Conexión a orígenes de datos de SAP HANA mediante DirectQuery en Power BI
Puede conectarse a orígenes de datos de SAP HANA directamente mediante DirectQuery, que a menudo es necesario para grandes conjuntos de datos que superan los recursos disponibles para admitir modelos de importación. Hay dos enfoques para conectarse a SAP HANA en modo DirectQuery, cada uno con funcionalidades diferentes:
Tratar SAP HANA como origen multidimensional (valor predeterminado): En este caso, el comportamiento es similar a cuando Power BI se conecta a otros orígenes multidimensionales como SAP Business Warehouse o Analysis Services. Cuando se conecta a SAP HANA como origen multidimensional, se selecciona una sola vista analítica o de cálculo y todas las medidas, jerarquías y atributos de esa vista están disponibles en la lista de campos. No se pueden agregar columnas calculadas ni otras personalizaciones de datos en el modelo semántico. A medida que se crean objetos visuales, los datos agregados se recuperan directamente de SAP HANA. Tratar SAP HANA como origen multidimensional es el valor predeterminado para los nuevos informes de DirectQuery sobre SAP HANA.
Tratar SAP HANA como origen relacional: En este caso, Power BI trata SAP HANA como origen de datos relacional. Este enfoque ofrece una mayor flexibilidad. Entre otras cosas, puede agregar columnas calculadas e incluir datos de otros orígenes, pero se debe tener cuidado para asegurarse de que las medidas se agregan según lo previsto. Evite medidas no aditivas. Además, asegúrese de usar vistas sencillas con pocas columnas y combinaciones para evitar problemas de rendimiento. Considere la posibilidad de volver a crear medidas en el modelo semántico, pero tenga en cuenta que las medidas complejas podrían no plegarse. Las jerarquías de SAP HANA no están disponibles cuando se usa SAP HANA como origen relacional.
El método de conexión viene determinado por una opción de herramienta global, que se establece seleccionando Archivo>Opciones y configuraciones y, a continuación, Opciones>DirectQueryy seleccionando la opción Tratar SAP HANA como origen relacional, como se muestra en la imagen siguiente.
La opción de tratar SAP HANA como origen relacional controla el método de conexión para cualquier informe de nuevo mediante DirectQuery a través de SAP HANA. No tiene ningún efecto en las conexiones de SAP HANA existentes en el informe actual, ni en las conexiones de ningún otro informe que se abra. Por lo tanto, si la opción está desactivada actualmente, al agregar una nueva conexión a SAP HANA mediante Obtener datos, esa conexión trata SAP HANA como origen multidimensional. Sin embargo, si se abre un informe diferente que también se conecta a SAP HANA, ese informe continúa comportándose según la opción que se estableció en el momento en que se creó. Este hecho significa que los informes que se conectan a SAP HANA como origen relacional continúan tratando SAP HANA como origen relacional incluso si la opción está desactivada.
Los dos métodos de conexión de SAP HANA constituyen un comportamiento diferente y no es posible cambiar un informe existente de un método de conexión al otro.
Tratar SAP HANA como origen multidimensional (valor predeterminado)
Todas las nuevas conexiones a SAP HANA usan este método de conexión de forma predeterminada, tratando SAP HANA como origen multidimensional. Al conectarse a SAP HANA como origen multidimensional, se aplican las siguientes consideraciones:
En Get Data Navigator (Obtener navegador de datos), se puede seleccionar una sola vista de SAP HANA. No es posible seleccionar medidas o atributos individuales. No hay ninguna consulta definida en el momento de la conexión, que es diferente de importar datos o al usar DirectQuery al tratar SAP HANA como origen relacional. Esta consideración también significa que no es posible usar directamente una consulta SQL de SAP HANA al seleccionar este método de conexión.
Todas las medidas, jerarquías y atributos de la vista seleccionada se muestran en la lista de campos.
Cuando se utiliza una medida en un objeto visual, se realiza una consulta a SAP HANA para recuperar el valor de la medida en el nivel de agregación necesario para el objeto visual. Cuando se trabaja con medidas no aditivas, como contadores y relaciones, sap HANA realiza todas las agregaciones y Power BI no realiza ninguna agregación adicional.
Para asegurarse de que siempre se pueden obtener los valores agregados correctos de SAP HANA, se deben imponer ciertas restricciones. Por ejemplo, no es posible agregar columnas calculadas ni combinar datos de varias vistas de SAP HANA en el mismo informe. Tampoco es posible eliminar columnas ni cambiar sus tipos de datos.
Tratar a SAP HANA como una fuente multidimensional ofrece menos flexibilidad que la alternativa enfoque relacional, pero es más sencillo. Este método de conexión garantiza valores agregados correctos al tratar con medidas de SAP HANA más complejas y, por lo general, da lugar a un mayor rendimiento.
La lista Field incluye todas las medidas, atributos y jerarquías de la vista de SAP HANA. Tenga en cuenta los comportamientos siguientes que se aplican al usar este método de conexión:
Cualquier atributo que se incluya en al menos una jerarquía está oculta de forma predeterminada. Sin embargo, se pueden ver si fuera necesario seleccionando Ver ocultos en el menú contextual de la lista de campos. En el mismo menú contextual se pueden hacer visibles, si es necesario.
En SAP HANA, se puede definir un atributo para usar otro atributo como etiqueta. Por ejemplo, Product, con valores
1,2,3, etc., podría usar ProductName, con valoresBike,Shirt,Gloves, etc., como su etiqueta. En este caso, se muestra un campo único Product en la lista de campos, cuyos valores son las etiquetasBike,Shirt,Gloves, etc., pero ordenados por y cuya unicidad está determinada por los valores de clave1,2,3. También se crea una columna oculta Product.Key, lo que permite el acceso a los valores de clave subyacentes si es necesario.
Las variables definidas en la vista de SAP HANA subyacente se muestran en el momento de la conexión y se pueden especificar los valores necesarios. Dichos valores se pueden cambiar posteriormente seleccionando Transformar datos en la cinta de opciones y, luego, Editar parámetros en el menú desplegable que aparece.
Las operaciones de modelado permitidas son más restrictivas que en el caso general al usar DirectQuery, dada la necesidad de asegurarse de que los datos agregados correctos siempre se pueden obtener de SAP HANA. Sin embargo, todavía es posible realizar algunas adiciones y cambios, como definir medidas, cambiar el nombre y ocultar campos, y definir formatos de presentación. Todos estos cambios se conservan en la actualización y se aplican los cambios no conflictivos realizados en la vista de SAP HANA.
Restricciones de modelado adicionales
Además de las limitaciones mencionadas anteriormente, tenga en cuenta las siguientes restricciones de modelado al conectarse a SAP HANA como origen multidimensional:
- No se admiten columnas calculadas: La capacidad de crear columnas calculadas está deshabilitada. Este hecho también significa que la agrupación y la agrupación en clústeres, que se basan en columnas calculadas, no están disponibles.
- Limitaciones adicionales para las medidas: Existen otras limitaciones impuestas en las expresiones DAX que se pueden usar en medidas, para reflejar el nivel de soporte ofrecido por SAP HANA. Por ejemplo, no es posible usar una función de agregado en una tabla.
- No se admite la definición de relaciones: Solo se puede consultar una sola vista dentro de un informe y, como tal, no se admite la definición de relaciones.
- Vista sin datos: La vista de datos de normalmente muestra los datos de nivel de detalle en las tablas. Dada la naturaleza de los orígenes multidimensionales, esta vista no está disponible cuando se usa SAP HANA como origen multidimensional.
- Detalles de columna y medida son fijos: Las columnas y medidas de la lista de campos están determinadas por el origen subyacente y no se pueden modificar. Por ejemplo, no es posible eliminar una columna ni cambiar su tipo de datos. Sin embargo, se puede cambiar el nombre.
Restricciones de visualización adicionales
Hay restricciones en las visualizaciones al conectarse con SAP HANA como fuente multidimensional.
- No se permite la agregación de columnas: no es posible cambiar la agregación de una columna en un objeto visual; es siempre No resumir.
Tratar SAP HANA como origen relacional
Para conectarse a SAP HANA como origen relacional, debe seleccionar Archivo>Opciones y configuración y, a continuación, Opciones>DirectQuery, y luego seleccionar la opción Tratar SAP HANA como origen relacional.
Al usar SAP HANA como origen relacional, hay cierta flexibilidad adicional disponible. Por ejemplo, puede crear columnas calculadas, incluir datos de varias vistas de SAP HANA y crear relaciones entre las tablas resultantes. Sin embargo, hay diferencias en el comportamiento al conectarse a SAP HANA como origen multidimensional, especialmente cuando la vista de SAP HANA contiene medidas no aditivas, por ejemplo, recuentos distintos o promedios, en lugar de sumas simples. Las medidas no aditivas pueden producir resultados incorrectos. Las medidas también pueden reducir la eficacia de la optimización del plan de consulta en SAP HANA y dar lugar a tiempos de espera y rendimiento deficientes de las consultas.
Descripción de SAP HANA como origen relacional
Resulta útil empezar aclarando el comportamiento de un origen relacional, como SQL Server, cuando la consulta definida en Obtener datos o el Editor de Power Query realiza una agregación. En el ejemplo siguiente, una consulta definida en el Editor de Power Query devuelve el precio medio ProductID.
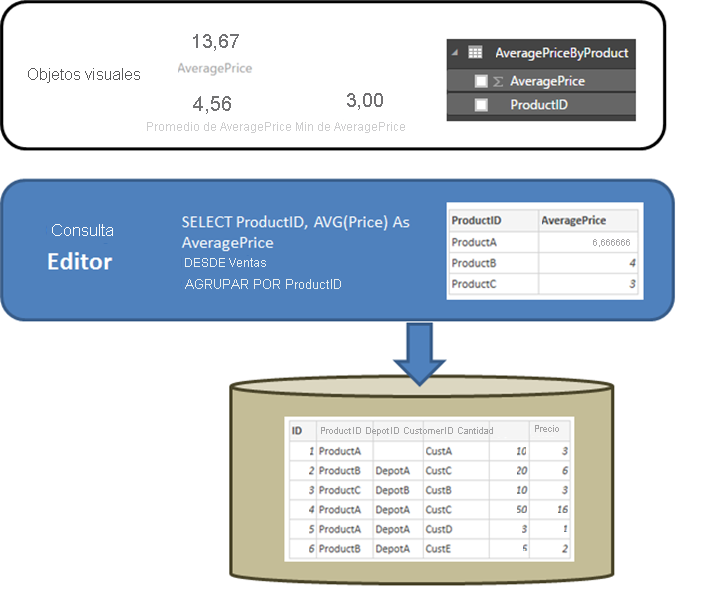
Si los datos se importaron en Power BI en lugar de usar DirectQuery, se produciría la siguiente situación:
- Los datos se importan en el nivel de agregación definido por la consulta creada en el Editor de Power Query. Por ejemplo, precio medio por producto. Este hecho da como resultado una tabla con las dos columnas ProductID y AveragePrice que se pueden usar en las visualizaciones.
- En un objeto visual, cualquier agregación subsiguiente (como Suma, Promedio, Mínimo, etc.) se realiza con los datos importados. Por ejemplo, al incluir AveragePrice en un objeto visual, se usa el agregado Suma de forma predeterminada, cuyo resultado sería la suma de AveragePrice de cada ProductID, que en este caso sería 13,67. Lo mismo se aplica a cualquier función de agregado alternativa (como Mínimo, Promedio, etc.) usada en el objeto visual. Por ejemplo, el promedio de AveragePrice devuelve la media de 6,66, 4 y 3, que equivale a 4,56, y no la media del precio de los seis registros de la tabla subyacente, que es 5,17.
Si Se usa DirectQuery sobre ese mismo origen relacional en lugar de Importar, se aplica la misma semántica y los resultados serían exactamente los mismos:
Dada la misma consulta, lógicamente se presentan exactamente los mismos datos a la capa de informes, aunque los datos no se importen realmente.
En un objeto visual, cualquier agregación subsiguiente (Suma, Promedio y Mínimo, etc.) vuelve a realizarse según la tabla lógica de la consulta. Y, una vez más, un objeto visual que contiene el promedio de AveragePrice devuelve el mismo resultado de 4,56.
Tenga en cuenta SAP HANA cuando la conexión se trate como un origen relacional. Power BI puede trabajar con vistas analíticas de y vistas de cálculo en SAP HANA, que pueden contener medidas. Sin embargo, en la actualidad el enfoque de SAP HANA sigue los mismos principios descritos anteriormente en esta sección: la consulta definida en Obtener datos o el Editor de Power Query determina los datos disponibles y, a continuación, cualquier agregación posterior en un objeto visual supera esos datos y lo mismo se aplica tanto a Import como DirectQuery. Sin embargo, dada la naturaleza de SAP HANA, la consulta definida en el cuadro de diálogo inicial Obtener datos o Editor de Power Query siempre es una consulta de agregado y, por lo general, incluye medidas en las que las agregaciones reales que se usan se definen mediante la vista de SAP HANA.
El equivalente del ejemplo anterior de SQL Server es que hay una vista de SAP HANA que contiene ID, ProductID, DepotID, y medidas que incluyen AveragePrice, definido en la vista como Promedio de precio.
Si en la experiencia Obtener Datos las selecciones realizadas fueron para ProductID y la medida AveragePrice, entonces eso es definir una consulta sobre la vista, donde se solicitan esos datos agregados. En el ejemplo anterior, para simplificar pseudo-SQL se usa que no coincide con la sintaxis exacta de SAP HANA SQL. A continuación, las agregaciones adicionales definidas en una visualización realizan una agregación adicional de los resultados de dicha consulta. De nuevo, como se ha descrito anteriormente para SQL Server, este resultado se aplica tanto para el caso import como directQuery. En el caso de DirectQuery, la consulta de Obtener datos o del Editor de Power Query se usa en una subselección dentro de una consulta única enviada a SAP HANA y, por tanto, no se da el caso realmente de que se lean todos los datos antes de realizar más agregaciones.
Todas estas consideraciones y comportamientos requieren las siguientes consideraciones importantes al usar DirectQuery en SAP HANA como origen relacional:
Se debe prestar atención a cualquier agregación adicional realizada en objetos visuales, siempre que la medida en SAP HANA no sea aditiva, por ejemplo, que no sea una simple sum, mino max.
En Obtener datos o el Editor de Power Query, solo se deben incluir las columnas necesarias para recuperar los datos necesarios, lo que refleja el hecho de que el resultado es una consulta que debe ser una consulta razonable que se pueda enviar a SAP HANA. Por ejemplo, si se seleccionaron docenas de columnas, pensando que podrían ser necesarias en objetos visuales posteriores, incluso para DirectQuery, un objeto visual simple significa que la consulta de agregado usada en la subselección contiene esas docenas de columnas, que generalmente funcionan mal y pueden encontrar tiempos de espera.
En el ejemplo siguiente, la selección de cinco columnas (CalendarQuarter, Color, LastName, ProductLine, SalesOrderNumber) en el cuadro de diálogo Obtener datos, junto con la medida OrderQuantity, significa que la posterior creación de un objeto visual sencillo que contiene Min OrderQuantity dé como resultado la siguiente consulta de SQL a SAP HANA. La parte sombreada es la subselección, que contiene la consulta de Obtener datos/Editor de Power Query. Si esta subselección proporciona un resultado de cardinalidad alta, es probable que el rendimiento de SAP HANA resultante sea deficiente o encuentre tiempos de espera. El impacto en el rendimiento no se debe a que Power BI solicita todos los campos de la subconsulta; la consulta externa omitirá la mayoría de esos campos. En su lugar, el impacto se debe a las medidas de la subselección que lo obligan a materializarse en el servidor HANA.

Debido a este comportamiento, se recomienda que los elementos seleccionados en Obtener datos o el Editor de Power Query se limiten a los elementos necesarios, a la vez que se produce una consulta razonable para SAP HANA. Si es posible, considere la posibilidad de volver a crear todas las medidas necesarias en el modelo semántico y usar SAP HANA más como un origen relacional tradicional.
Procedimientos recomendados
Para que ambos métodos se conecten a SAP HANA, siga las recomendaciones generales para usar DirectQuery, especialmente las recomendaciones relacionadas con garantizar un buen rendimiento de las consultas. Para obtener más información, consulte mediante DirectQuery en Power BI.
Consideraciones y limitaciones
En la lista siguiente se describen todas las características de SAP HANA que no son totalmente compatibles o que se comportan de forma diferente al usar Power BI.
- Jerarquías de elementos primarios-secundarios: las jerarquías de elementos primarios-secundarios no serán visible en Power BI. Esto se debe a que Power BI accede a SAP HANA mediante la interfaz SQL y no se puede acceder a las jerarquías secundarias primarias mediante SQL.
- Otros metadatos de jerarquía: La estructura básica de las jerarquías se muestra en Power BI, pero algunos metadatos de jerarquía, como controlar el comportamiento de las jerarquías desiguales, no tienen ningún efecto. De nuevo, esto se debe a las limitaciones impuestas por la interfaz SQL.
- Conexión mediante SSL: Puede conectarse mediante Import y multidimensional con TLS, pero no puede conectarse a instancias de SAP HANA configuradas para usar TLS para el método de conexión relacional.
- Compatibilidad con Vistas de Atributos: Power BI puede conectarse a vistas analíticas y de cálculo, pero no puede conectarse directamente a la vista de atributo.
- Compatibilidad con objetos Catálogo: Power BI no se puede conectar a objetos Catálogo.
- Cambiar a variables después de publicar: No se pueden cambiar los valores de las variables de SAP HANA directamente en el servicio Power BI, una vez publicado el informe.
Problemas conocidos
En la lista siguiente se describen todos los problemas conocidos al conectarse a SAP HANA (DirectQuery) mediante Power BI.
Problema de SAP HANA al consultar los contadores y otras medidas: se devuelven datos incorrectos de SAP HANA al conectarse a una vista de análisis y hay una medida de contador, y alguna otra medida de relación, en el mismo objeto visual. Este problema está cubierto por nota de SAP 2128928 (resultados inesperados al consultar una columna calculada y un contador). La medida de proporción es incorrecta en este caso.
varias columnas de Power BI de una sola columna de SAP HANA: Para algunas vistas de cálculo, donde se usa una columna de SAP HANA en más de una jerarquía, SAP HANA expone la columna como dos atributos independientes. Este enfoque da como resultado dos columnas que se crean en Power BI. Sin embargo, esas columnas se ocultan de forma predeterminada y todas las consultas que implican las jerarquías o las columnas directamente se comportan correctamente.
Contenido relacionado
Para obtener más información sobre DirectQuery, consulte los siguientes recursos: