la primera consulta y se ejecutaran antes de estos.
Considere varias consultas: Query1 obtiene los datos de un servicio web y su carga está deshabilitada. Las consultas Query2, Query3 y Query4 hacen referencia a Query1 y sus salidas se cargan en el modelo de datos.
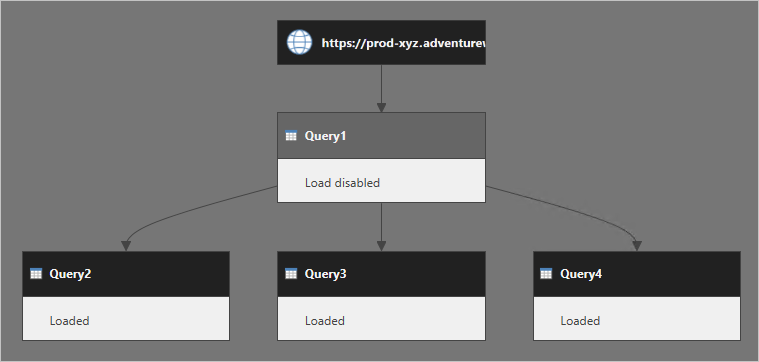
Cuando se actualiza el modelo de datos, a menudo se presupone que Power Query recupera el resultado de Query1 y que lo reutilizan las consultas a las que se hace referencia. Esto no es correcto. De hecho, Power Query ejecuta las consultas Query2, Query3 y Query4 por separado.
Puede pensar que la consulta Query2 tiene insertados los pasos de la consulta Query1. Esto también pasa con las consultas Query3 y Query4. En el diagrama siguiente se muestra una imagen más clara de cómo se ejecutan las consultas.
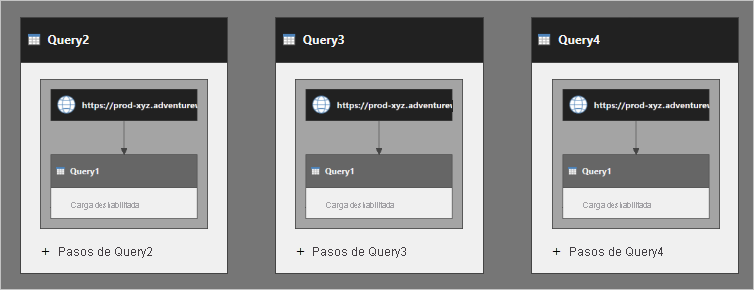
La consulta Query1 se ejecuta tres veces. Las diversas ejecuciones pueden dar lugar a una actualización de datos lenta y afectar negativamente al origen de datos.
El uso de la función Table.Buffer en la consulta Query1 no eliminará la recuperación de datos adicionales. Esta función almacena en búfer una tabla en memoria y la tabla almacenada en búfer solo se puede usar dentro de la misma ejecución de consulta. Por lo tanto, en el ejemplo, si la consulta Query1 se almacena en búfer cuando se ejecuta la consulta Query2, los datos almacenados en búfer no se pueden usar cuando se ejecutan las consultas Query3 y Query4. Ellos mismos almacenan en búfer los datos otras dos veces. (De hecho, este resultado podría componer el rendimiento negativo, porque la tabla la almacenará en búfer cada consulta a la que se hace referencia).
Nota
La arquitectura de almacenamiento en caché de Power Query es compleja y no es el objetivo de este artículo. Power Query puede almacenar en caché los datos recuperados de un origen de datos. Sin embargo, cuando ejecuta una consulta, puede recuperar los datos del origen de datos más de una vez.
Recomendaciones
Por lo general, se recomienda hacer referencia a las consultas para evitar la duplicación de lógica en las consultas. Sin embargo, tal como se describe en este artículo, este enfoque de diseño puede contribuir a las actualizaciones de datos lentas y a los orígenes de datos sobrecargados.
En su lugar, se recomienda crear un flujo de datos. Usar un flujo de datos puede mejorar el tiempo de actualización de los datos y disminuir el impacto en los orígenes de datos.
Puede diseñar el flujo de datos para que encapsule los datos de origen y las transformaciones. Como el flujo de datos es un almacén de datos persistente del servicio Power BI, su recuperación de datos es rápida. Por lo tanto, incluso cuando las consultas a las que se hace referencia generan varias solicitudes para el flujo de datos, es posible mejorar los tiempos de actualización de los datos.
En el ejemplo, si la consulta Query1 se rediseña como una entidad de flujo de datos, las consultas Query2, Query3 y Query4 pueden usarla como un origen de datos. Con este diseño, la entidad que obtiene la consulta Query1 solo se evaluará una vez.
Contenido relacionado
Para obtener más información sobre este artículo, consulte los recursos siguientes: