Creación de un bot rag en Teams
Los bots de chat avanzados de Q&A son aplicaciones eficaces creadas con la ayuda de modelos de lenguaje grande (LLM). Los bots de chat responden a preguntas mediante la extracción de información de orígenes específicos mediante un método denominado generación de Retrieval-Augmented (RAG). La arquitectura rag tiene dos flujos principales:
Ingesta de datos: una canalización para ingerir datos de un origen e indexarlos. Esto suele ocurrir sin conexión.
Recuperación y generación: la cadena RAG, que toma la consulta del usuario en tiempo de ejecución y recupera los datos pertinentes del índice, los pasa al modelo.
Microsoft Teams le permite crear un bot conversacional con RAG para crear una experiencia mejorada con el fin de maximizar la productividad. Teams Toolkit proporciona una serie de plantillas de aplicación listas para usar en la categoría Chat con sus datos que combina las funcionalidades de búsqueda de Azure AI, Microsoft 365 SharePoint y API personalizada como orígenes de datos y LLM diferentes para crear una experiencia de búsqueda conversacional en Teams.
Requisitos previos
| Instalar | Para usar... |
|---|---|
| Visual Studio Code | Entornos de compilación de JavaScript, TypeScript o Python. Use la versión más reciente. |
| Kit de herramientas de Teams | Microsoft Visual Studio Code extensión que crea un scaffolding de proyecto para la aplicación. Use la versión más reciente. |
| Node.js | Entorno de tiempo de ejecución de JavaScript de back-end. Para obtener más información, vea Node.js tabla de compatibilidad de versiones para el tipo de proyecto. |
| Microsoft Teams | Microsoft Teams para colaborar con todos los usuarios con los que trabaje a través de aplicaciones para chat, reuniones y llamadas en un solo lugar. |
| Azure OpenAI | En primer lugar, cree la clave de API de OpenAI para usar el transformador preentrenado generativo (GPT) de OpenAI. Si desea hospedar la aplicación o acceder a los recursos en Azure, debe crear un servicio Azure OpenAI. |
Creación de un nuevo proyecto básico de bot de chat de IA
Abra Visual Studio Code.
Seleccione el icono Kit de herramientas de
 Teams en la barra de actividad de Visual Studio Code.
Teams en la barra de actividad de Visual Studio Code.Seleccione Crear una nueva aplicación.
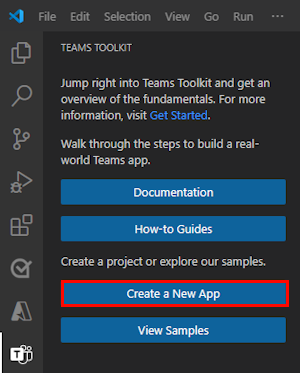
Seleccione Agente de motor personalizado.
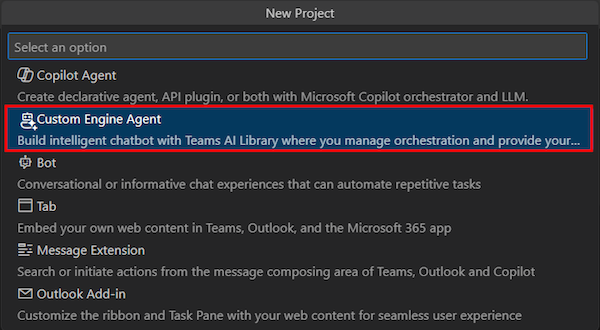
Seleccione Chatear con sus datos.
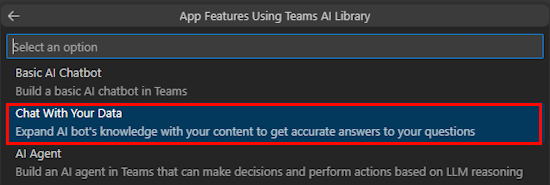
Seleccione Personalizar.
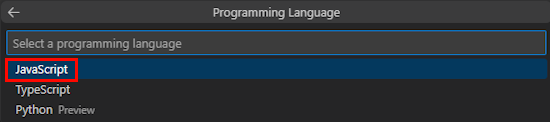
Seleccione JavaScript.
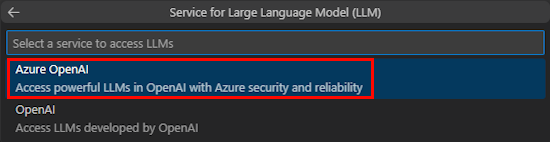
Seleccione Azure OpenAI o OpenAI.
Escriba las credenciales de Azure OpenAI o OpenAI en función del servicio que seleccione. Seleccione Introducir.

Seleccione Carpeta predeterminada.

Para cambiar la ubicación predeterminada, siga estos pasos:
- Seleccione Examinar.
- Seleccione la ubicación del área de trabajo del proyecto.
- Seleccione Seleccionar carpeta.
Escriba un nombre de aplicación para la aplicación y, a continuación, seleccione la tecla Entrar .

Ha creado correctamente el área de trabajo del proyecto Chat con los datos .
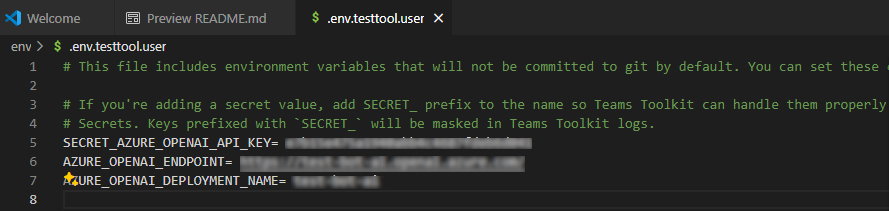
En EXPLORER, vaya al archivo env.env.testtool.user>.
Actualice los valores siguientes:
SECRET_AZURE_OPENAI_API_KEY=<your-key>AZURE_OPENAI_ENDPOINT=<your-endpoint>AZURE_OPENAI_DEPLOYMENT_NAME=<your-deployment>
Para depurar la aplicación, seleccione la tecla F5 o en el panel izquierdo, seleccione Ejecutar y depurar (Ctrl+Mayús+D) y, a continuación, seleccione Depurar en la herramienta de prueba (versión preliminar) en la lista desplegable.
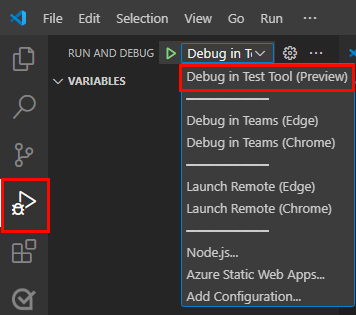
La herramienta de prueba abre el bot en una página web.

Realice un recorrido por el código fuente de la aplicación bot.
| Folder | Contenido |
|---|---|
.vscode |
Visual Studio Code archivos para la depuración. |
appPackage |
Plantillas para el manifiesto de aplicación de Teams. |
env |
Archivos de entorno. |
infra |
Plantillas para aprovisionar recursos de Azure. |
src |
Código fuente de la aplicación. |
src/index.js |
Configura el servidor de aplicaciones de bot. |
src/adapter.js |
Configura el adaptador del bot. |
src/config.js |
Define las variables de entorno. |
src/prompts/chat/skprompt.txt |
Define el símbolo del sistema. |
src/prompts/chat/config.json |
Configura el símbolo del sistema. |
src/app/app.js |
Controla las lógicas de negocios para el bot RAG. |
src/app/myDataSource.js |
Define el origen de datos. |
src/data/*.md |
Orígenes de datos de texto sin formato. |
teamsapp.yml |
Este es el archivo de proyecto principal del kit de herramientas de Teams. El archivo de proyecto define las propiedades y las definiciones de la fase de configuración. |
teamsapp.local.yml |
Esto invalida teamsapp.yml con acciones que habilitan la ejecución y depuración locales. |
teamsapp.testtool.yml |
Esto invalida teamsapp.yml con acciones que habilitan la ejecución y depuración locales en la herramienta de prueba de aplicaciones de Teams. |
Escenarios de RAG para la inteligencia artificial de Teams
En el contexto de IA, las bases de datos vectoriales se usan ampliamente como almacenamientos RAG, que almacenan datos de incrustaciones y proporcionan búsqueda de similitud vectorial. La biblioteca de inteligencia artificial de Teams proporciona utilidades para ayudar a crear inserciones para las entradas especificadas.
Sugerencia
La biblioteca de inteligencia artificial de Teams no proporciona la implementación de la base de datos vectorial, por lo que debe agregar su propia lógica para procesar las incrustaciones creadas.
// create OpenAIEmbeddings instance
const model = new OpenAIEmbeddings({ ... endpoint, apikey, model, ... });
// create embeddings for the given inputs
const embeddings = await model.createEmbeddings(model, inputs);
// your own logic to process embeddings
En el diagrama siguiente se muestra cómo la biblioteca de inteligencia artificial de Teams proporciona funcionalidades para facilitar cada paso del proceso de recuperación y generación:
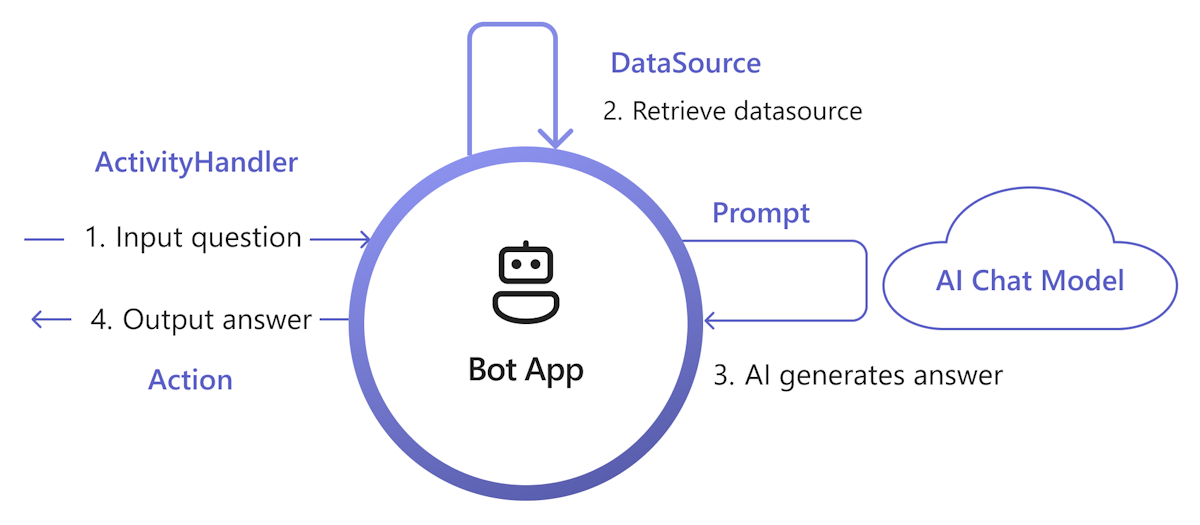
Controlar la entrada: la manera más directa es pasar la entrada del usuario a la recuperación sin ningún cambio. Sin embargo, si desea personalizar la entrada antes de la recuperación, puede agregar un controlador de actividad a determinadas actividades entrantes.
Recuperar DataSource: la biblioteca de IA de Teams proporciona
DataSourceuna interfaz que le permite agregar su propia lógica de recuperación. Debe crear su propiaDataSourceinstancia y la biblioteca de inteligencia artificial de Teams la llama a petición.class MyDataSource implements DataSource { /** * Name of the data source. */ public readonly name = "my-datasource"; /** * Renders the data source as a string of text. * @param context Turn context for the current turn of conversation with the user. * @param memory An interface for accessing state values. * @param tokenizer Tokenizer to use when rendering the data source. * @param maxTokens Maximum number of tokens allowed to be rendered. * @returns The text to inject into the prompt as a `RenderedPromptSection` object. */ renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { ... } }Llame a IA con aviso: en el sistema de avisos de IA de Teams, puede insertar fácilmente un
DataSourcemediante el ajuste de laaugmentation.data_sourcessección de configuración. Esto conecta el símbolo del sistema con elDataSourceorquestador y la biblioteca para insertar elDataSourcetexto en el símbolo del sistema final. Para obtener más información, consulte authorprompt. Por ejemplo, en el archivo del símbolo delconfig.jsonsistema:{ "schema": 1.1, ... "augmentation": { "data_sources": { "my-datasource": 1200 } } }Respuesta de compilación: de forma predeterminada, la biblioteca de inteligencia artificial de Teams responde a la respuesta generada por IA como un mensaje de texto para el usuario. Si desea personalizar la respuesta, puede invalidar las acciones SAY predeterminadas o llamar explícitamente al modelo de inteligencia artificial para compilar las respuestas, por ejemplo, con tarjetas adaptables.
Este es un conjunto mínimo de implementaciones para agregar RAG a la aplicación. En general, implementa DataSource para insertar knowledge en el símbolo del sistema, de modo que la inteligencia artificial pueda generar una respuesta basada en knowledge.
Cree
myDataSource.tsun archivo para implementarDataSourcela interfaz:export class MyDataSource implements DataSource { public readonly name = "my-datasource"; public async renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { const input = memory.getValue('temp.input') as string; let knowledge = "There's no knowledge found."; // hard-code knowledge if (input?.includes("shuttle bus")) { knowledge = "Company's shuttle bus may be 15 minutes late on rainy days."; } else if (input?.includes("cafe")) { knowledge = "The Cafe's available time is 9:00 to 17:00 on working days and 10:00 to 16:00 on weekends and holidays." } return { output: knowledge, length: knowledge.length, tooLong: false } } }Registre el
DataSourcearchivo enapp.ts:// Register your data source to prompt manager planner.prompts.addDataSource(new MyDataSource());
Cree el
prompts/qa/skprompt.txtarchivo y agregue el texto siguiente:The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly to answer user's question. Base your answer off the text below:Cree el
prompts/qa/config.jsonarchivo y agregue el código siguiente para conectarse con el origen de datos:{ "schema": 1.1, "description": "Chat with QA Assistant", "type": "completion", "completion": { "model": "gpt-35-turbo", "completion_type": "chat", "include_history": true, "include_input": true, "max_input_tokens": 2800, "max_tokens": 1000, "temperature": 0.9, "top_p": 0.0, "presence_penalty": 0.6, "frequency_penalty": 0.0, "stop_sequences": [] }, "augmentation": { "data_sources": { "my-datasource": 1200 } } }
Selección de orígenes de datos
En los escenarios Chat with Your Data o RAG, Teams Toolkit proporciona los siguientes tipos de orígenes de datos:
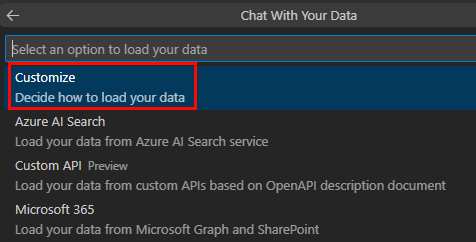
Personalizar: permite controlar completamente la ingesta de datos para compilar su propio índice vectorial y usarlo como origen de datos. Para obtener más información, consulte Compilación de su propia ingesta de datos.
También puede usar la extensión de base de datos vectorial de Azure Cosmos DB o la extensión vector del servidor de Azure PostgreSQL como bases de datos vectoriales, o Bing Web Search API para obtener el contenido web más reciente para implementar cualquier instancia de origen de datos para conectarse con su propio origen de datos.
Azure AI Search: proporciona un ejemplo para agregar los documentos a Azure AI Search Service y, a continuación, usar el índice de búsqueda como origen de datos.
API personalizada: permite que el bot de chat invoque la API definida en el documento de descripción de OpenAPI para recuperar datos de dominio del servicio de API.
Microsoft Graph y SharePoint: proporciona un ejemplo para usar el contenido de Microsoft 365 de Microsoft Graph Search API como origen de datos.
Creación de su propia ingesta de datos
Para compilar la ingesta de datos, siga estos pasos:
Cargar los documentos de origen: asegúrese de que el documento tiene un texto significativo, ya que el modelo de inserción solo toma texto como entrada.
Dividir en fragmentos: asegúrese de dividir el documento para evitar errores de llamada api, ya que el modelo de inserción tiene una limitación de token de entrada.
Modelo de inserción de llamadas: llame a las API del modelo de inserción para crear inserciones para las entradas especificadas.
Almacenar incrustaciones: almacene las incrustaciones creadas en una base de datos vectorial. Incluya también metadatos útiles y contenido sin procesar para seguir haciendo referencia.
Código de ejemplo
loader.ts: texto sin formato como entrada de origen.import * as fs from "node:fs"; export function loadTextFile(path: string): string { return fs.readFileSync(path, "utf-8"); }splitter.ts: divida el texto en fragmentos, con una superposición.// split words by delimiters. const delimiters = [" ", "\t", "\r", "\n"]; export function split(content: string, length: number, overlap: number): Array<string> { const results = new Array<string>(); let cursor = 0, curChunk = 0; results.push(""); while(cursor < content.length) { const curChar = content[cursor]; if (delimiters.includes(curChar)) { // check chunk length while (curChunk < results.length && results[curChunk].length >= length) { curChunk ++; } for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } if (results[results.length - 1].length >= length - overlap) { results.push(""); } } else { // append for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } } cursor ++; } while (curChunk < results.length - 1) { results.pop(); } return results; }embeddings.ts: use la bibliotecaOpenAIEmbeddingsde inteligencia artificial de Teams para crear inserciones.import { OpenAIEmbeddings } from "@microsoft/teams-ai"; const embeddingClient = new OpenAIEmbeddings({ azureApiKey: "<your-aoai-key>", azureEndpoint: "<your-aoai-endpoint>", azureDeployment: "<your-embedding-deployment, e.g., text-embedding-ada-002>" }); export async function createEmbeddings(content: string): Promise<number[]> { const response = await embeddingClient.createEmbeddings(content); return response.output[0]; }searchIndex.ts: cree un índice de Azure AI Search.import { SearchIndexClient, AzureKeyCredential, SearchIndex } from "@azure/search-documents"; const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const indexDef: SearchIndex = { name: indexName, fields: [ { type: "Edm.String", name: "id", key: true, }, { type: "Edm.String", name: "content", searchable: true, }, { type: "Edm.String", name: "filepath", searchable: true, filterable: true, }, { type: "Collection(Edm.Single)", name: "contentVector", searchable: true, vectorSearchDimensions: 1536, vectorSearchProfileName: "default" } ], vectorSearch: { algorithms: [{ name: "default", kind: "hnsw" }], profiles: [{ name: "default", algorithmConfigurationName: "default" }] }, semanticSearch: { defaultConfigurationName: "default", configurations: [{ name: "default", prioritizedFields: { contentFields: [{ name: "content" }] } }] } }; export async function createNewIndex(): Promise<void> { const client = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey)); await client.createIndex(indexDef); }searchIndexer.ts: cargue las incrustaciones creadas y otros campos en azure AI Search Index.import { AzureKeyCredential, SearchClient } from "@azure/search-documents"; export interface Doc { id: string, content: string, filepath: string, contentVector: number[] } const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const searchClient: SearchClient<Doc> = new SearchClient<Doc>(endpoint, indexName, new AzureKeyCredential(apiKey)); export async function indexDoc(doc: Doc): Promise<boolean> { const response = await searchClient.mergeOrUploadDocuments([doc]); return response.results.every((result) => result.succeeded); }index.ts: organice los componentes anteriores.import { createEmbeddings } from "./embeddings"; import { loadTextFile } from "./loader"; import { createNewIndex } from "./searchIndex"; import { indexDoc } from "./searchIndexer"; import { split } from "./splitter"; async function main() { // Only need to call once await createNewIndex(); // local files as source input const files = [`${__dirname}/data/A.md`, `${__dirname}/data/A.md`]; for (const file of files) { // load file const fullContent = loadTextFile(file); // split into chunks const contents = split(fullContent, 1000, 100); let partIndex = 0; for (const content of contents) { partIndex ++; // create embeddings const embeddings = await createEmbeddings(content); // upload to index await indexDoc({ id: `${file.replace(/[^a-z0-9]/ig, "")}___${partIndex}`, content: content, filepath: file, contentVector: embeddings, }); } } } main().then().finally();
Azure AI Search como origen de datos
En esta sección aprenderá a:
- Agregue el documento a Azure AI Search a través del servicio Azure OpenAI.
- Use el índice de Azure AI Search como origen de datos en la aplicación RAG.
Adición de un documento a Azure AI Search
Nota:
Este enfoque crea una API de chat de un extremo a otro denominada modelo de inteligencia artificial. También puede usar el índice creado anteriormente como origen de datos y usar la biblioteca de inteligencia artificial de Teams para personalizar la recuperación y la solicitud.
Puede ingerir los documentos de conocimiento en Azure AI Search Service y crear un índice vectorial con Azure OpenAI en los datos. Después de la ingesta, puede usar el índice como origen de datos.
Prepare los datos en Azure Blob Storage.
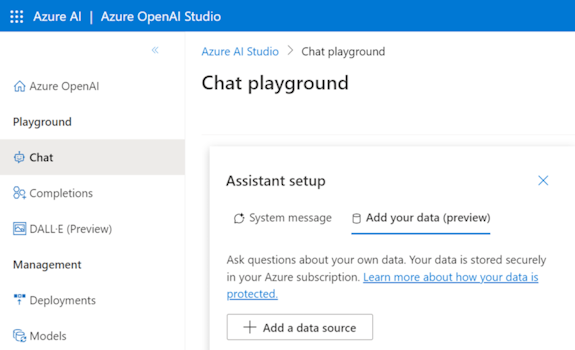
En Azure OpenAI Studio, seleccione Agregar un origen de datos.
Actualice los campos necesarios.
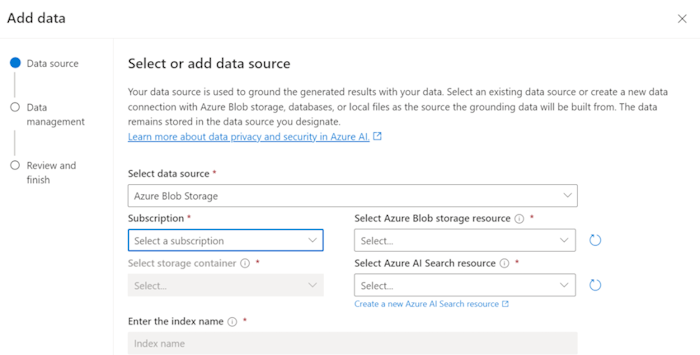
Seleccione Siguiente.
Aparece la página Administración de datos .
Actualice los campos necesarios.
Seleccione Siguiente.
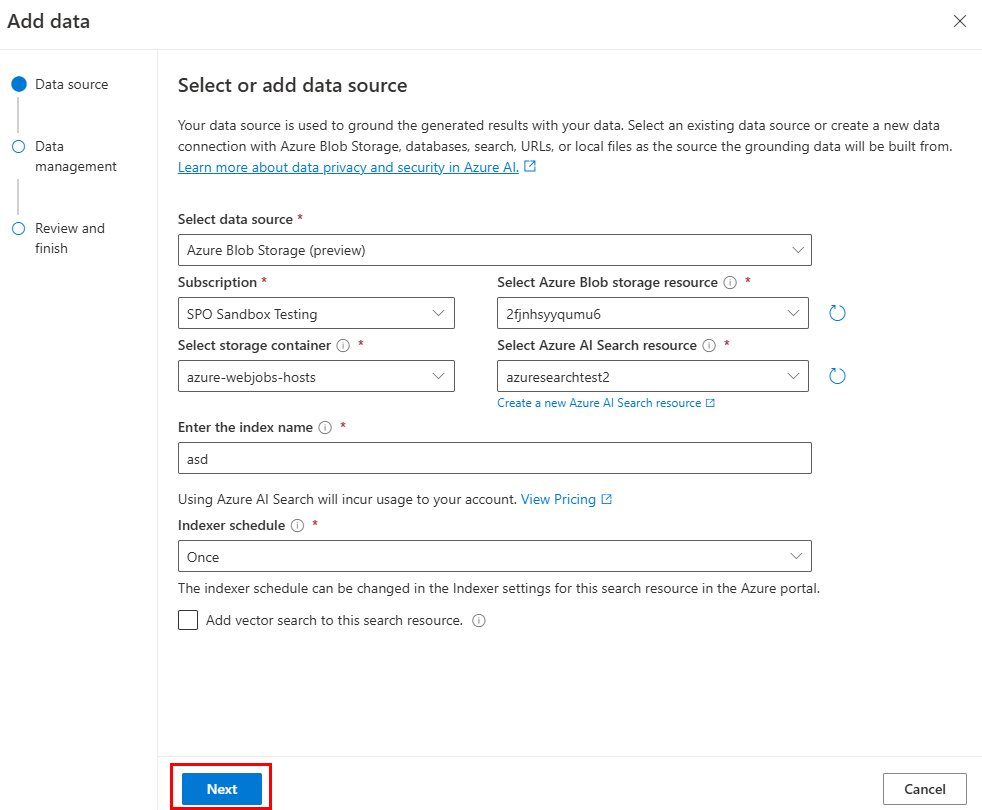
Actualice los campos necesarios. Seleccione Siguiente.
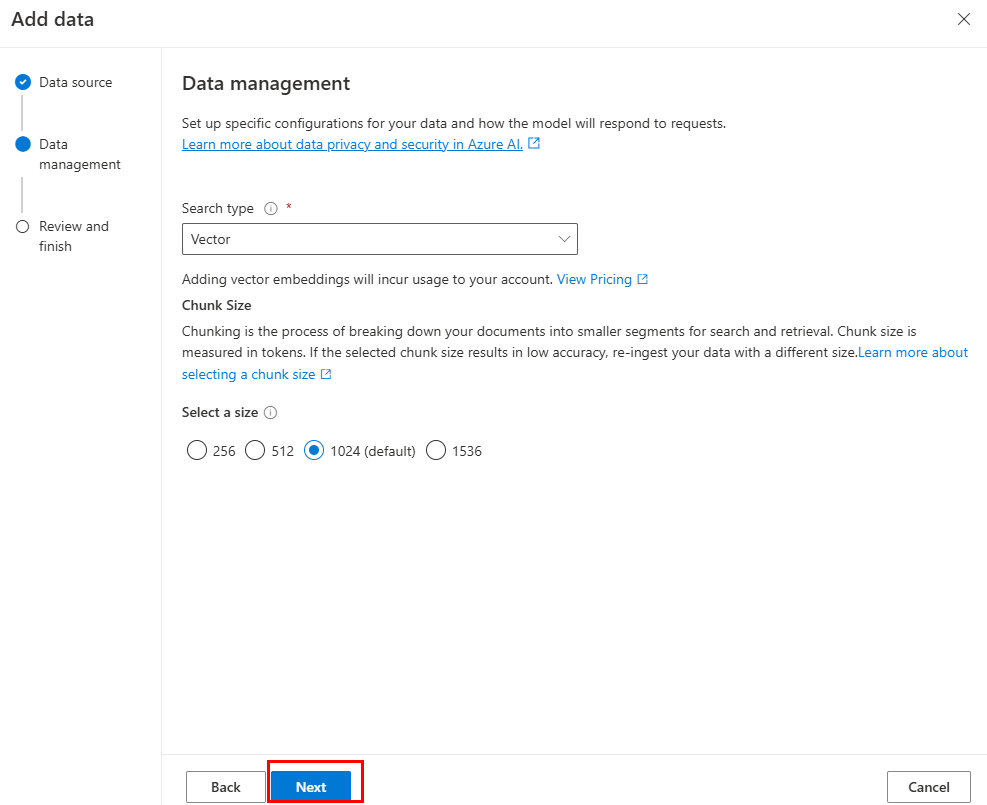
Seleccione Guardar y cerrar.
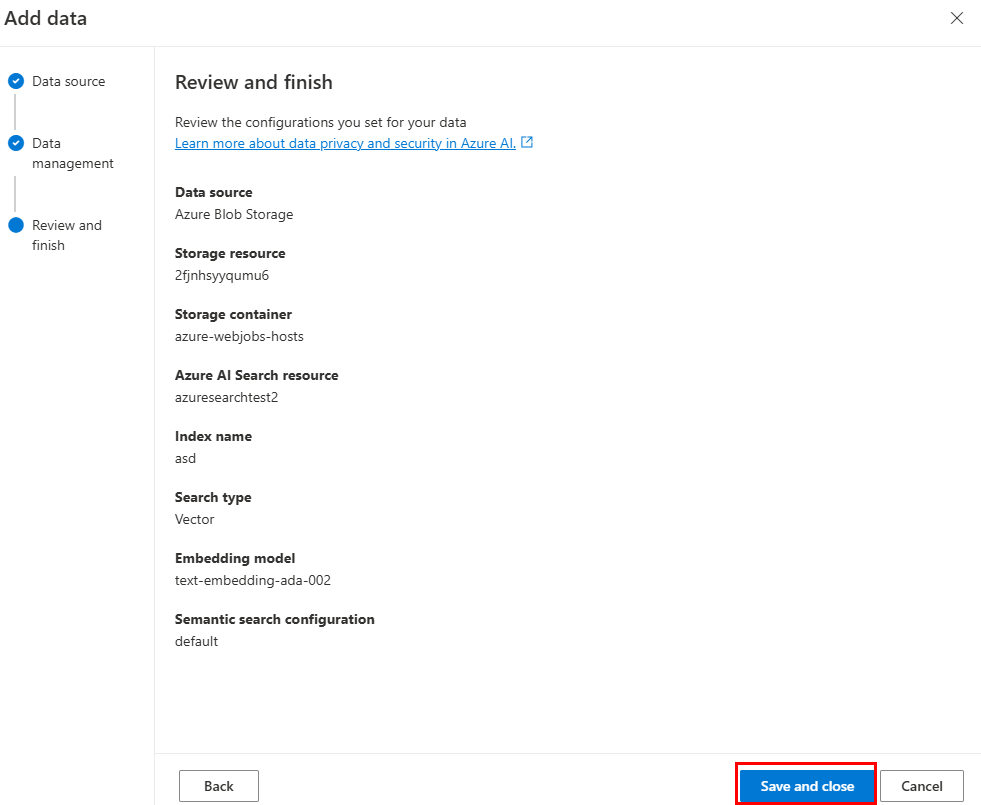
Uso del origen de datos del índice de Azure AI Search
Después de ingerir datos en Azure AI Search, puede implementar los suyos propios DataSource para recuperar datos del índice de búsqueda.
const { AzureKeyCredential, SearchClient } = require("@azure/search-documents");
const { DataSource, Memory, OpenAIEmbeddings, Tokenizer } = require("@microsoft/teams-ai");
const { TurnContext } = require("botbuilder");
// Define the interface for document
class Doc {
constructor(id, content, filepath) {
this.id = id;
this.content = content; // searchable
this.filepath = filepath;
}
}
// Azure OpenAI configuration
const aoaiEndpoint = "<your-aoai-endpoint>";
const aoaiApiKey = "<your-aoai-key>";
const aoaiDeployment = "<your-embedding-deployment, e.g., text-embedding-ada-002>";
// Azure AI Search configuration
const searchEndpoint = "<your-search-endpoint>";
const searchApiKey = "<your-search-apikey>";
const searchIndexName = "<your-index-name>";
// Define MyDataSource class implementing DataSource interface
class MyDataSource extends DataSource {
constructor() {
super();
this.name = "my-datasource";
this.embeddingClient = new OpenAIEmbeddings({
azureEndpoint: aoaiEndpoint,
azureApiKey: aoaiApiKey,
azureDeployment: aoaiDeployment
});
this.searchClient = new SearchClient(searchEndpoint, searchIndexName, new AzureKeyCredential(searchApiKey));
}
async renderData(context, memory, tokenizer, maxTokens) {
// use user input as query
const input = memory.getValue("temp.input");
// generate embeddings
const embeddings = (await this.embeddingClient.createEmbeddings(input)).output[0];
// query Azure AI Search
const response = await this.searchClient.search(input, {
select: [ "id", "content", "filepath" ],
searchFields: ["rawContent"],
vectorSearchOptions: {
queries: [{
kind: "vector",
fields: [ "contentVector" ],
vector: embeddings,
kNearestNeighborsCount: 3
}]
},
queryType: "semantic",
top: 3,
semanticSearchOptions: {
// your semantic configuration name
configurationName: "default",
}
});
// Add documents until you run out of tokens
let length = 0, output = '';
for await (const result of response.results) {
// Start a new doc
let doc = `${result.document.content}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append doc to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
}
Adición de más API para Custom API como origen de datos
Siga estos pasos para ampliar el agente de motor personalizado desde la plantilla de API personalizada con más API.
