Acciones OCR
Power Automate permite a los usuarios leer, extraer y administrar datos de archivos mediante reconocimiento óptico de caracteres (OCR).
Para crear un motor OCR y extraer texto de imágenes y documentos, use la acción Extraer texto con OCR. El siguiente ejemplo extrae texto de toda la imagen especificada.
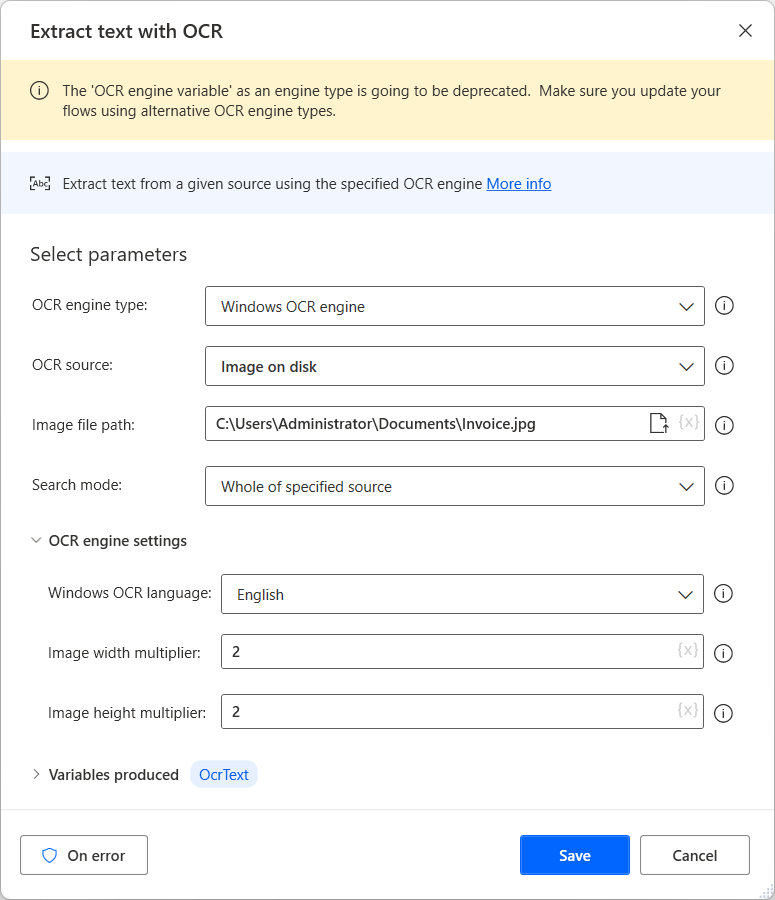
Todas las acciones de OCR pueden crear una nueva variable de motor de OCR o usar una existente. Puede usar variables del motor OCR ya existente en cualquier acción que ofrezca funciones OCR.
Power Automate admite el motor OCR de Windows y el motor Tesseract. Para configurar el motor de OCR seleccionado, vaya a la Configuración del motor OCR de la acción correspondiente. Las opciones disponibles incluyen el idioma y los multiplicadores de ancho y alto de la imagen.
Nota
- Todos los motores OCR disponibles están preinstalados en Power Automate y trabaje localmente sin conectarse a la nube. Sin embargo, es posible que deba descargar paquetes de idioma o archivos de datos para extraer textos en idiomas específicos.
- Los multiplicadores de imagen aumentan el tamaño de imagen para que la extracción de texto o la búsqueda sean más efectivas. Establecer valores más altos a tres puede dar lugar a resultados erróneos.
Usar el motor OCR de Windows
El motor predeterminado de OCR en Power Automate es el motor OCR de Windows. Para extraer textos con el motor OCR de Windows, debe instalar el paquete de idioma apropiado para el idioma que desea extraer.
Si no se ha instalado el paquete de idioma adecuado, Power Automate mostrará un error que le pedirá que lo instale. Puede encontrar más información sobre la descarga e instalación de paquetes de idioma en Paquetes de idioma para Windows.
Después de instalar el paquete de idioma adecuado, amplíe la Configuración del motor OCR de la acción OCR y seleccione el idioma que desee. El motor OCR de Windows admite 25 idiomas: incluyendo chino (simplificado y tradicional), checo, danés, holandés, inglés, finés, francés, alemán, griego, húngaro, italiano, japonés, coreano, noruego, polaco, portugués, rumano, ruso, serbio (cirílico y latino), eslovaco, español, sueco y turco.
Usar el motor OCR de Tesseract
Nota
Para utilizar el motor Tesseract OCR, asegúrese de que la CPU de la máquina admita el conjunto de instrucciones AVX2.
Aparte del motor OCR de Windows, Power Automate admite el motor Tesseract. Este motor puede extraer texto en cinco idiomas sin configuración adicional: inglés, alemán, español, francés e italiano.
Para extraer texto en un idioma fuera de la lista mencionada, habilite la opción Usar otros idiomas en la Configuración de motor OCR de la acción OCR. Cuando esta opción está habilitada, la acción muestra dos configuraciones: los campos Abreviatura del idioma y Ruta de datos de idioma.
El campo Abreviatura del idioma indica al motor qué idioma debe buscar durante la operación de OCR. El campo Ruta de datos de idioma contiene los archivos de datos de idioma (.traineddata) que se utilizan para entrenar el motor de OCR. Puede encontrar los archivos de datos de idioma para todos los idiomas disponibles en este repositorio de GitHub.
También puede usar el motor Tesseract para extraer texto de documentos multilingües. Puede encontrar más información sobre la extracción de texto de documentos multilingües en Realizar OCR en documentos multilingües.
Si hay texto en la pantalla (OCR)
Con OCR, marca el comienzo de un bloque de acciones condicional en función de si aparece o no un texto dado en la pantalla.
Parámetros de entrada
| Argumento | Opcionales | Acepta | Valor predeterminado | Descripción |
|---|---|---|---|---|
| If text | N/D | Existe, No existe | Existe | Especifica si se va a comprobar si el texto existe o no en el origen especificado para analizar |
| OCR engine type | No | Motor de Windows OCR, motor de Tesseract, variable de motor de OCR | OCR engine variable | El tipo de motor de OCR que se utilizará. Seleccione un motor OCR preconfigurado o configure uno nuevo. |
| OCR engine variable | No | OCREngineObject | Motor que se debe usar para la operación de OCR | |
| Text to find | No | Valor de texto | El texto que se buscará en el origen especificado | |
| Is regular expression | N/D | Valor booleano | False | Especifica si se debe usar una expresión regular para buscar el texto especificado |
| Search for text on | N/D | Toda la pantalla, Ventana en primer plano | Toda la pantalla | Especifica si se debe buscar el texto especificado en toda la pantalla visible o solo en la ventana en primer plano |
| Search mode | N/A | Toda la fuente especificada, Solo subregión específica, Subregión relativa a la imagen | Todo el origen especificado | Especifica si desea examinar la pantalla (o ventana) completa o solo una subregión menor de la misma |
| Imágenes | No | Lista de imágenes | Imagen o imágenes que especifican la subregión (respecto a la esquina superior izquierda de la imagen) para buscar el texto proporcionado | |
| X1 | Sí | Valor numérico | Coordenada X inicial de la subregión para buscar el texto proporcionado | |
| Tolerance | Sí | Valor numérico | 10 | Especifica en qué medida pueden variar las imágenes buscadas con respecto a la imagen elegida originalmente |
| Y1 | Sí | Valor numérico | Coordenada Y inicial de la subregión para buscar el texto proporcionado | |
| X1 | Sí | Valor numérico | Coordenada X inicial de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| X2 | Sí | Valor numérico | Coordenada X final de la subregión para buscar el texto proporcionado | |
| Y1 | Sí | Valor numérico | Coordenada Y inicial de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| Y2 | Sí | Valor numérico | Coordenada Y final de la subregión para buscar el texto proporcionado | |
| X2 | Sí | Valor numérico | Coordenada X final de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| Y2 | Sí | Valor numérico | Coordenada Y final de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| Idioma de Windows OCR | N/D | Chino (simplificado), chino (tradicional), checo, danés, holandés, inglés, finés, francés, alemán, griego, húngaro, italiano, japonés, coreano, noruego, polaco, portugués, rumano, ruso, serbio (cirílico), serbio (latino), eslovaco, español, sueco y turco | Inglés | El idioma del texto que detecta el motor de Windows OCR |
| Use other language | N/D | Valor booleano | False | Especifica si se debe usar un idioma no proporcionado en el campo "Idioma de Tesseract" |
| Tesseract language | N/D | Inglés, Alemán, Español, Francés, Italiano | Inglés | Idioma del texto que detecta el motor Tesseract |
| Language abbreviation | No | Valor de texto | La abreviación Tesseract del idioma que se va a usar. Por ejemplo, si los datos son "eng.traineddata", establezca este parámetro en "eng" | |
| Ruta de datos de idioma | No | Valor de texto | Ruta de acceso de la carpeta que contiene los datos de Tesseract del idioma especificado | |
| Image width multiplier | No | Valor numérico | 1 | Multiplicador de ancho de la imagen |
| Multiplicador de altura de la imagen | No | Valor numérico | 1 | Multiplicador de altura de la imagen |
| Imagen que coincide con el algoritmo | N/D | Básica, Avanzada | Básica | Qué algoritmo de imagen se usará al buscar imágenes |
Nota
- El motor de expresiones regulares de Power Automate es .NET. Puede encontrar más información sobre las expresiones regulares en Lenguaje de expresiones regulares - Referencia rápida.
- La opción Variable del motor de OCR está prevista para entrar en desuso.
Variables producidas
| Argumento | Type | Descripción |
|---|---|---|
| LocationOfTextFoundX | Valor numérico | La coordenada X del punto donde aparece el texto en la pantalla. Si la búsqueda se realiza en la ventana de primer plano, la coordenada devuelta es relativa a la esquina superior izquierda de la ventana |
| LocationOfTextFoundY | Valor numérico | La coordenada X del punto donde aparece el texto en la pantalla. Si la búsqueda se realiza en la ventana de primer plano, la coordenada devuelta es relativa a la esquina superior izquierda de la ventana |
Excepciones
| Excepción | Descripción |
|---|---|
| No se puede comprobar si existe texto en modo no interactivo | Indica que no se puede comprobar si hay texto en la pantalla cuando se está en modo no interactivo |
| Coordenadas de subregión no válidas | Indica que las coordenadas de la subregión especificada no son válidas |
| No se pudo analizar el texto con OCR | Indica que se ha producido un error al intentar analizar el texto mediante OCR |
| No se pudo crear el motor OCR | Indica que se ha producido un error al intentar crear el motor OCR |
| La carpeta de la ruta de los datos no existe | Indica que la carpeta especificada para los datos de idioma no existe |
| El paquete de idioma de Windows seleccionado no está instalada en la máquina | Indica que el paquete de idioma de Windows seleccionado no se ha instalado en la máquina |
| El motor OCR no está activo | Indica que el motor OCR no está activo |
Esperar al texto en la pantalla (OCR)
Espere a que un texto específico aparezca en la pantalla o desaparezca de ella, en la ventana en primer plano, o en relación con una imagen en la pantalla o en la ventana en primer plano mediante OCR.
Parámetros de entrada
| Argumento | Opcionales | Acepta | Valor predeterminado | Descripción |
|---|---|---|---|---|
| Wait for text to | N/D | Aparece, desaparece | Aparecer | Especifica si se debe esperar a que aparezca o desaparezca el texto |
| OCR engine type | No | Motor de Windows OCR, motor de Tesseract, variable de motor de OCR | OCR engine variable | El tipo de motor de OCR que se utilizará. Seleccione un motor OCR preconfigurado o configure uno nuevo. |
| OCR engine variable | No | OCREngineObject | Motor que se debe usar para la operación de OCR | |
| Text to find | No | Valor de texto | El texto que se buscará en el origen especificado | |
| Is regular expression | N/D | Valor booleano | False | Especifica si se debe usar una expresión regular para buscar el texto especificado |
| Search for text on | N/D | Toda la pantalla, Ventana en primer plano | Toda la pantalla | Especifica si se debe buscar el texto especificado en toda la pantalla visible o solo en la ventana en primer plano |
| Search mode | N/A | Toda la fuente especificada, Solo subregión específica, Subregión relativa a la imagen | Todo el origen especificado | Especifica si desea examinar la pantalla (o ventana) completa o solo una subregión menor de la misma |
| Imágenes | No | Lista de imágenes | Imagen o imágenes que especifican la subregión (respecto a la esquina superior izquierda de la imagen) para buscar el texto proporcionado | |
| X1 | Sí | Valor numérico | Coordenada X inicial de la subregión para buscar el texto proporcionado | |
| Tolerance | Sí | Valor numérico | 10 | Especifica en qué medida pueden variar las imágenes buscadas con respecto a la imagen elegida originalmente |
| Y1 | Sí | Valor numérico | Coordenada Y inicial de la subregión para buscar el texto proporcionado | |
| X1 | Sí | Valor numérico | Coordenada X inicial de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| X2 | Sí | Valor numérico | Coordenada X final de la subregión para buscar el texto proporcionado | |
| Y1 | Sí | Valor numérico | Coordenada Y inicial de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| Y2 | Sí | Valor numérico | Coordenada Y final de la subregión para buscar el texto proporcionado | |
| X2 | Sí | Valor numérico | Coordenada X final de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| Y2 | Sí | Valor numérico | Coordenada Y final de la subregión relativa a la imagen especificada para buscar el texto proporcionado | |
| Idioma de Windows OCR | N/D | Chino (simplificado), chino (tradicional), checo, danés, holandés, inglés, finés, francés, alemán, griego, húngaro, italiano, japonés, coreano, noruego, polaco, portugués, rumano, ruso, serbio (cirílico), serbio (latino), eslovaco, español, sueco y turco | Inglés | El idioma del texto que detecta el motor de Windows OCR |
| Use other language | N/D | Valor booleano | False | Especifica si se debe usar un idioma no proporcionado en el campo "Idioma de Tesseract" |
| Tesseract language | N/D | Inglés, Alemán, Español, Francés, Italiano | Inglés | Idioma del texto que detecta el motor Tesseract |
| Language abbreviation | No | Valor de texto | La abreviación Tesseract del idioma que se va a usar. Por ejemplo, si los datos son "eng.traineddata", establezca este parámetro en "eng" | |
| Ruta de datos de idioma | No | Valor de texto | Ruta de acceso de la carpeta que contiene los datos de Tesseract del idioma especificado | |
| Image width multiplier | No | Valor numérico | 1 | Multiplicador de ancho de la imagen |
| Multiplicador de altura de la imagen | No | Valor numérico | 1 | Multiplicador de altura de la imagen |
| Imagen que coincide con el algoritmo | N/D | Básica, Avanzada | Básica | Qué algoritmo de imagen se usará al buscar imágenes |
| No se pudo realizar con error de tiempo de espera | N/D | Valor booleano | Falso | Especificar si se desea que la acción espere de forma indefinida o que se produzca un error después de un período de tiempo establecido |
Nota
- El motor de expresiones regulares de Power Automate es .NET. Puede encontrar más información sobre las expresiones regulares en Lenguaje de expresiones regulares - Referencia rápida.
- La opción Variable del motor de OCR está prevista para entrar en desuso.
Variables producidas
| Argumento | Type | Descripción |
|---|---|---|
| LocationOfTextFoundX | Valor numérico | La coordenada X del punto donde aparece el texto en la pantalla. Si la búsqueda se realiza en la ventana de primer plano, la coordenada devuelta es relativa a la esquina superior izquierda de la ventana |
| LocationOfTextFoundY | Valor numérico | La coordenada X del punto donde aparece el texto en la pantalla. Si la búsqueda se realiza en la ventana de primer plano, la coordenada devuelta es relativa a la esquina superior izquierda de la ventana |
Excepciones
| Excepción | Descripción |
|---|---|
| No se puede comprobar si existe texto en modo no interactivo | Indica que no se puede comprobar si hay texto en la pantalla cuando se está en modo no interactivo |
| Coordenadas de subregión no válidas | Indica que las coordenadas de la subregión especificada no son válidas |
| No se pudo analizar el texto con OCR | Indica que se ha producido un error al intentar analizar el texto mediante OCR |
| No se pudo crear el motor OCR | Indica que se ha producido un error al intentar crear el motor OCR |
| La carpeta de la ruta de los datos no existe | Indica que la carpeta especificada para los datos de idioma no existe |
| El paquete de idioma de Windows seleccionado no está instalada en la máquina | Indica que el paquete de idioma de Windows seleccionado no se ha instalado en la máquina |
| El motor OCR no está activo | Indica que el motor OCR no está activo |
| Error de tiempo de espera | Indica que la se produzco una error en la acción después de un período de tiempo establecido |
Extraer texto con OCR
Extraer texto de un origen determinado con el motor OCR especificado.
Parámetros de entrada
| Argumento | Opcionales | Acepta | Valor predeterminado | Descripción |
|---|---|---|---|---|
| OCR engine | No | Motor de Windows OCR, motor de Tesseract, variable de motor de OCR | OCR engine variable | El tipo de motor de OCR que se utilizará. Seleccione un motor OCR preconfigurado o configure uno nuevo |
| Variable del motor OCR | No | OCREngineObject | Motor que se debe usar para la operación de OCR | |
| OCR source | N/D | Pantalla, Ventana en primer plano, Imagen en disco | Pantalla | Origen de la imagen en la que se realizará la operación de OCR |
| Image file path | No | Archivo | Ruta de la imagen en la que se realizará la operación de OCR | |
| Search mode | N/D | Toda la fuente especificada, Solo subregión específica, Subregión relativa a la imagen | Todo el origen especificado | Modo seleccionado para la operación de OCR |
| Imagen | No | Lista de imágenes | Imagen que se usará para restringir el escáner a una subregión que sea relativa a la imagen especificada | |
| Tolerance | Sí | Valor numérico | 10 | Especifica en qué medida puede variar la imagen con respecto a la imagen elegida originalmente |
| X1 | Sí | Valor numérico | Coordenada X inicial de la subregión para limitar la exploración | |
| X2 | Sí | Valor numérico | Coordenada X final de la subregión para limitar la exploración | |
| Y1 | Sí | Valor numérico | Coordenada Y inicial de la subregión para limitar la exploración | |
| Y2 | Sí | Valor numérico | Coordenada Y final de la subregión para limitar la exploración | |
| Idioma de Windows OCR | N/D | Chino (simplificado), chino (tradicional), checo, danés, holandés, inglés, finés, francés, alemán, griego, húngaro, italiano, japonés, coreano, noruego, polaco, portugués, rumano, ruso, serbio (cirílico), serbio (latino), eslovaco, español, sueco y turco | Inglés | El idioma del texto que detecta el motor de Windows OCR |
| Use other language | N/D | Valor booleano | False | Especifica si se debe usar un idioma no proporcionado en el campo "Idioma de Tesseract" |
| Tesseract language | N/D | Inglés, Alemán, Español, Francés, Italiano | Inglés | Idioma del texto que detecta el motor Tesseract |
| Language abbreviation | No | Valor de texto | La abreviación Tesseract del idioma que se va a usar. Por ejemplo, si los datos son "eng.traineddata", establezca este parámetro en "eng" | |
| Ruta de datos de idioma | No | Valor de texto | Ruta de acceso de la carpeta que contiene los datos de Tesseract del idioma especificado | |
| Image width multiplier | No | Valor numérico | 1 | Multiplicador de ancho de la imagen |
| Image height multiplier | No | Valor numérico | 1 | Multiplicador de altura de la imagen |
| Esperar hasta que aparezca la imagen | N/D | Valor booleano | VERDADERO | Especifica si se debe esperar o no a que aparezca la imagen en la pantalla o ventana en primer plano |
| Tiempo de espera | No | Valor numérico | 5 | Especifica el tiempo que se debe esperar para que se complete la operación antes de que se produzca un error en la acción |
| Imagen que coincide con el algoritmo | N/D | Básica, Avanzada | Básica | Qué algoritmo de imagen se usará al buscar imágenes |
Nota
La opción Variable del motor de OCR está prevista para entrar en desuso.
Variables producidas
| Argumento | Type | Descripción |
|---|---|---|
| OcrText | Valor de texto | El resultado posterior a la extracción de texto |
Excepciones
| Excepción | Descripción |
|---|---|
| No se pudo extraer texto con OCR | Indica que se ha producido un error al intentar extraer texto con OCR desde el origen especificado |
| No se encontró el archivo de imagen | Indica que el archivo no existe en la ruta de acceso especificada |
| No se encontró la imagen de referencia | Indica que la imagen de referencia no existe |
| No se puede obtener el texto en la pantalla en modo no interactivo | Indica que no se puede obtener el texto en la pantalla cuando se está en modo no interactivo |
| No se pudo crear el motor OCR | Indica que se ha producido un error al intentar crear el motor OCR |
| La carpeta de la ruta de los datos no existe | Indica que la carpeta especificada para los datos de idioma no existe |
| El paquete de idioma de Windows seleccionado no está instalada en la máquina | Indica que el paquete de idioma de Windows seleccionado no se ha instalado en la máquina |
| El motor OCR no está activo | Indica que el motor OCR no está activo |