Recupere detalles de una página web
La extracción de información sobre las páginas web es una función esencial en la mayoría de los flujos web. La acción Obtener detalles de la página web le permite recuperar varios detalles de páginas web y gestionarlas en los flujos de escritorio.
Para usar la acción, necesita una instancia de navegador ya creada que especifique la página web de la que desea extraer detalles. Se puede crear una instancia de navegador con cualquier acción de inicio del navegador.
Después de seleccionar la instancia de navegador adecuada, elija la información que desea extraer de la página web. La acción Obtener detalles de la página web ofrece seis opciones diferentes:
- La descripción de la página web
- Las palabras clave meta de la página web
- El título de la página web
- El texto de la página web
- El código fuente de la página web
- La dirección URL de la página web
La información recuperada se almacena para su uso posterior en una variable de texto denominada WebPageProperty.

Evite errores al recuperar detalles
Aunque la mayoría de las propiedades existen prácticamente en todas las páginas web, hay escenarios en los que la acción Obtener detalles de la página web no puede recuperar el detalle seleccionado. Por ejemplo, las páginas web sin palabras clave meta son una ocurrencia común.
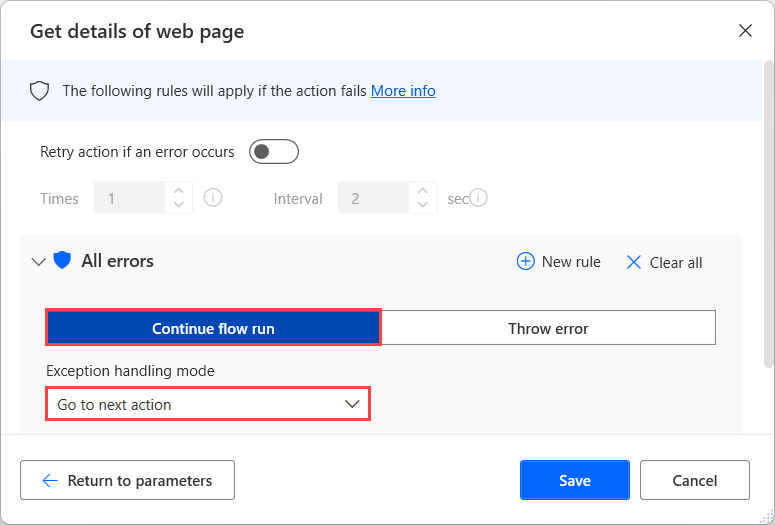
Si no está seguro de si existe un atributo en una página web, configure las opciones Al producirse un error de la acción Obtener detalles de la página web para continuar ejecutando el flujo después del error. Para obtener más información sobre el control de errores de la acción, consulte Gestionar errores en flujos de escritorio.
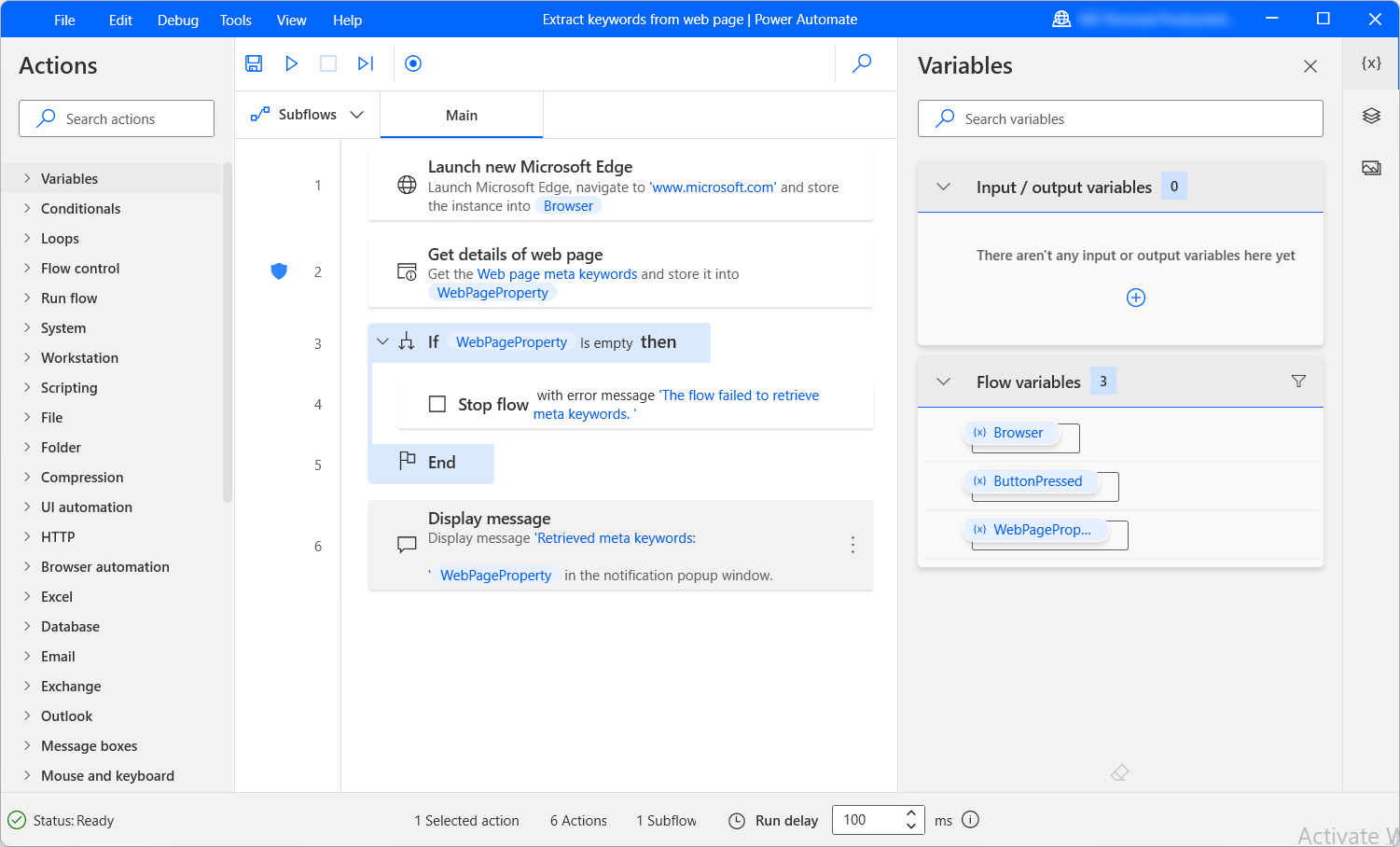
Para determinar si la extracción de datos es exitosa, utilice un If condicional para comprobar si la variable WebPageProperty está vacía o no.
El condicional le permite implementar diferentes funcionalidades para los casos de extracción de datos exitosos y no exitosos. Puede encontrar más información sobre condicionales en Uso de condicionales.
El siguiente subflujo de ejemplo recupera las palabras clave meta disponibles de una página web y las muestra en un cuadro de mensaje. Si la extracción no tiene éxito, el flujo se detiene y devuelve un mensaje de error.