Actualice
./appPackage/apiSpecificationFile/openapi.*.Copie la parte correspondiente de la API que desea agregar desde la especificación y anexe a
./appPackage/apiSpecificationFile/openapi.*.Actualice
./src/prompts/chat/actions.json.Actualice la información y las propiedades necesarias para la ruta de acceso, la consulta y el cuerpo de la API en el objeto siguiente:
{ "name": "${{YOUR-API-NAME}}", "description": "${{YOUR-API-DESCRIPTION}}", "parameters": { "type": "object", "properties": { "query": { "type": "object", "properties": { "${{YOUR-PROPERTY-NAME}}": { "type": "${{YOUR-PROPERTY-TYPE}}", "description": "${{YOUR-PROPERTY-DESCRIPTION}}", } // You can add more query properties here } }, "path": { // Same as query properties }, "body": { // Same as query properties } } } }Actualice
./src/adaptiveCards.Cree un nuevo archivo con el nombre
${{YOUR-API-NAME}}.jsony rellene la tarjeta adaptable para la respuesta de api de la API.Actualice el
./src/app/app.jsarchivo.Agregue el código siguiente antes de
module.exports = app;:app.ai.action(${{YOUR-API-NAME}}, async (context: TurnContext, state: ApplicationTurnState, parameter: any) => { const client = await api.getClient(); const path = client.paths[${{YOUR-API-PATH}}]; if (path && path.${{YOUR-API-METHOD}}) { const result = await path.${{YOUR-API-METHOD}}(parameter.path, parameter.body, { params: parameter.query, }); const card = generateAdaptiveCard("../adaptiveCards/${{YOUR-API-NAME}}.json", result); await context.sendActivity({ attachments: [card] }); } else { await context.sendActivity("no result"); } return "result"; });
Microsoft 365 como origen de datos
Aprenda a usar Microsoft Graph Search API para consultar contenido de Microsoft 365 como origen de datos de la aplicación RAG. Para obtener más información sobre Microsoft Graph Search API, puede hacer referencia a usar Microsoft Search API para buscar contenido de OneDrive y SharePoint.
Requisito previo: debe crear un cliente Graph API y concederle el ámbito de Files.Read.All permiso para acceder a archivos, carpetas, páginas y noticias de SharePoint y OneDrive.
Ingesta de datos
La API de búsqueda de Microsoft Graph, que puede buscar contenido de SharePoint, está disponible. Por lo tanto, solo debe asegurarse de que el documento se carga en SharePoint o OneDrive, sin necesidad de ingesta de datos adicional.
Nota:
El servidor de SharePoint indexa un archivo solo si su extensión de archivo aparece en la página Administrar tipos de archivo. Para obtener una lista completa de las extensiones de archivo admitidas, consulte las extensiones de nombre de archivo indizadas predeterminadas y los tipos de archivo analizados en SharePoint Server y SharePoint en Microsoft 365.
Implementación del origen de datos
A continuación se muestra un ejemplo de búsqueda de archivos de texto en SharePoint y OneDrive:
import {
DataSource,
Memory,
RenderedPromptSection,
Tokenizer,
} from "@microsoft/teams-ai";
import { TurnContext } from "botbuilder";
import { Client, ResponseType } from "@microsoft/microsoft-graph-client";
export class GraphApiSearchDataSource implements DataSource {
public readonly name = "my-datasource";
public readonly description =
"Searches the graph for documents related to the input";
public client: Client;
constructor(client: Client) {
this.client = client;
}
public async renderData(
context: TurnContext,
memory: Memory,
tokenizer: Tokenizer,
maxTokens: number
): Promise<RenderedPromptSection<string>> {
const input = memory.getValue("temp.input") as string;
const contentResults = [];
const response = await this.client.api("/search/query").post({
requests: [
{
entityTypes: ["driveItem"],
query: {
// Search for markdown files in the user's OneDrive and SharePoint
// The supported file types are listed here:
// https://learn.microsoft.com/sharepoint/technical-reference/default-crawled-file-name-extensions-and-parsed-file-types
queryString: `${input} filetype:txt`,
},
// This parameter is required only when searching with application permissions
// https://learn.microsoft.com/graph/search-concept-searchall
// region: "US",
},
],
});
for (const value of response?.value ?? []) {
for (const hitsContainer of value?.hitsContainers ?? []) {
contentResults.push(...(hitsContainer?.hits ?? []));
}
}
// Add documents until you run out of tokens
let length = 0,
output = "";
for (const result of contentResults) {
const rawContent = await this.downloadSharepointFile(
result.resource.webUrl
);
if (!rawContent) {
continue;
}
let doc = `${rawContent}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append do to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
// Download the file from SharePoint
// https://docs.microsoft.com/en-us/graph/api/driveitem-get-content
private async downloadSharepointFile(
contentUrl: string
): Promise<string | undefined> {
const encodedUrl = this.encodeSharepointContentUrl(contentUrl);
const fileContentResponse = await this.client
.api(`/shares/${encodedUrl}/driveItem/content`)
.responseType(ResponseType.TEXT)
.get();
return fileContentResponse;
}
private encodeSharepointContentUrl(webUrl: string): string {
const byteData = Buffer.from(webUrl, "utf-8");
const base64String = byteData.toString("base64");
return (
"u!" + base64String.replace("=", "").replace("/", "_").replace("+", "_")
);
}
}